the application of Web automatic download and conversion of Word mainly involves the application of crawler technology and docx. Through the application of crawler, you can quickly download the content, pictures and videos you want to collect, and use docx to realize the automatic typesetting of Word. If a web contains dozens or even hundreds of words and pictures, if we manually copy the words to Word, then save the pictures one by one on our computer, and then import them one by one in Word, and finally spend a lot of time to typesetting, or we only need some of the contents, and we need to find the relevant contents slowly, How hard it is, and there is the possibility of mistakes.
Therefore, the crawler combined with docx can complete loading and saving in seconds.
take Figure 1 and Figure 2 as examples. text and picture coexist in the Web.
1. How to get the html content of the body? Create a split_text_by_img() function, params are html and imglist respectively. The function is to take the picture as the segmentation reference, and finally return the html of each text content. The specific code is as follows:
def split_text_by_img(html,imglist):
content_parts = []
for imgtag in imglist:
html = str(html) # Convert html into str to pave the way for split
str_tmp = html.split(str(imgtag))[0] # Extract the html of the body content before the picture and add it to the content_parts in this lst
content_parts.append(str_tmp)
html = html.replace((str_tmp + str(imgtag)),'') # Delete the previous text and picture, and turn the latest html into the html of the next loop
content_parts.append(html) # If there is text content after the last picture, you need to add the remaining html back to the content_parts lst
return content_parts # Return lst of N or (N+1) elements (html of body content)
2. How to get pictures? Create a pic function. params are fefer_url and pic_url respectively. The function of referer is to bring a referer when the browser sends a request to the web server to tell the server which page the web page is linked from. Therefore, the server can obtain some information for processing. The specific structure of headers is shown in Figure 3 The body code is as follows:
def pic(referer_url,pic_url):
headers = { "Accept":"text/html,application/xhtml+xml,application/xml;",
