Vue+Springboot blog project summary
Technology stack: Vue + springboot + mybatis Plus + redis + MySQL
1. Construction of project environment
1.1. Dependency of sub module and parent module
When the parent module uses version management for dependency management, it must declare the version number. If not, the child module cannot introduce the dependencies of the parent module. Of course, another method is to directly copy all the dependencies of the parent module to the child module. In this way, the parent module may not declare the version number;
1.2. Declare parent project
The following must be declared in the pom file of the parent module:
<packaging>pom</packaging> <!--Used to indicate that it is currently a parent project-->
2. Home page article list
2.1 date query
Because create in the database_ Date is bigint 13 bits, but direct year() cannot. You need to change the date type first and then year().
select year(FROM_UNIXTIME(create_date/1000)) year,month(FROM_UNIXTIME(create_date/1000))
2.2 Mapper interface red
Just add comments on the Mapper file
@Repository
public interface ArticleMapper extends BaseMapper<Article> { }
2.3. What if mybatisplus encounters multiple table queries
Complex sql needs to be implemented by ourselves, but it should be noted that when we add corresponding xml for mapper under resources, the package name under resources should be consistent with that of mapper file under java
3. Hottest label
The hottest label is the label ms_article_tag in tag_id is our hottest tag with the largest number of sorting
1. The largest number of articles owned by the tag is the hottest tag. 2. Query according to the tag_ The id group count takes the first limit 3 from the largest to the smallest, and then finds out the label according to the id
4. Unified exception handling
@ControllerAdvice //Intercept the method annotated with Controller and implement AOP!
public class AllExceptionHandler {
//Handle exceptions and handle Exception.class
@ExceptionHandler(Exception.class)
@ResponseBody
public Result doException(Exception e){
e.printStackTrace();
return Result.fail(-999,"System exception") ; //json that returns an error when an exception occurs
}
}
5. Hottest article
First sort by top, and then sort order by view according to the number of views_ count desc
6. Latest article
First sort by top, and then reverse order by create according to creation time_ time desc
7. Article archiving
SELECT YEAR(FROM_UNIXTIME(create_date/1000)) YEAR,MONTH(FROM_UNIXTIME(create_date/1000)) MONTH,COUNT(*)COUNT FROM ms_article GROUP BY YEAR,MONTH;
GROUP BY YEAR,MONTH; This means that all records with the same month field value and year are placed in one group. That is, they are grouped by month and year, and all months and years are counted as one group
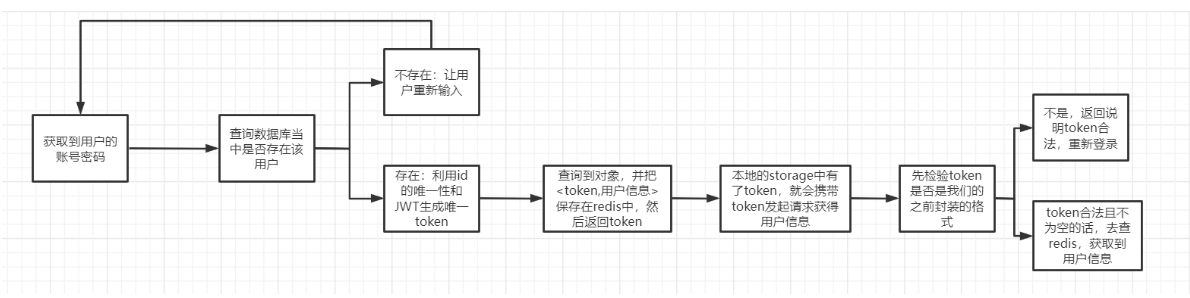
8. Login, user information, logout
Just sort out ideas
- Token is a string generated by the server as a token to identify the client when the client makes a request. After the user logs in for the first time, the server generates a token and returns it to the client. In the future, the client only needs to bring this token to request data without bringing the user name and password again.
- After the token is obtained by the front end, it will be stored in the storage h5 and stored locally. After it is stored, it will get the token in the storage to obtain the user information. If this interface is not implemented, it will always request to fall into an endless loop
- The purpose of Token is to verify the user login, reduce the pressure on the server, reduce frequent database queries, and make the server more robust.
