I believe many small partners have added many methods with native under the Java lang package to represent the Java local interface, which is used to call the methods of the operating system, such as the hashcode method under the Java root class Object. The specific implementation of native method is implemented in C language, because jdk is written in C language. When there are some methods that need to deal with hardware, java can't do it, so it declares a native method and asks C to write a method to deal with hardware. After C is written, java can call it directly.
/**
* Returns a hash code value for the object. This method is
* supported for the benefit of hash tables such as those provided by
* {@link java.util.HashMap}.
* <p>
* The general contract of {@code hashCode} is:
* <ul>
* <li>Whenever it is invoked on the same object more than once during
* an execution of a Java application, the {@code hashCode} method
* must consistently return the same integer, provided no information
* used in {@code equals} comparisons on the object is modified.
* This integer need not remain consistent from one execution of an
* application to another execution of the same application.
* <li>If two objects are equal according to the {@code equals(Object)}
* method, then calling the {@code hashCode} method on each of
* the two objects must produce the same integer result.
* <li>It is <em>not</em> required that if two objects are unequal
* according to the {@link java.lang.Object#equals(java.lang.Object)}
* method, then calling the {@code hashCode} method on each of the
* two objects must produce distinct integer results. However, the
* programmer should be aware that producing distinct integer results
* for unequal objects may improve the performance of hash tables.
* </ul>
* <p>
* As much as is reasonably practical, the hashCode method defined by
* class {@code Object} does return distinct integers for distinct
* objects.
* (This is typically implemented by converting the internal
* address of the object into an integer, but this implementation
* technique is not required by the
* Java™ programming language.)By default, the hash code of an object is the internal address of the object*
* Converted to an integer.
*
* @return a hash code value for this object.
* @see java.lang.Object#equals(java.lang.Object)
* @see java.lang.System#identityHashCode
*/
public native int hashCode();This method returns the hash code of the object, which is mainly used in the hash table, such as HashMap in JDK.
The general convention of hash code is as follows:
- During the execution of a java program, on the premise that an object has not been changed, the hashCode method will return the same integer value no matter how many times the object is called. It is not necessary to keep the same value in different programs.
- If two objects are compared using the equals method and are the same, the hashCode method values of the two objects must also be equal.
- If two objects are not equal according to the equals method, the hashCode values of the two objects do not need to be different. However, if the hashCode values of unequal objects are different, the performance of hash table can be improved.
Generally, different objects produce different hash codes. By default, the hash code of an object is realized by converting the internal address of the object into an integer.
How should we view the source code? The method of native modification is written in non java language. There is no way to click directly to view it. Today, I will demonstrate how to view the native method in java.
At present, we can see that the JVM source code is the OpenJDK source code. Most of the OpenJDK source code is consistent with the Oracle JVM source code.
1. Download openjdk source code, openjdk project
Link: OpenJDK Mercurial Repositories(http://hg.openjdk.java.net/ ), as shown in the figure below
2. Choose jdk8u,openJDK8u60
3. Click the "browse" link

4. Click the "zip" link in the figure Download and start our source code journey.
5. Open the open JDK folder and jump to the directory jdk/src/share/native /.
Locate the Object.c file under the directory java\lang according to the package path of java.lang.Object.

