There are two main methods of feature extraction, one is word bag model, and the other is TF-IDF Model( term frequency-inverse document frequency,Word frequency and reverse file frequency)
1. Word bag model
1.1 word bag and word set
There are two very important models for text feature extraction
Word set model: a set of words. Naturally, there can only be one element in the set, that is, there is only one word in the word set
Word bag model: Based on the word set, if a word appears more than once in the document, count the number of times it appears.
The difference between them is that word bags are the dimensions of frequency added on the basis of word sets. Word sets only focus on whether or not, and word bags also pay attention to how many times they appear.
1.2 practice
Now let's practice the word bag model:
First, import the related function library:
import pandas as pd from sklearn.feature_extraction.text import CountVectorizer
Import data
data = pd.read_csv("./dataset/Movies_dirty.csv")
data['Movie description'] = data.iloc[:,1]+' '+data.iloc[:,-1]#Merge two columns of data
Here, I use the movie dataset, including the name, director, year,..., description attributes of the movie. I only use the name and description attributes, and merge the two columns of data. If you can't find the relevant data, you can also experiment with a simple data set.
corpus = []
for i in data['Movie description']:
corpus.append(i)

Put the data into the list and display the part. A comma between two commas represents a piece of data.
Word bag model:
vectorizer = CountVectorizer(min_df=1) X = vectorizer.fit_transform(corpus) feature_names = vectorizer.get_feature_names_out() # print(feature_names,len(feature_names)) X_feature = X.toarray() print(X_feature,len(X_feature)) print(data.shape)
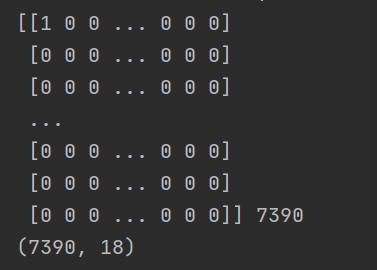
Full code:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
data = pd.read_csv("./dataset/Movies_dirty.csv")
data['Movie description'] = data.iloc[:,1]+' '+data.iloc[:,-1]
corpus = []
for i in data['Movie description']:
corpus.append(i)
print(corpus)
vectorizer = CountVectorizer(min_df=1)
X = vectorizer.fit_transform(corpus)
feature_names = vectorizer.get_feature_names_out()
# print(feature_names,len(feature_names))
X_feature = X.toarray()
print(X_feature,len(X_feature))
print(data.shape)
2,TF-IDF
2.1 TF-IDF description
TF-IDF is a statistical method used to evaluate the importance of a word to a document integration or a corpus.
The importance of a word increases in proportion to the number of times it appears in the file, but decreases in inverse proportion to the frequency of its appearance in the expected library.
Various forms of TF-IDF weighting are often used by search engines as a measure or rating of the correlation between files and user queries.
TF-IDF Main ideas of the project: How often does a word or phrase appear in an article TF(Term Frequency,Word frequency), word frequency is high, and it rarely appears in other articles, It is considered that this word or phrase has good classification ability and is suitable for classification.
TF-IDF is actually TF*IDF.
TF indicates the frequency of entries in documents. The main idea of IDF (inverter document frequency) is that if there are fewer documents containing entry T, that is, the fewer n, and the larger IDF, it indicates that entry t has a good ability to distinguish categories.
If the number of documents containing entry t in a certain type of document C is m, and the total number of documents containing T in other types is k, it is obvious that the number of documents containing T is n = m+k. when m is large, n is also large, and the IDF value obtained according to the IDF formula will be small, indicating that the ability to distinguish the category of entry t is not strong. But in fact, if an entry appears frequently in a class of documents, it indicates that the entry can well represent the characteristics of the text of this class. Such an entry should be given a higher weight and selected as the characteristic word of this class of documents to distinguish it from other classes of documents.
2.2 practice
TF-IDF algorithm is implemented in sklearn, and TfidfTransformer can be instantiated.
Import related libraries
from sklearn.feature_extraction.text import TfidfTransformer
transformer = TfidfTransformer(smooth_idf=False) tfidf = transformer.fit_transform(X_feature).toarray() print(tfidf,len(tfidf),len(tfidf[0]))
TF-IDF model is usually used together with word bag model to further process the array generated by word bag model.
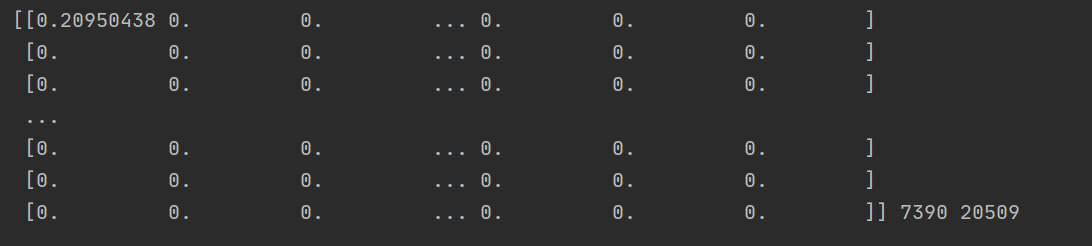
Finally, the complete code and the combination of word bag model and TF-IDF model are attached. The output characteristics are as follows:
"""
take movie of name and description merge
Using word bag model and TF-IDF Characterize
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer
data = pd.read_csv("./dataset/Movies_dirty.csv")
data['Movie description'] = data.iloc[:,1]+' '+data.iloc[:,-1]
corpus = []
for i in data['Movie description']:
corpus.append(i)
# print(corpus)
vectorizer = CountVectorizer(min_df=1)
transformer = TfidfTransformer(smooth_idf=False)
X = vectorizer.fit_transform(corpus)
feature_names = vectorizer.get_feature_names_out()
# print(feature_names,len(feature_names))
X_feature = X.toarray()
tfidf = transformer.fit_transform(X_feature).toarray()
print(X_feature,len(X_feature))
# print(data.shape)
print(tfidf,len(tfidf),len(tfidf[0]))
That's all for this study. I hope Xiao Zhang's blog can help the little partners in need!!