User login
-
Check whether the parameters are legal
-
Query whether the user exists in the user table according to the user name and password
-
If there is no login failure
-
If yes, make jwt generate a token and return it to the front end
-
Put the token into redis and set the expiration time
//Put the token into redis key: token value: user information expiration time: 1 day redisTemplate.opsForValue().set("TOKEN_"+token, JSON.toJSONString(sysUser),1, TimeUnit.DAYS); -
First verify whether the token is legal, and then go to redis to verify whether it exists)
Get current user information
- Validity verification of token: whether it is empty, whether the parsing is successful, and whether redis exists
- Error returned after verification failure
- The verification is successful and the result LoginUserVo is returned
cancellation
- At this time, we must be able to obtain a token in the login status. We can delete the user information in redis through this token
The whole process
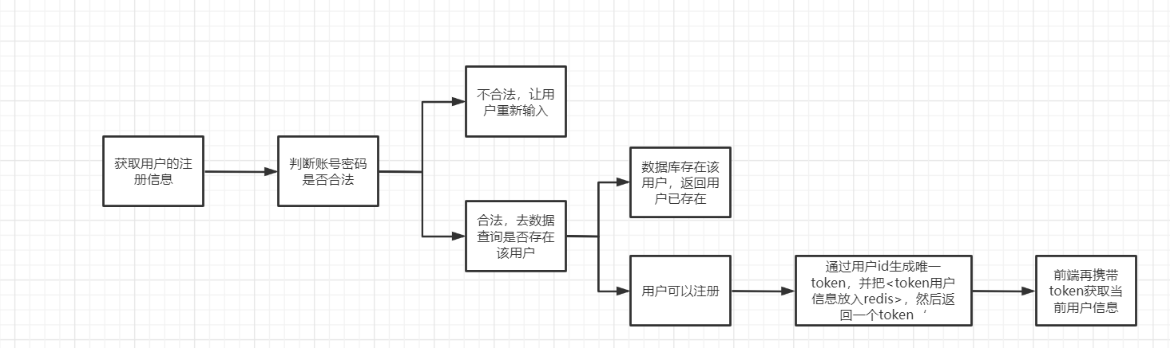
9. Register
The same is just combing ideas
User registration
- Judge whether the account is legal
- Judge whether the account exists and return that the account has been registered
- Does not exist, registered user
- Generate token
- Pass in redis and return
- Note that if there is a problem in any step, the user will roll back!
In fact, the principle is the same as when logging in
One thing to note is that we need to add a transaction for registered users: roll back when an error occurs to prevent adding exceptions
@Service
@Transactional //Open transaction
public class LoginServiceImpl implements LoginService {}
Of course, it is generally recommended to add the transaction annotation @ Transactional to the interface, which is more general.
@Transactional
public interface LoginService {
Result login(LoginParam loginParam);
SysUser checkToken(String token);
Result logout(String token);
Result register(LoginParam loginParam);
}
10. ThreadLocal saves user information*
Project highlights
//Extract a class
public class UserThreadLocal {
private UserThreadLocal(){}
//Thread variable isolation
private static final ThreadLocal<SysUser> LOCAL = new ThreadLocal<>();
public static void put(SysUser sysUser){
LOCAL.set(sysUser);
}
public static SysUser get(){
return LOCAL.get();
}
public static void remove(){
LOCAL.remove();
}
}
How do you use it?
We add an interceptor for the project to intercept some interfaces, and verify whether the user logs in by obtaining a token. If the user logs in, the obtained user information is saved in ThreadLocal, which means that the key value pair < thread, sysuser > is thread isolated and binds a user information to the current thread, so as long as it is the current thread, We can get our current user information at any time!
