What is the generation of confrontation networks? Generative Countermeasure Network( GAN Generative Adversarial Networks is Deep learning The model is based on the complex distribution in recent years. Unsupervised learning One of the most promising methods. The model consists of at least two modules in the framework: Generative Model and Discriminative Model. Play a game Learning produces fairly good output. In the original GAN theory, both G and D are not required to be neural networks, only if the corresponding generated and discriminated functions can be fitted. But in practice, deep neural networks are generally used as G and D. A good GAN application needs a good training method, otherwise the output may be unsatisfactory due to the freedom of the neural network model.
A typical model of generating antagonistic networks looks like this:
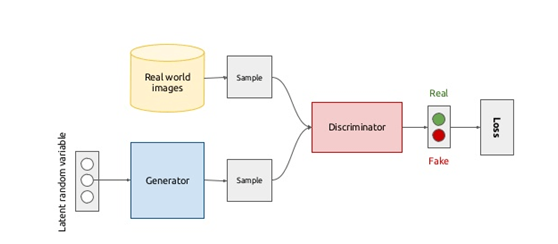
Let's first understand what GAN's two models need to do.
First of all, the discriminant model is the network of the right half of the graph. Visually, it is a simple neural network structure. Input is an image, and output is a probability value, which is used to judge whether true or false is used (probability value is greater than 0.5, that is true or less than 0.5, that is false), and whether true or false is only a probability defined by people. Already.
Secondly, the model is generated. What is the model to do? It can also be regarded as a neural network model. The input is a set of random numbers Z, and the output is an image, not a numerical value. As can be seen from the graph, there will be two data sets, one is real data set, which is good to say, the other is false data set, which is the data set generated by the generated network. Well, according to this figure, let's understand what GAN's goal is to do:
The purpose of discriminant network is to distinguish whether a graph belongs to a real sample set or a false sample set. If the input is true sample, the network output is close to 1, the input is false sample, and the network output is close to 0, then it is perfect and achieves the purpose of good discrimination.
The purpose of generating the network is to make samples. The purpose of generating the network is to make the ability of making samples as strong as possible and to what extent. You can't judge whether I am a real sample or a false sample by judging the network.
Therefore, the function of identifying the network is to identify the data generated by noise as false and the real data as true.
The loss function of generating network is to make the result of distinguishing the noise data after distinguishing the network true, so as to achieve the purpose of generating the real image.
This is also the difficulty of generating confrontation network. Understanding this, the whole generation of confrontation network model will understand.
- Working mode
The general workflow is simple and straightforward:
1. Sample a minibatch of training samples and calculate their discriminator scores.
2. Get a generated sample minibatch, and then calculate their discriminator scores.
3. Use the gradients accumulated by these two steps to perform an update.
The next trick is to avoid using sparse gradients, especially in generators. Simply replace specific layers with their corresponding "smooth" similar layers, such as:
1. Replace ReLU with Leaky ReLU
2. Maximum pooling is replaced by average pooling, convolution + stride
3.Unpooling is replaced by deconvolution
Two main network models are generator model and discriminator model.
Discriminator model distinguishes two kinds of data sources, one is real data, the other is data generated by generator. Here we can divide it into two discriminator models and set reuse=True to share model parameters.
2. Code
import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from tensorflow.examples.tutorials.mnist import input_data # TODO: Data preparation mnist = input_data.read_data_sets('data') # TODO: Get input data def get_inputs(noise_dim, image_height, image_width, image_depth): # Real data inputs_real = tf.placeholder(tf.float32, [None, image_height, image_width, image_depth], name='inputs_real') # Noise data inputs_noise = tf.placeholder(tf.float32, [None, noise_dim], name='inputs_noise') return inputs_real, inputs_noise # TODO: Generator def get_generator(noise_img, output_dim, is_train=True, alpha=0.01): with tf.variable_scope("generator", reuse=(not is_train)): # 100 x 1 to 4 x 4 x 512 # Full Connection Layer layer1 = tf.layers.dense(noise_img, 4 * 4 * 512) layer1 = tf.reshape(layer1, [-1, 4, 4, 512]) # batch normalization layer1 = tf.layers.batch_normalization(layer1, training=is_train) # Leaky ReLU layer1 = tf.maximum(alpha * layer1, layer1) # dropout layer1 = tf.nn.dropout(layer1, keep_prob=0.8) # 4 x 4 x 512 to 7 x 7 x 256 layer2 = tf.layers.conv2d_transpose(layer1, 256, 4, strides=1, padding='valid') layer2 = tf.layers.batch_normalization(layer2, training=is_train) layer2 = tf.maximum(alpha * layer2, layer2) layer2 = tf.nn.dropout(layer2, keep_prob=0.8) # 7 x 7 256 to 14 x 14 x 128 layer3 = tf.layers.conv2d_transpose(layer2, 128, 