Don't say much about the description. Go directly to the figure above:

See the output? Why is the time difference between the first time and the second time so much? Let's think about it together. We can also look at the conclusion first and then look back at the analysis
Note: not only the second time, but every time after the first time
Give conjecture
- Is it related to operating system warm-up?
- Is it related to JIT (just in time compilation)?
- Is it related to ClassLoader class loading?
- Whether it is related to Lambda is not a foreach issue
Verify conjecture
Operating system warm-up
The concept of operating system preheating is the conclusion I got from consulting a big man. I didn't find the corresponding words in Baidu / Google, but in the simulation test, I tested it by ordinary traversal:

Basically, the speed of the first few times is slower and the speed of the later times is faster. Therefore, this factor may affect it, but the gap is not large. Therefore, this conclusion can not be used as the answer to the question.
JIT instant compilation
First, let's introduce JIT instant compilation:
After the initialization of the JVM is completed, during the calling and execution of the class, the execution engine will convert the bytecode into machine code, and then it can be executed in the operating system. In the process of converting bytecode into machine code, there is also a compilation in the virtual machine, that is, instant compilation.
Initially, the bytecode in the JVM is compiled by the Interpreter. When the virtual machine finds that a method or code block runs particularly frequently, it will recognize these codes as hot code.
In order to improve the execution efficiency of hot codes, the Just In Time compiler (JIT) will compile these codes into machine codes related to the local platform, optimize them at all levels, and then save them in memory
Another concept, back edge counter
The edge back counter is used to count the execution times of the loop body code in a method. The instruction that jumps after the control flow direction is encountered in the bytecode is called "Back Edge"
The main purpose of establishing the back edge counter is to trigger OSR (on stack replacement) compilation, that is, compilation on the stack. In some code segments with long cycle cycles, when the cycle reaches the back edge counter threshold, the JVM will consider this segment as hot code, and the JIT compiler will compile this segment of code into machine language and cache it. During this cycle period, It will directly replace the execution code and execute the cached machine language
From the above concepts, we can draw a conclusion: the first so-called operating system preheating probability is incorrect, because the ordinary traversal method is executed N times, and the subsequent execution time is relatively small, which is likely caused by JIT.
Is JIT real-time compilation the final answer? We tried to turn off the JIT to test it. Through querying the data, we found the following contents:
Procedure
- Use the - D option on the JVM command line to set the java.compiler Property to none or the empty string. Type the following command at a shell or command prompt: Java - DJava. Compiler = none < class > copy code
Note: this paragraph is from the official data of IBM. See < harvest >, let's not stop thinking
By configuring the IDEA JVM parameters:

The code test results in the execution problem are as follows:
# Before disabling foreach time one: 38 Split line... foreach time two: 1 # After disabling foreach time one: 40 Split line... foreach time two: 5
I have tested it many times and the results are very similar, so I can get another conclusion: JIT is not the cause of the problem (but it can improve execution efficiency)
Is it related to class loading?
During class loading verification, I still can't give up JIT. Therefore, after consulting a lot of materials, I know that a command can view the time-consuming situation of JIT compilation. The command is as follows:
java -XX:+CITime com.code.jvm.preheat.Demo >> log.txt
Explain the meaning of the order
# Directory of execution C:\Users\Kerwin\Desktop\Codes\Kerwin-Code-Study\target\classes> # Command meaning: prints time spend in JIT compiler. (introduced in 1.4.0.) # Print the time consumed by JIT compilation -XX:+CITime # Represents the class I specified com.code.jvm.preheat.Demo # Output to log.txt file for easy viewing >> log.txt
Show the whole content of a result:
foreach time one: 35
Split line...