Direct view address: http://hg.openjdk.java.net/jdk8u/jdk8u60/jdk/file/935758609767/src/share/native/java/lang
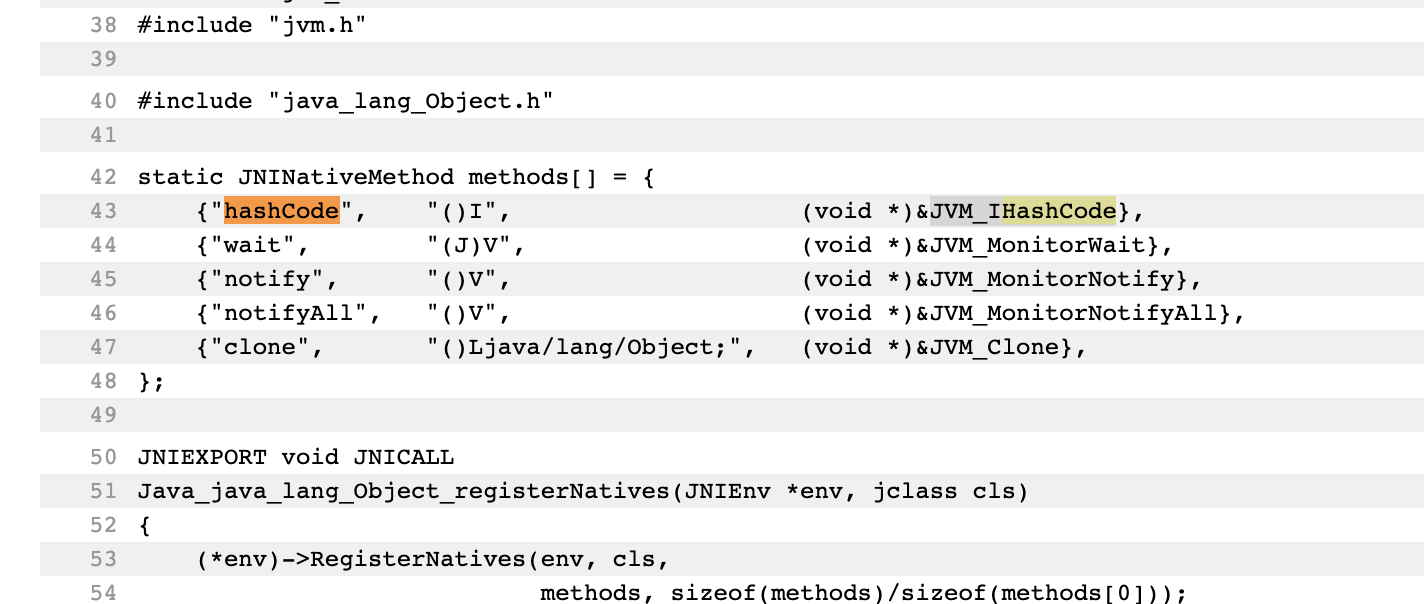
Found: JVM_IHashCode. Currently, OpenJDK defines hashCode in src/share/vm/prims/jvm.h and src/share/vm/prims/jvm.cpp
So far, we speculate that the return value of the hashcode method is related to the memory address. Is it correct? Let's run the program to verify it (JDK8 environment).
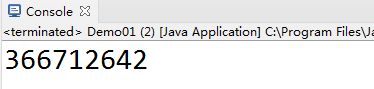
for the first time
public static void main(String[] args) {
Object object=new Object();
System.out.println(object.hashCode());
}
The second time
public static void main(String[] args) {
Object object1=new Object();
Object object2=new Object();
Object object3=new Object();
Object object=new Object();
System.out.println(object.hashCode());
}

We can find that the results of the two runs are the same, which shows that the return value of the hashcode method is indeed independent of the memory address. In the second run, we created three unrelated Object objects to make the memory distribution different from that in the first run. Even so, the return value of the hahscode method obtained in the second run of the program is still the same as that in the first run.
Real hashCode method
The implementation of the hashCode method depends on the JVM. Different JVMs have different implementations. At present, we can see that the JVM source code is the OpenJDK source code. Most of the OpenJDK source code is consistent with the Oracle JVM source code.
OpenJDK defines hashCode in src/share/vm/prims/jvm.h and src/share/vm/prims/jvm.cpp
jvm.cpp:
508 JVM_ENTRY(jint, JVM_IHashCode(JNIEnv* env, jobject handle))
509 JVMWrapper("JVM_IHashCode");
510 // as implemented in the classic virtual machine; return 0 if object is NULL
511 return handle == NULL ? 0 : ObjectSynchronizer::FastHashCode (THREAD, JNIHandles::resolve_non_null(handle)) ;
512 JVM_END
Objectsynchronizer:: fasthashcode() also calls identity_ hash_ value_ The return value of the for method, which is also called by System.identityHashCode().
708 intptr_t ObjectSynchronizer::identity_hash_value_for(Handle obj) {
709 return FastHashCode (Thread::current(), obj()) ;
710 }
We may think that objectsynchronizer:: fasthashcode() will judge whether the current hash value is 0. If it is 0, a new hash value will be generated. Actually, it's not that simple. Let's take a look at the code.
685 mark = monitor->header();
...
687 hash = mark->hash();
688 if (hash == 0) {
689 hash = get_next_hash(Self, obj);
...
701 }
...
