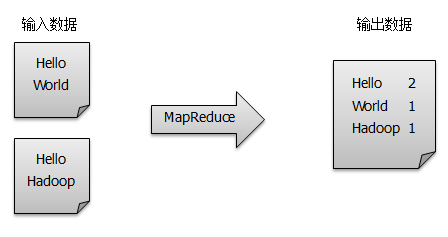
Word counting is one of the simplest and most thought-provoking programs of MapReduce, known as the MapReduce version of Hello World, whose complete code can be found in Hadoop Found in the src/example directory of the installation package.The main function of word count is to count the number of occurrences of each word in a series of text files, as shown in the following figure.This blog will help you understand the basic structure and running mechanism of the MapReduce program by analyzing the WordCount source code.
development environment
Hardware environment: CentOS 6.5 4 servers (one Master node and three Slave nodes)Software environment: Java 1.7.0_45, hadoop-1.2.1
1. Map process of WordCount
The Map process needs to inherit the Mapper class from the org.apache.hadoop.mapreduce package and override its map method.The value value in the Map method stores a row of records in the text file (marked by a carriage return), while the key value is the offset of the first character of the line from the first address of the text file.The StringTokenizer class then splits each line into a single word and2. Reeduce process of WordCount
The Reduce process inherits the Reduce class from the org.apache.hadoop.mapreduce package and overrides its reduce method.The input parameter key for the Reduce method is a single word, and values is a list of count values for the corresponding words on each Mapper, so you can get the total number of occurrences of a word by simply traversing the values and summing them.
The implementation code for the IntSumReducer class is as follows, with detailed source code referring to WordCount\src\WordCount.java.
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context
) throws IOException, InterruptedException {
//The input parameter key is a single word;
//The input parameter Iterable<IntWritable> values is a list of count values for the corresponding words on each Mapper.
int sum = 0;
for (IntWritable val : values) {//Traversal Sum
sum += val.get();
}
result.set(sum);
context.write(key, result);//Output <key, value>
}
}
3. Driven Execution Process of WordCount
In MapReduce, the Job object is responsible for managing and running a computing task, and some Job methods are used to set the parameters of the task.Here you set up the Map process using TokenizerMapper and the Combine and Reduce process using IntSumReducer.The output types of Map and Reduce processes are also set: key is Text and value is IntWritable.The input and output paths of the task are specified by command line parameters and are set by FileInputFormat and FileOutputFormat, respectively.Once you have finished setting the parameters for the corresponding task, you can call the job.waitForCompletion() method to execute the task.
The driver function implementation code is as follows, refer to WordCount\src\WordCount.java for details.
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
//Setting Mapper, Combiner, Reducer methods
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
//Set the output types of Map and Reduce processes, set the output type of key to Text, and set the output type of value to IntWritable.
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//Set the input and output paths of task data;
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
//Execute job task and exit after successful execution;
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
4. Processing of WordCount
WordCount's design ideas and source analysis process are given above, but many details are not mentioned. This section provides a more detailed explanation of WordCount based on MapReduce's processing project.Detailed execution steps are as follows:
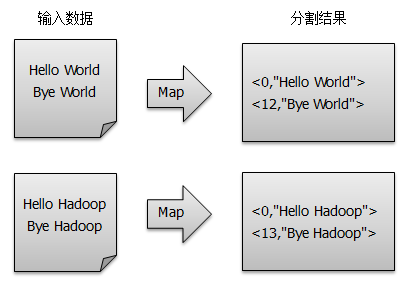
1) Split the files into splits. Because the files used for testing are small, each file is a split, and the files are split into < key, value > pairs by line, as shown in the figure.This step is automated by the MapReduce framework, where the offset (that is, the key value) includes the number of characters used by the carriage return character (which differs between Windows and Linux environments).
