Thread pool: common problems of business code
In the program, we will use various pool optimization caches to create expensive objects, such as thread pool, connection pool and memory pool. Generally, some objects are created in advance and put into the pool. When they are used, they are directly taken out for use and returned for reuse. The number of cached objects in the pool will be adjusted through certain strategies to achieve dynamic scaling.
Because the creation of threads is expensive, creating a large number of threads arbitrarily and without control will cause performance problems. Therefore, short and fast tasks generally give priority to using thread pool instead of directly creating threads
1. The declaration of thread pool needs to be done manually
The Executors class in Java defines some quick tools and methods to help us quickly create a thread pool. Alibaba java development manual mentions that it is forbidden to use these methods to create thread pools, but new ThreadPoolExecutor should be used manually to create thread pools. Behind this rule are a large number of bloody production accidents. The most typical are newFixedThreadPool and newCachedThreadPool, which may lead to OOM problems due to resource depletion.
Alibaba documentation:

Test OOM issues:
- To initialize a single threaded FixedThreadPool and loop 100 million times to the thread pool
Hand in tasks. Each task will create a large string and sleep for an hour
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.UUID;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
@Slf4j
public class threadPooltest extends RecordLogApplicationTest {
/**
* Test OOM issues
*/
@Test
public void threadPooltest() throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(100000);
System.out.println("Start execution");
for (int i = 0; i < 100000000; i++) {
executorService.execute(() -> {
String payload = IntStream.rangeClosed(1, 1000000)
.mapToObj(__ -> "a").collect(Collectors.joining("")) + UUID.randomUUID().toString();
System.out.println("Wait an hour to start");
try {
TimeUnit.HOURS.sleep(1);
} catch (Exception e) {
log.info(payload);
}
});
}
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.HOURS);
}
}Result: java.lang.OutOfMemoryError error
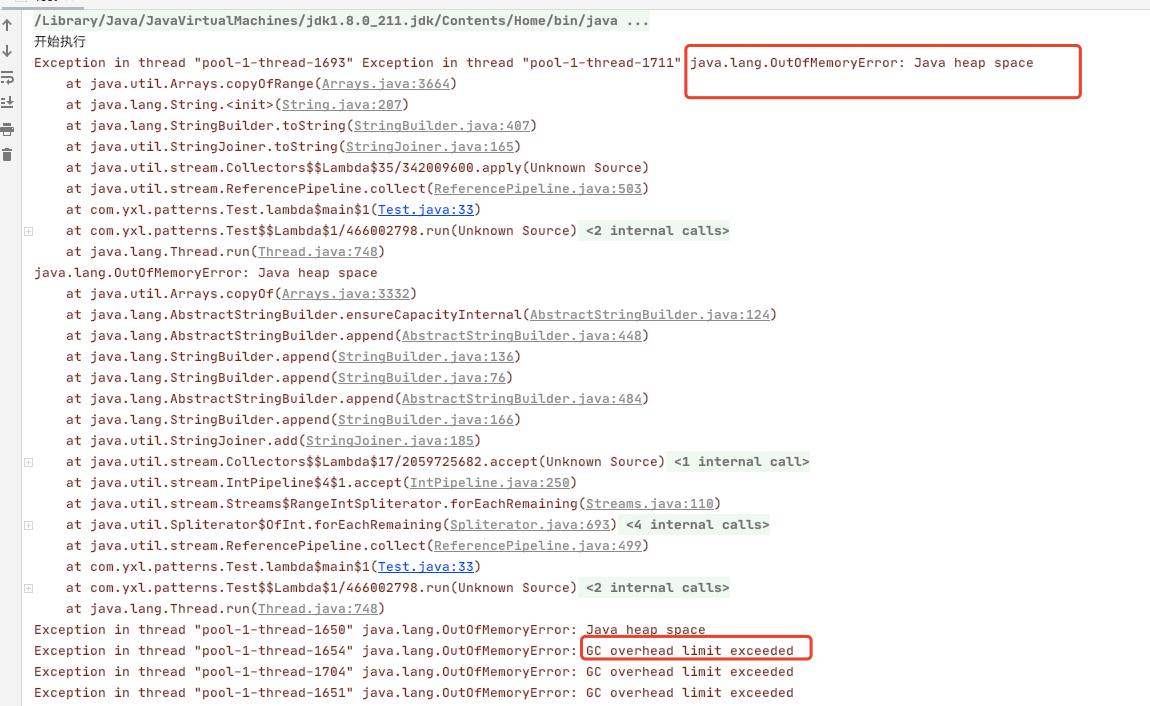
First, we look at the source code of the new fixedthreadpool method and find that the work queue of the thread pool directly creates a LinkedBlockingQueue,
/**
* Creates a thread pool that reuses a fixed number of threads
* operating off a shared unbounded queue. At any point, at most
* {@code nThreads} threads will be active processing tasks.
* If additional tasks are submitted when all threads are active,
* they will wait in the queue until a thread is available.
* If any thread terminates due to a failure during execution
* prior to shutdown, a new one will take its place if needed to
* execute subsequent tasks. The threads in the pool will exist
* until it is explicitly {@link ExecutorService#shutdown shutdown}.