"Accept-Encoding":"gzip,deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Referer":referer_url,
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36"
}
img_name = pic_url.split('/')[-1]+'.jpg' # Split the picture link and take the reverse index - 1 as the file name
with open(img_name,'wb')as f:
response = requests.get(pic_url,headers=headers).content
f.write(response)
return img_name #Write the picture link to the binary file and save it as a picture
3. After parsing the specified url, get the title tag, the tag of the whole text, and the tag lst of all pictures. The code is as follows:
url = 'xxxx ' # Fill in the actual url
html = requests.get(url).content
soup = BeautifulSoup(html,'html.parser') # Parsing html
title = soup.title.string #Get the text content of the title tag
post_detial = soup.find('div',id='sina_keyword_ad_area2') # Get the paragraph label of the whole body, as shown in Figure 4
img_tag_list = post_detial.select('a>img ') #Get the tag list of all pictures img
4. Call split_text_by_img function
5. Call two main functions to realize the automatic addition of text and pictures, automatic typesetting and saving of word through circulation.
new_text = split_text_by_img(post_detial,img_tag_list)
document = Document() # Create document object
document.add_heading(title) # Add title
i = 0 # Set the initial value of the cycle to 0
for part in new_text:
part='<html><body><div>' + part # Part is a string containing html tag. When calling BeautifuSoup, it needs lxml formatting and prefix. Otherwise, the content from the second part will be empty during processing
part_tag = BeautifulSoup(part,'lxml')
document.add_paragraph(part_tag.get_text()) # Call the document.add_paragraph() method to add text to the document
if (i < len(img_tag_list)):
imgurl = img_tag_list[i].get('real_src') # Extract image attribute values, as shown in Figure 5
img_name = pic('http://blog.sina.com.cn',imgurl) # call pic() function
document.add_picture(img_name) # Call the document.add_picture () method to add a picture to the document
i=i+1
document.save(title+'.doc') # Save the word file named for the title
Figure 1
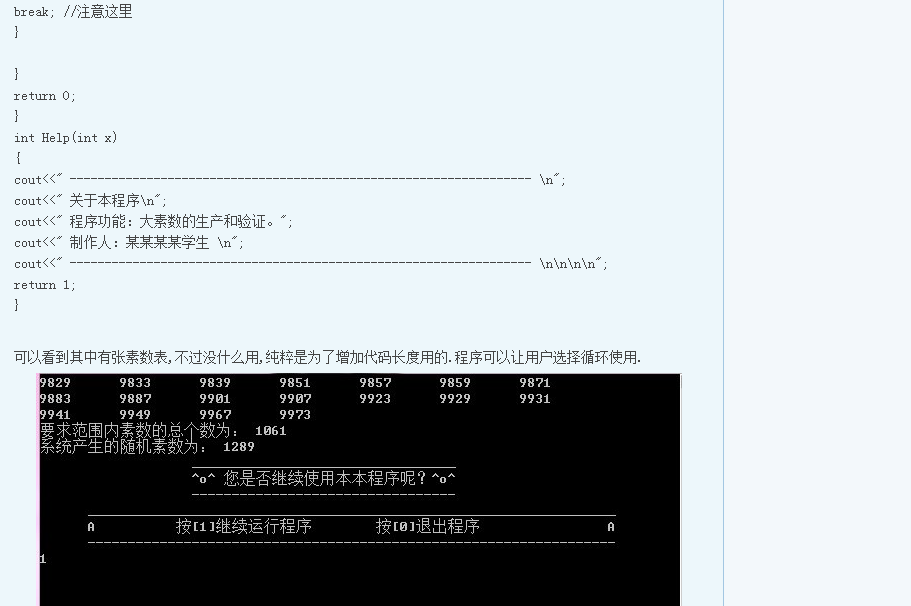
Figure 2
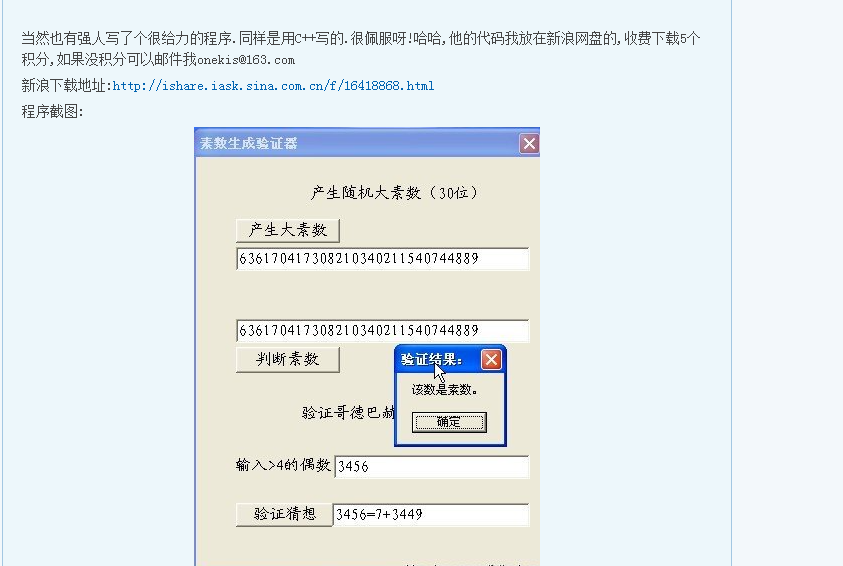
Figure 3
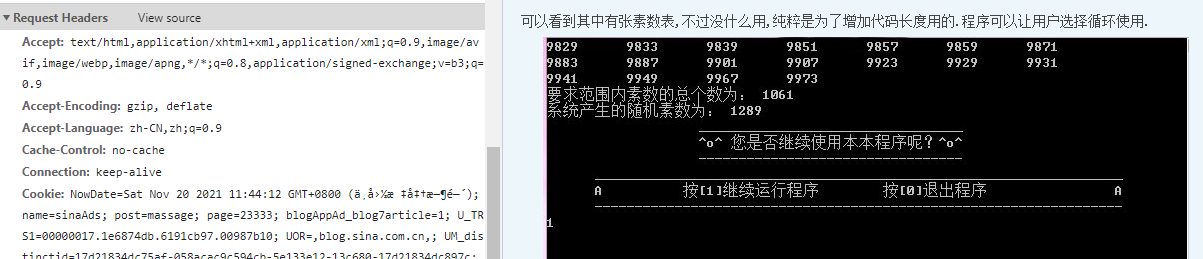
Figure 4

Figure 5