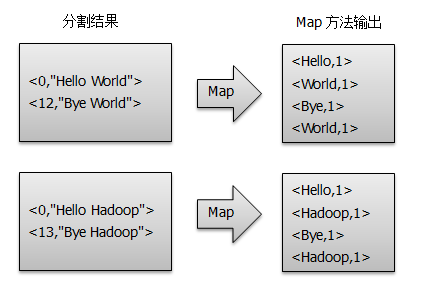
2) The split < key, value > processes the map method given to the user to generate a new < key, value > pair, as shown in the diagram:
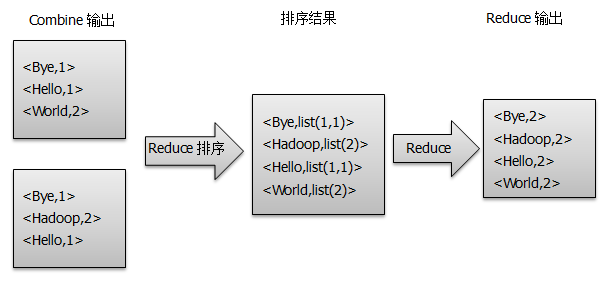
3) Once < key, value > of the map method output is obtained, Mapper will sort them by key value and perform the Combine process, adding up the same value of key to get the final output of Mapper as shown in the figure:
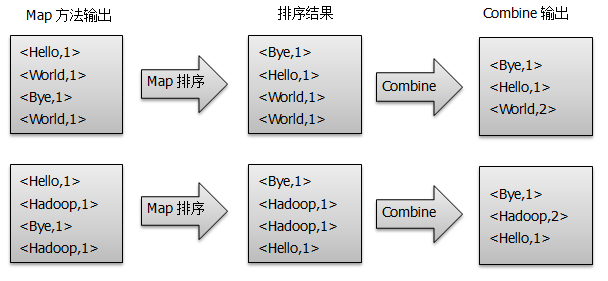
4) Reducer first sorts the data received from Mapper, and then handles it to a user-defined reducer method to get a new < key, value > pair, which is the output of WordCount as shown in the figure:
5. Minimum driver for WordCount
The MapReduce framework has done a lot behind the scenes. If you don't override the map and reduce methods, will it strike?A WordCount Minimum Driver MapReduce-LazyMapReduce is designed below, which only initializes tasks and sets the input/output paths necessary. The remaining parameters (such as input/output type, map method, reduce method, and so on) remain default.The implementation code for LazyMapReduce is as follows:
public class LazyMapReduce {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "LazyMapReduce");
//Set the input and output paths of task data;
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
//Execute job task and exit after successful execution;
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
You can see that by default, MapReduce will input as is
6. Deployment Run
1) Deployment Source
#Set up a working environment [hadoop@K-Master ~]$ mkdir -p /usr/hadoop/workspace/MapReduce #Deployment Source Copy the WordCount folder to / usr/hadoop/workspace/MapReduce/path;
...You can download WordCount directly
-------------------------------------------------------------------------------------------------------------
Free download address at http://linux.linuxidc.com/
Both username and password arewww.linuxidc.com
Specific download directory in/2015 materials/March/8/Hadoop introductory basic tutorials/
See Download Method http://www.linuxidc.com/Linux/2013-07/87684.htm
-------------------------------------------------------------------------------------------------------------
2) Compile files
When using the javac compilation command, two parameters are used: -classpath specifies the core package needed to compile the class, -d specifies the path to store the compiled class file, and finally WordCount.java indicates that the compiled object is the WordCount.java class in the current folder.
[hadoop@K-Master ~]$ cd /usr/hadoop/workspace/MapReduce/WordCount [hadoop@K-Master WordCount]$ javac -classpath /usr/hadoop/hadoop-core-1.2.1.jar:/usr/hadoop/lib/commons-cli-1.2.jar -d bin/ src/WordCount.java #View compilation results [hadoop@K-Master WordCount]$ ls bin/ -la //Total usage 12 drwxrwxr-x 2 hadoop hadoop 102 9 January 1511:08 . drwxrwxr-x 4 hadoop hadoop 69 9 January 15, 10:55 .. -rw-rw-r-- 1 hadoop hadoop 1830 9 January 1511:08 WordCount.class -rw-rw-r-- 1 hadoop hadoop 1739 9 January 1511:08 WordCount$IntSumReducer.class -rw-rw-r-- 1 hadoop hadoop 1736 9 January 1511:08 WordCount$TokenizerMapper.class
3) Packaging jar files
When packaging a class file using the jar command, we use two parameters: -cvf to package the class file and display detailed packaging information, -C to specify the object to be packaged, and'. 'at the end of the command to save the packaged generated file in the current directory.
[hadoop@K-Master WordCount]$ jar -cvf WordCount.jar -C bin/ . Added List Adding: WordCount$TokenizerMapper.class (input= 1736) (output= 754) (compressed 56%) Adding: WordCount$IntSumReducer.class (input= 1739) (output= 74)
Special note: The last character of the package command is'.', which means that the file WordCount.jar generated by the package is saved to the current folder, so be careful when entering the command.