*
* @param nThreads the number of threads in the pool
* @return the newly created thread pool
* @throws IllegalArgumentException if {@code nThreads <= 0}
*/
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}Click to see that the LinkedBlockingQueue construction method is an integer. Max_ The queue of value length can be considered unbounded
/**
* Creates a {@code LinkedBlockingQueue} with a capacity of
* {@link Integer#MAX_VALUE}.
*/
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}Although newFixedThreadPool can control a fixed number of worker threads, the task queue is unbounded. If there are many tasks and the execution is slow, but the queue may be quickly overstocked and burst the memory, resulting in OOM
Test newCachedThreadPool
If we change newFixedThreadPool to newCachedThreadPool method to get thread pool. Soon after the program runs, you will also see OOM exceptions
java.lang.OutOfMemoryError: unable to create new native thread
Source code:
/**
* Creates a thread pool that creates new threads as needed, but
* will reuse previously constructed threads when they are
* available, and uses the provided
* ThreadFactory to create new threads when needed.
* @param threadFactory the factory to use when creating new threads
* @return the newly created thread pool
* @throws NullPointerException if threadFactory is null
*/
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}The maximum number of threads in this thread pool is Integer.MAX_VALUE, which is considered as having no upper limit, can be considered as having no upper limit, and its work queue SynchronousQueue is a blocking queue without storage space. This means that as long as a request arrives, a worker thread must be found to process it. If there is no idle thread, a new one will be created. Since our tasks take one hour to complete, a large number of threads will be created after a large number of tasks come in. We know that threads allocate a certain memory space as a thread stack, such as 1MB. Therefore, unlimited thread creation will inevitably lead to OOM
We do not recommend using the two fast thread pools provided by Executors for the following reasons:
- We need to evaluate several core parameters of the thread pool according to our own scenarios and concurrency, including the number of core threads, the maximum number of threads, the thread recycling policy, the type of work queue, and the rejection policy, so as to ensure that the work behavior of the thread pool meets the requirements. Generally, we need to set a bounded work queue and a controllable number of threads.
- At any time, Yu genwei can specify an interesting name for the custom thread pool to facilitate troubleshooting. When the number of threads increases sharply, threads deadlock, threads occupy a lot of CPU, thread execution exceptions and other problems occur, we often grab the thread stack. At this time, meaningful thread names can facilitate us to locate the problem.
Summarize thread pool working behavior:
- If the number of threads in the current thread pool is less than corePoolSize, a thread will be created to execute each task;
- If the number of threads in the current thread pool > = corepoolsize, each task will try to add it to the task cache queue. If the addition is successful, the task will wait for the idle thread to take it out for execution; If the addition fails (generally speaking, the task cache queue is full), it will try to create a new thread to execute the task;
- If the queue is full, a new thread is created on the premise that the number of bus processes is not greater than maximumPoolSize
- If the number of threads in the current thread pool reaches maximumPoolSize, the task rejection policy will be adopted for processing;
- If the number of threads in the thread pool is greater than the corePoolSize, if the idle time of a thread exceeds keepAliveTime, the thread will be terminated until the number of threads in the thread pool is not greater than the corePoolSize; If it is allowed to set the survival time for threads in the core pool, threads in the core pool will be terminated if their idle time exceeds keepAliveTime.
2. Confirm whether the route pool is being reused
- In the production environment, the monitoring always gives an alarm that there are too many threads currently used, which will come down again later, but the current user access is not very large
Through code investigation, it is found that Executors.newCachedThreadPool() is used in the project; When creating a thread pool, we know that newCachedThreadPool will create as many threads as necessary. A business operation of business code will submit multiple slow tasks to the thread pool. In this way, multiple threads will be started when performing a business operation. If the amount of business operations is large, it is possible to start thousands of threads at once
Source code discovery
/**
* Creates a thread pool that creates new threads as needed, but
* will reuse previously constructed threads when they are
* available. These pools will typically improve the performance
* of programs that execute many short-lived asynchronous tasks.
* Calls to {@code execute} will reuse previously constructed
* threads if available. If no existing thread is available, a new
* thread will be created and added to the pool. Threads that have
* not been used for sixty seconds are terminated and removed from
* the cache. Thus, a pool that remains idle for long enough will
* not consume any resources. Note that pools with similar
* properties but different details (for example, timeout parameters)
* may be created using {@link ThreadPoolExecutor} constructors.
*
* @return the newly created thread pool
*/
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}- The number of core threads is 0, and the maximum number of threads is the maximum value of Integer. Generally speaking, the machine does not have so much memory for continuous use, while the keepAliveTime is 60 seconds, that is, all threads can be recycled after 60 seconds. The synchronous queue is used to load waiting tasks. This blocking queue has no storage space, which means that as long as a request comes, You must find a worker thread to handle it. If there is no idle thread at present, a new thread will be created.
Therefore, when using the thread pool, we should specify the core parameters of the thread pool according to the "priority" of the task, including the number of threads, recycling strategy and task queue:
: 1. For IO tasks with slow execution and small number, it may be necessary to consider more threads instead of too large queue
Columns.
2. For computing tasks with large throughput, the number of threads should not be too many, which can be CPU cores or cores * 2 (reason:
Therefore, the thread must be scheduled to a CPU for execution. If the task itself is a CPU bound task, it is too long
Multiple threads will only increase the overhead of thread switching and not improve throughput), but it may require a long queue to do so
Buffer.