foreach time two: 1
Accumulated compiler times (for compiled methods only)
------------------------------------------------
Total compilation time : 0.044 s
Standard compilation : 0.041 s, Average : 0.000
On stack replacement : 0.003 s, Average : 0.002
Detailed C1 Timings
Setup time: 0.000 s ( 0.0%)
Build IR: 0.010 s (38.8%)
Optimize: 0.001 s ( 2.3%)
RCE: 0.000 s ( 0.7%)
Emit LIR: 0.010 s (40.7%)
LIR Gen: 0.002 s ( 9.3%)
Linear Scan: 0.008 s (31.0%)
LIR Schedule: 0.000 s ( 0.0%)
Code Emission: 0.003 s (12.4%)
Code Installation: 0.002 s ( 8.2%)
Instruction Nodes: 9170 nodes
Total compiled methods : 162 methods
Standard compilation : 160 methods
On stack replacement : 2 methods
Total compiled bytecodes : 13885 bytes
Standard compilation : 13539 bytes
On stack replacement : 346 bytes
Average compilation speed: 312157 bytes/s
nmethod code size : 168352 bytes
nmethod total size : 276856 bytesThe test results are as follows:
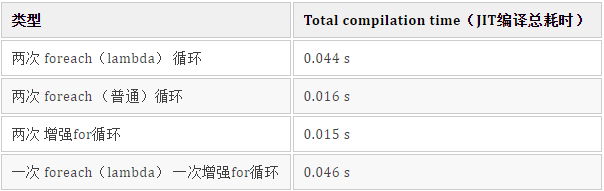
Through the above test results, it further illustrates a problem: as long as Lambda participates in the program, the compilation time is always longer
Again, by querying the data, we learned about the new command
java -verbose:class -verbose:jni -verbose:gc -XX:+PrintCompilation com.code.jvm.preheat.Demo
Explain the meaning of the order
# Output information about the jvm load class -verbose:class # Output information about native method calls -verbose:jni # Output relevant information of each GC -verbose:gc # Print relevant information when a method is compiled -XX:+PrintCompilation
Execute the commands for the with and without Lambda respectively, and the results are as follows:
In terms of log file size, there is a difference of more than ten kb
Note: the file is too large and only part of the content is displayed
# Including Lambda [Loaded java.lang.invoke.LambdaMetafactory from D:\JDK\jre1.8\lib\rt.jar] # A lot of content is omitted in the middle, and lambda Metafactory is the most obvious difference (only from the name) [Loaded java.lang.invoke.InnerClassLambdaMetafactory$1 from D:\JDK\jre1.8\lib\rt.jar] 5143 220 4 java.lang.String::equals (81 bytes) [Loaded java.lang.invoke.LambdaForm$MH/471910020 from java.lang.invoke.LambdaForm] 5143 219 3 jdk.internal.org.objectweb.asm.ByteVector::<init> (13 bytes) [Loaded java.lang.invoke.LambdaForm$MH/531885035 from java.lang.invoke.LambdaForm] 5143 222 3 jdk.internal.org.objectweb.asm.ByteVector::putInt (74 bytes) 5143 224 3 com.code.jvm.preheat.Demo$$Lambda$1/834600351::accept (8 bytes) 5143 225 3 com.code.jvm.preheat.Demo::lambda$getTime$0 (6 bytes) 5144 226 4 com.code.jvm.preheat.Demo$$Lambda$1/834600351::accept (8 bytes) 5144 223 1 java.lang.Integer::intValue (5 bytes) 5144 221 3 jdk.internal.org.objectweb.asm.ByteVector::putByteArray (49 bytes) 5144 224 3 com.code.jvm.preheat.Demo$$Lambda$1/834600351::accept (8 bytes) made not entrant 5145 227 % 4 java.util.ArrayList::forEach @ 27 (75 bytes) 5146 3 3 java.lang.String::equals (81 bytes) made not entrant foreach time one: 50 Split line... 5147 227 % 4 java.util.ArrayList::forEach @ -2 (75 bytes) made not entrant foreach time two: 1 [Loaded java.lang.Shutdown from D:\JDK\jre1.8\lib\rt.jar] [Loaded java.lang.Shutdown$Lock from D:\JDK\jre1.8\lib\rt.jar] # Lambda not included 5095 45 1 java.util.ArrayList::access$100 (5 bytes) 5095 46 1 java.lang.Integer::intValue (5 bytes) 5096 47 3 java.util.ArrayList$Itr::hasNext (20 bytes) 5096 49 3 java.util.ArrayList$Itr::checkForComodification (23 bytes) 5096 48 3 java.util.ArrayList$Itr::next (66 bytes) 5096 50 4 java.util.ArrayList$Itr::hasNext (20 bytes) 5096 51 4 java.util.ArrayList$Itr::checkForComodification (23 bytes) 5096 52 4 java.util.ArrayList$Itr::next (66 bytes) 5097 47 3 java.util.ArrayList$Itr::hasNext (20 bytes) made not entrant 5097 49 3 java.util.ArrayList$Itr::checkForComodification (23 bytes) made not entrant 5097 48 3 java.util.ArrayList$Itr::next (66 bytes) made not entrant 5099 53 % 4 com.code.jvm.preheat.Demo::getTimeFor @ 11 (47 bytes) 5101 50 4 java.util.ArrayList$Itr::hasNext (20 bytes) made not entrant foreach time one: 7 Split line... 5102 54 3 java.util.ArrayList$Itr::hasNext (20 bytes) 5102 55 4 java.util.ArrayList$Itr::hasNext (20 bytes) 5103 53 % 4 com.code.jvm.preheat.Demo::getTimeFor @ -2 (47 bytes) made not entrant foreach time two: 1 5103 54 3 java.util.ArrayList$Itr::hasNext (20 bytes) made not entrant [Loaded java.lang.Shutdown from D:\JDK\jre1.8\lib\rt.jar] [Loaded java.lang.Shutdown$Lock from D:\JDK\jre1.8\lib\rt.jar]
We can find two conclusions in combination with JIT compilation time and JVM loading class logs:
- If Lambda is used, the JVM will load LambdaMetafactory class additionally, which takes a long time
- When the Lambda method is called the second time, the JVM no longer needs to load the LambdaMetafactory class, so it performs faster
It perfectly confirms the question raised before: why is foreach slow for the first time and fast in the future, but is this the truth? Let's keep looking down
Eliminate interference from foreach
Let's first look at the implementation of foreach method in ArrayList:
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}At first glance, it seems nothing special. Let's try to define the Consumer in advance. The code is as follows:

It can be found that the speed is very fast. Check the JIT compilation time and class loading. It is found that the time is short and there is no LambdaMetafactory loading
According to the conclusion just obtained, let's try to define Consumer in the form of Lambda
Consumer consumer = o -> {
int curr = (int) o;
};
# Time consuming execution results
foreach time: 3Let's take a look at the compilation time and class loading. We are surprised to find that JIT compilation takes a long time and LambdaMetafactory is loaded
Re explore the implementation principle of Lambda
For the details of the implementation principle of Lambda expression, I will publish a new article later. Let's talk about the conclusion today:
- The anonymous inner class will have one more class at the compilation stage, but Lambda will not. It will only generate one more function
- This function will generate a class through LambdaMetafactory factory in the running phase for subsequent calls
Why is Lamdba implemented like this?
Anonymous inner classes have some defects:
- The compiler generates a new class file for each anonymous internal class. It is not advisable to generate many class files, because each class file needs to be loaded and verified before use, which will affect the startup performance of the application. Loading may be an expensive operation, including disk I/O and decompressing the JAR file itself.
- If lambdas are converted to anonymous inner classes, each lambda has a new class file. Since each anonymous inner class will be loaded, it will occupy the meta space of the JVM. If the JVM compiles the code in each such anonymous inner class into machine code, it will be stored in the code cache.
- In addition, these anonymous inner classes will be instantiated as separate objects. Therefore, anonymous inner classes will increase the memory consumption of the application.