4) Start Hadoop Cluster
If HDFS is already started, you do not need to execute the following command to see if HDFS is started through the jps command
[hadoop@K-Master WordCount]$ start-dfs.sh #Start HDFS file system [hadoop@K-Master WordCount]$ start-mapred.sh #Start the MapReducer service [hadoop@K-Master WordCount]$ jps 5082 JobTracker 4899 SecondaryNameNode 9048 Jps 4735 NameNode
5) Transfer incoming files to HDFS
In MapReduce, an application that is ready to submit for execution is called a Job, and the Master node divides the Job into several tasks that run on each computing node (Slave node), and the task input and output data are based on the HDFS distributed file management system, so the input data needs to be uploaded to the HDFS scoreAbove the distributed file management system, as shown below.
#Create Input/Output Folder on HDFS [hadoop@K-Master WordCount]$ hadoop fs -mkdir wordcount/input/ #Pass files from local files to the cluster's input directory [hadoop@K-Master WordCount]$ hadoop fs -put input/file0*.txt wordcount/input #View uploads to files in HDFS input folder [hadoop@K-Master WordCount]$ hadoop fs -ls wordcount/input Found 2 items -rw-r--r-- 1 hadoop supergroup 22 2014-07-12 19:50 /user/hadoop/wordcount/input/file01.txt -rw-r--r-- 1 hadoop supergroup 28 2014-07-12 19:50 /user/hadoop/wordcount/input/file02.txt
6) Run Jar files
We run a job task with the hadoop jar command, and the meanings of the parameters of the command are as follows:
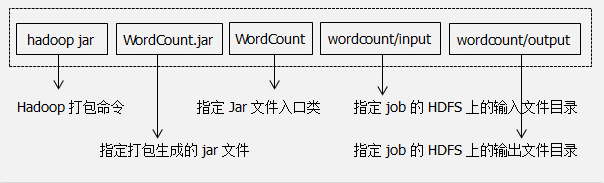
[hadoop@K-Master WordCount]$ hadoop jar WordCount.jar WordCount wordcount/input wordcount/output 14/07/12 22:06:42 INFO input.FileInputFormat: Total input paths to process : 2 14/07/12 22:06:42 INFO util.NativeCodeLoader: Loaded the native-hadoop library 14/07/12 22:06:42 WARN snappy.LoadSnappy: Snappy native library not loaded 14/07/12 22:06:42 INFO mapred.JobClient: Running job: job_201407121903_0004 14/07/12 22:06:43 INFO mapred.JobClient: map 0% reduce 0% 14/07/12 22:06:53 INFO mapred.JobClient: map 50% reduce 0% 14/07/12 22:06:55 INFO mapred.JobClient: map 100% reduce 0% 14/07/12 22:07:03 INFO mapred.JobClient: map 100% reduce 33% 14/07/12 22:07:05 INFO mapred.JobClient: map 100% reduce 100% 14/07/12 22:07:07 INFO mapred.JobClient: Job complete: job_201407121903_0004 14/07/12 22:07:07 INFO mapred.JobClient: Counters: 29
7) View the results
The result file generally consists of three parts:
1) _SUCCESS file: Indicates that MapReduce ran successfully.
2) The _logs folder: holds a log of the running MapReduce.
3) Part-r-00000 file: Stores the result, which is also the result file generated by default.
Use the Hadoop fs-ls wordcount/output command to view the output results directory as follows:
#View output directory contents on FS [hadoop@K-Master WordCount]$ hadoop fs -ls wordcount/output Found 3 items -rw-r--r-- 1 hadoop supergroup 0 2014-09-15 11:11 /user/hadoop/wordcount/output/_SUCCESS drwxr-xr-x - hadoop supergroup 0 2014-09-15 11:10 /user/hadoop/wordcount/output/_logs -rw-r--r-- 1 hadoop supergroup 41 2014-09-15 11:11 /user/hadoop/wordcount/output/part-r-00000 //Use the hadoop fs-cat wordcount/output/part-r-00000 command to view the output as follows: #View results output file content [hadoop@K-Master WordCount]$ hadoop fs -cat wordcount/output/part-r-00000 Bye 1 Goodbye 1 Hadoop 2 Hello 2 World 2
At this point, the quick start to the entire MapReduce is over.This article uses a complete case from development to deployment to viewing the results to give you an idea of the basic use of MapReduce.