1, Foreword
First, explain the MySQL version:
mysql> select version(); +-----------+ | version() | +-----------+ | 5.7.17 | +-----------+ 1 row in set (0.00 sec)
Table structure:
mysql> desc test; +--------+---------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+---------------------+------+-----+---------+----------------+ | id | bigint(20) unsigned | NO | PRI | NULL | auto_increment | | val | int(10) unsigned | NO | MUL | 0 | | | source | int(10) unsigned | NO | | 0 | | +--------+---------------------+------+-----+---------+----------------+ 3 rows in set (0.00 sec)
id is a self incrementing primary key, and val is a non unique index.
Inject a large amount of data, totaling 5 million:
mysql> select count(*) from test; +----------+ | count(*) | +----------+ | 5242882 | +----------+ 1 row in set (4.25 sec)
We know that when the offset in limit offset rows is large, efficiency problems will occur:
mysql> select * from test where val=4 limit 300000,5; +---------+-----+--------+ | id | val | source | +---------+-----+--------+ | 3327622 | 4 | 4 | | 3327632 | 4 | 4 | | 3327642 | 4 | 4 | | 3327652 | 4 | 4 | | 3327662 | 4 | 4 | +---------+-----+--------+ 5 rows in set (15.98 sec)
In order to achieve the same purpose, we will generally rewrite it into the following statement:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id; +---------+-----+--------+---------+ | id | val | source | id | +---------+-----+--------+---------+ | 3327622 | 4 | 4 | 3327622 | | 3327632 | 4 | 4 | 3327632 | | 3327642 | 4 | 4 | 3327642 | | 3327652 | 4 | 4 | 3327652 | | 3327662 | 4 | 4 | 3327662 | +---------+-----+--------+---------+ 5 rows in set (0.38 sec)
The time difference is obvious.
Why the above results? Let's look at select * from test where Val = 4, limit 300000,5; Query process:
Query leaf index node data. According to the primary key value on the leaf node, cluster all the field values required for query on the index.
Similar to the following figure:

Like the above, you need to query the index node for 300005 times, query the data of the cluster index for 300005 times, and finally filter out the first 300000 results and take out the last 5. MySQL consumes a lot of random I/O to query the data of cluster index, and the data queried by 300000 random I/O will not appear in the result set.
Some people will ask: since the index was used at the beginning, why not query the last five nodes along the index leaf node, and then query the actual data in the cluster index. In this way, only 5 random I / OS are required, which is similar to the process in the following picture:
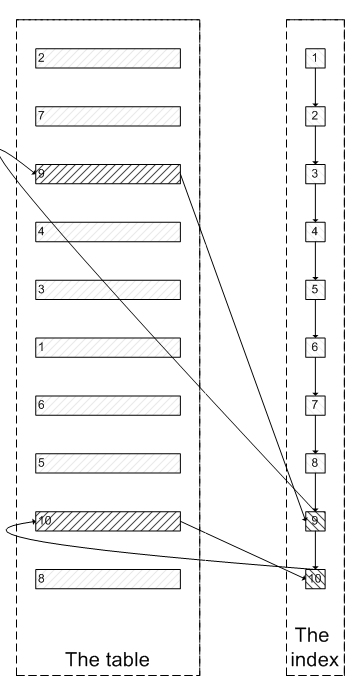
In fact, I also want to ask this question.
confirm
Let's confirm the above inference by practical operation:
In order to verify that select * from test where val=4 limit 300000,5 scans 300005 index nodes and 300005 data nodes on clustered indexes, we need to know whether MySQL can count the times of querying data nodes through index nodes in an sql. I tried handler first_ read_* Series, unfortunately, no variable can meet the condition.
I can only confirm it indirectly:
There is a buffer pool in InnoDB. There are recently accessed data pages, including data pages and index pages. Therefore, we need to run two sql to compare the number of data pages in the buffer pool. The prediction result is that after running select * from test a inner join (select id from test where Val = 4 limit 300000,5) b >, the number of data pages in the buffer pool is far less than that of select * from test where val=4 limit 300000,5; The corresponding quantity, because the previous sql only accesses the data page 5 times, and the latter sql accesses the data page 300005 times.
select * from test where val=4 limit 300000,5
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
Empty set (0.04 sec)It can be seen that there is no data page about the test table in the buffer pool at present.
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (26.19 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 4098 |
| val | 208 |
+------------+----------+
2 rows in set (0.04 sec)It can be seen that there are 4098 data pages and 208 index pages about the test table in the buffer pool.