- Most importantly, choosing to implement lambdas using anonymous inner classes from the beginning will limit the scope of future lambda implementation changes and their ability to evolve based on future JVM improvements.
truth
After understanding the implementation principle of anonymous internal classes and Lambda expressions, I am even more confused about the reason why Lambda takes a long time. After all, the time difference between generating a new Class from an anonymous internal Class and generating a new method from Lambda is not too much. Then there is also Class generation during operation, and the time consumption should not be too different. What is the problem?
Finally, we found the answer by querying the data:
You are obviously encountering the first-time initialization overhead of lambda expressions. As already mentioned in the comments, the classes for lambda expressions are generated at runtime rather than being loaded from your class path.
However, being generated isn't the cause for the slowdown. After all, generating a class having a simple structure can be even faster than loading the same bytes from an external source. And the inner class has to be loaded too. But when the application hasn't used lambda expressions before, even the framework for generating the lambda classes has to be loaded (Oracle's current implementation uses ASM under the hood). This is the actual cause of the slowdown, loading and initialization of a dozen internally used classes, not the lambda expression itself.
Roughly translated as follows:
Obviously, you encounter the first initialization overhead of a lambda expression. As already mentioned in the comments, the classes of lambda expressions are generated at run time, not loaded from the classpath.
However, generating classes is not the reason for the slowdown. After all, generating a simple analogy is faster than loading the same bytes from an external source. Inner classes must also be loaded. However, when an application has not previously used lambda expressions, it even has to load the framework for generating lambda classes (Oracle's current implementation uses ASM behind the scenes). This is the real reason why more than a dozen internally used classes (rather than lambda expressions themselves) slow down, load, and initialize.
Truth: when an application uses Lambda for the first time, it must load the framework for generating Lambda classes, so it needs more compilation and loading time
Looking back at the class loading log, I found the introduction of ASM framework:
[Loaded jdk.internal.org.objectweb.asm.ClassVisitor from F:\Java_JDK\JDK1.8\jre\lib\rt.jar] [Loaded jdk.internal.org.objectweb.asm.ClassWriter from F:\Java_JDK\JDK1.8\jre\lib\rt.jar] [Loaded jdk.internal.org.objectweb.asm.ByteVector from F:\Java_JDK\JDK1.8\jre\lib\rt.jar] [Loaded jdk.internal.org.objectweb.asm.Item from F:\Java_JDK\JDK1.8\jre\lib\rt.jar] [Loaded jdk.internal.org.objectweb.asm.MethodVisitor from F:\Java_JDK\JDK1.8\jre\lib\rt.jar] [Loaded jdk.internal.org.objectweb.asm.MethodWriter from F:\Java_JDK\JDK1.8\jre\lib\rt.jar] [Loaded jdk.internal.org.objectweb.asm.Type from F:\Java_JDK\JDK1.8\jre\lib\rt.jar] [Loaded jdk.internal.org.objectweb.asm.Label from F:\Java_JDK\JDK1.8\jre\lib\rt.jar] [Loaded jdk.internal.org.objectweb.asm.Frame from F:\Java_JDK\JDK1.8\jre\lib\rt.jar] [Loaded jdk.internal.org.objectweb.asm.AnnotationVisitor from F:\Java_JDK\JDK1.8\jre\lib\rt.jar] [Loaded jdk.internal.org.objectweb.asm.AnnotationWriter from F:\Java_JDK\JDK1.8\jre\lib\rt.jar]
conclusion
- The culprit causing abnormal data in foreach test is Lambda expression
- When Lambda expressions are used for the first time in an application, the ASM framework needs to be loaded additionally, so it needs more compilation and loading time
- The underlying implementation of Lambda expression is not the syntax sugar of anonymous inner class, but its optimized version
- In fact, the underlying implementation of foreach is not fundamentally different from the enhanced for loop. One is an external iterator and the other is an internal iterator
- Through foreach + Lambda, the efficiency is not low, but it needs to be preheated in advance (loading the frame) Hope to help you!