703 return hash;
The above fragment shows how the hash value is generated. You can see that the hash value is stored in the object header. If the hash value does not exist, use get_next_hash method generation.
Real identity hash code generation
We found the final function get that generates the hash_ next_ Hash, this function provides six methods to generate hash values.
0. A randomly generated number. 1. A function of memory address of the object. 2. A hardcoded 1 (used for sensitivity testing.) 3. A sequence. 4. The memory address of the object, cast to int. 5. Thread state combined with xorshift (https://en.wikipedia.org/wiki/Xorshift)
Which one do you use by default? According to globals.hpp, OpenJDK8 adopts the fifth method by default. OpenJDK7 and OpenJDK6 both use the first method, the random number generator.
As you can see, the JDK comments deceive us. Obviously, the values in versions 6, 7 and 8 are randomly generated. Why should the boot say that they are memory address mapping? My understanding may be that the previous JDK version was implemented through the fourth method. Please find the answer yourself.
Object header format
In the previous section, we learned that the hash value is placed in the object header. Let's learn about the structure of the object header.
markOop.hpp
30 // The markOop describes the header of an object. 31 // 32 // Note that the mark is not a real oop but just a word. 33 // It is placed in the oop hierarchy for historical reasons. 34 // 35 // Bit-format of an object header (most significant first, big endian layout below): 36 // 37 // 32 bits: 38 // -------- 39 // hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object) 40 // JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object) 41 // size:32 ------------------------------------------>| (CMS free block) 42 // PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object) 43 // 44 // 64 bits: 45 // -------- 46 // unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object) 47 // JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object) 48 // PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object) 49 // size:64 ----------------------------------------------------->| (CMS free block) 50 // 51 // unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object) 52 // JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object) 53 // narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object) 54 // unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
Its format is slightly different between 32-bit and 64 bit. 64 bit has two variants, depending on whether compressed object pointers are enabled.
Conflict between biased lock and hashcode in object header
normal object and biased object store the thread IDs of hashcode and java respectively. Therefore, if the local method hashcode is called, it will occupy the position used by the bias lock object, and the bias lock will become inval id and promoted to a lightweight lock.
In this process, we can see the figure:
Let me briefly explain here. First, when the jvm starts, you can use the - XX:+UseBiasedLocking=true parameter to open the bias lock.
Next, if the partial lock is available, the tag word format in the allocated object can contain the thread ID. when the lock is not locked, the thread ID is 0. When the lock is obtained for the first time, the thread will write its own thread ID into the ThreadID field. In this way, the next time the lock is obtained, directly check whether the thread ID in the tag word is consistent with its own ID. if it is consistent, it is considered that the lock has been obtained, Therefore, there is no need to acquire the lock again.
Suppose that another thread needs to compete for a lock. At this time, the thread will notify the thread holding the biased lock to release the lock. Assuming that the thread holding the biased lock has been destroyed, set the object header to the unlocked state. If the thread is alive, try switching. If it is unsuccessful, the lock will be upgraded to a lightweight lock.
At this time, there is a problem. If you need to obtain the identity hash code of the object, the bias lock will be disabled, and then write the hash value to the position where the thread ID was originally set.
If the hash has a value or the bias lock cannot be revoked, the lightweight lock will be entered. During lightweight lock competition, each thread will first save the hashCode value to its own stack memory, and then try to write its newly created record space address to the object header through CAS. Whoever writes it first will own the object.
A thread that fails to compete for a lightweight lock will spin to try to acquire the lock for a period of time. If it has not acquired the lock after a period of time, it will be upgraded to a heavyweight lock, and the thread that has not acquired the lock will be really blocked.
summary
- The default implementation of the hashcode method of OpenJDK is independent of the object memory address. In versions 6 and 7, it is a randomly generated number, and in version 8, it is a number based on the thread state. (the hashcode of AZUL-ZING is address based)
- In HotSpot, the hash value is stored in the tagName. (there are many kinds of Java virtual machines. Since JDK1.3, HotSpot virtual machine has become the default Java virtual machine for JDK1.3 and all subsequent JDK versions.
- The hashCode method and System.identityHashCode() will prevent objects from using biased locks, so if you want to use biased locks, you'd better override the hashCode method.
- If a large number of objects are used across threads, bias locking can be disabled.
- Use - XX:hashCode = to modify the default hash method implementation.