3, strides=2, padding='same') layer3 = tf.layers.batch_normalization(layer3, training=is_train) layer3 = tf.maximum(alpha * layer3, layer3) layer3 = tf.nn.dropout(layer3, keep_prob=0.8) # 14 x 14 x 128 to 28 x 28 x 1 logits = tf.layers.conv2d_transpose(layer3, output_dim, 3, strides=2, padding='same') # The pixel range of the original MNIST dataset is 0-1, and the range of generated pictures is (-1,1). # So in training, remember to resize the MNIST pixel range outputs = tf.tanh(logits) return outputs # TODO: Discriminator def get_discriminator(inputs_img, reuse=False, alpha=0.01): with tf.variable_scope("discriminator", reuse=reuse): # 28 x 28 x 1 to 14 x 14 x 128 # Layer 1 does not add BN layer1 = tf.layers.conv2d(inputs_img, 128, 3, strides=2, padding='same') layer1 = tf.maximum(alpha * layer1, layer1) layer1 = tf.nn.dropout(layer1, keep_prob=0.8) # 14 x 14 x 128 to 7 x 7 x 256 layer2 = tf.layers.conv2d(layer1, 256, 3, strides=2, padding='same') layer2 = tf.layers.batch_normalization(layer2, training=True) layer2 = tf.maximum(alpha * layer2, layer2) layer2 = tf.nn.dropout(layer2, keep_prob=0.8) # 7 x 7 x 256 to 4 x 4 x 512 layer3 = tf.layers.conv2d(layer2, 512, 3, strides=2, padding='same') layer3 = tf.layers.batch_normalization(layer3, training=True) layer3 = tf.maximum(alpha * layer3, layer3) layer3 = tf.nn.dropout(layer3, keep_prob=0.8) # 4 x 4 x 512 to 4*4*512 x 1 flatten = tf.reshape(layer3, (-1, 4 * 4 * 512)) logits = tf.layers.dense(flatten, 1) outputs = tf.sigmoid(logits) return logits, outputs # TODO: Objective Function def get_loss(inputs_real, inputs_noise, image_depth, smooth=0.1): g_outputs = get_generator(inputs_noise, image_depth, is_train=True) d_logits_real, d_outputs_real = get_discriminator(inputs_real) d_logits_fake, d_outputs_fake = get_discriminator(g_outputs, reuse=True) # Computing Loss g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,labels=tf.ones_like(d_outputs_fake) * (1 - smooth))) d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real,labels=tf.ones_like(d_outputs_real) * (1 - smooth))) d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,labels=tf.zeros_like(d_outputs_fake))) d_loss = tf.add(d_loss_real, d_loss_fake) return g_loss, d_loss # TODO: Optimizer def get_optimizer(g_loss, d_loss, learning_rate=0.001): train_vars = tf.trainable_variables() g_vars = [var for var in train_vars if var.name.startswith("generator")] d_vars = [var for var in train_vars if var.name.startswith("discriminator")] # Optimizer with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)): g_opt = tf.train.AdamOptimizer(learning_rate).minimize(g_loss, var_list=g_vars) d_opt = tf.train.AdamOptimizer(learning_rate).minimize(d_loss, var_list=d_vars) return g_opt, d_opt # display picture def plot_images(samples): fig, axes = plt.subplots(nrows=5, ncols=5, sharex=True, sharey=True, figsize=(7, 7)) for img, ax in zip(samples, axes.flatten()): ax.imshow(img.reshape((28, 28)), cmap='Greys_r') ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) fig.tight_layout(pad=0) plt.show() def show_generator_output(sess, n_images, inputs_noise, output_dim): noise_shape = inputs_noise.get_shape().as_list()[-1] # Generating Noise Pictures examples_noise = np.random.uniform(-1, 1, size=[n_images, noise_shape]) samples = sess.run(get_generator(inputs_noise, output_dim, False), feed_dict={inputs_noise: examples_noise}) result = np.squeeze(samples, -1) return result # TODO: Start training # Define parameters batch_size = 64 noise_size = 100 epochs = 5 n_samples = 25 learning_rate = 0.001 def train(noise_size, data_shape, batch_size, n_samples): # Storage loss losses = [] steps = 0 inputs_real, inputs_noise = get_inputs(noise_size, data_shape[1], data_shape[2], data_shape[3]) g_loss, d_loss = get_loss(inputs_real, inputs_noise, data_shape[-1]) print("FUNCTION READY!!") g_train_opt, d_train_opt = get_optimizer(g_loss, d_loss, learning_rate) print("TRAINING....") with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # Iterative epoch for e in range(epochs): for batch_i in range(mnist.train.num_examples // batch_size): steps += 1 batch = mnist.train.next_batch(batch_size) batch_images = batch[0].reshape((batch_size, data_shape[1], data_shape[2], data_shape[3])) # scale to -1, 1 batch_images = batch_images * 2 - 1 # noise batch_noise = np.random.uniform(-1, 1, size=(batch_size, noise_size)) # run optimizer sess.run(g_train_opt, feed_dict={inputs_real: batch_images, inputs_noise: batch_noise}) sess.run(d_train_opt, feed_dict={inputs_real: batch_images, inputs_noise: batch_noise}) if steps % 101 == 0: train_loss_d = d_loss.eval({inputs_real: batch_images, inputs_noise: batch_noise}) train_loss_g = g_loss.eval({inputs_real: batch_images, inputs_noise: batch_noise}) losses.append((train_loss_d, train_loss_g)) print("Epoch {}/{}....".format(e + 1, epochs), "Discriminator Loss: {:.4f}....".format(train_loss_d), "Generator Loss: {:.4f}....".format(train_loss_g)) if e % 1 == 0: # display picture samples = show_generator_output(sess, n_samples, inputs_noise, data_shape[-1]) plot_images(samples) with tf.Graph().as_default(): train(noise_size, [-1, 28, 28, 1], batch_size, n_samples) print("OPTIMIZER END!!")