Need attention
- After using ThreadLocal, we need to delete it, otherwise there will be a memory leak
11. Article details
At this time, there may be a loss of ID accuracy. Because our database uses the distributed ID of the snowflake algorithm, it is certainly no problem to query it and save it with Long type, but our js can't parse the data of Long type and will lose accuracy. Therefore, the ID attribute in the vo object we convert needs to be processed
- Method 1: serialization through annotations to ensure accuracy
public class ArticleVo {
@JsonSerialize(using = ToStringSerializer.class) //The function of this annotation is to ensure the accuracy of the id obtained by the snowflake algorithm
private Long id;
}
- Method 2: convert to String to ensure accuracy. This step needs to be extracted separately during object conversion, because the copy method cannot directly convert Long to String [recommended]
public class ArticleVo {
private String id;
}
//Content in copy method
articleVo.setId(String.valueOf(article.getId())); //long and String cannot be copied
12. Thread pool update reads*
When we visit an article, we need to:
- After clicking on the article, we need to increase the number of readings by one,
- After reading the article, the data should be returned directly. At this time, a write operation is performed. When updating, a write lock is added to block other operations, and the performance is relatively low
- The update operation increases the time-consuming of the interface. Once there is a problem with the update, the operation of reading the article cannot be affected
This process can be optimized, so that our number of views + 1 task and article details can be loaded for asynchronous execution. Here, the asynchronous execution adopts thread pool!
Thread pool configuration
@Configuration
@EnableAsync // Turn on Multithreading pool
public class ThreadPoolConfig {
@Bean("taskExecutor")
public Executor asyncServiceExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// Set the number of core threads
executor.setCorePoolSize(5);
// Set the maximum number of threads
executor.setMaxPoolSize(20);
//Configure queue size
executor.setQueueCapacity(Integer.MAX_VALUE);
// Set thread active time (seconds)
executor.setKeepAliveSeconds(60);
// Set default thread name
executor.setThreadNamePrefix("SQx's Blog");
// Wait for all tasks to finish before closing the thread pool
executor.setWaitForTasksToCompleteOnShutdown(true);
//Perform initialization
executor.initialize();
return executor;
}
}
We leave this task to the thread pool for execution through annotations
@Async("taskExecutor") //This task is dropped into our thread pool
public void updateArticleViewCount(ArticleMapper articleMapper, Article article) {
int viewCounts = article.getViewCounts() ; //Gets the current number of readings of the article
Article articleUpdate = new Article();
articleUpdate.setViewCounts(viewCounts+1); //Create a new object and set the number of readings + 1
LambdaUpdateWrapper<Article> updateWrapper = new LambdaUpdateWrapper<>(); //We update the conditions of the operation
updateWrapper.eq(Article::getId,article.getId());
updateWrapper.eq(Article::getViewCounts,viewCounts) ; //The idea of optimistic locking is used here to ensure thread safety
System.out.println("The modified object is"+articleUpdate+"======================");
//Perform update operation
articleMapper.update(articleUpdate,updateWrapper);
}
The sql executed here uses the idea of optimistic locking!
There is a Bug here that needs attention!
When we update the number of views, we set the number of reads + 1 by creating a new object. At this time, if there is an int attribute (basic type attribute) in our Article object, an initial value of 0 will be automatically assigned. In this way, when this object is modified into update, if it is not null, mybatisplus will be generated into the sql statement for update, Therefore, at this time, all the basic user data types in the object are converted to Integer encapsulated types. In this way, when you create your object without assignment, it will only be null without default value, so that other properties will not be modified!
13. Comment list
The most important thing about comments is to understand the meaning of each field
public class Comment {
private Long id; //id of the comment
private String content; //Content of comments
private Long createDate; //Comment time
private Long articleId; //Article id (for which article)
private Long authorId; //Author id (who commented)
private Long parentId; //Parent comment id
private Long toUid; // Who to comment on the author of the parent comment id
private Integer level; //Current comment level
}
Then you can find it through the article id, but some of the attributes need to be transformed slightly more complex!
14. Commentary
The essence is to encapsulate the object, and then
@Override
public Result comment(CommentParam commentParam) {
//Get the current user
SysUser sysUser = UserThreadLocal.get(); //Get current user information
Comment comment = new Comment();
comment.setArticleId(commentParam.getArticleId()); //Get article id
comment.setAuthorId(sysUser.getId()); //Current user id
comment.setContent(commentParam.getContent()); //Content of comments
comment.setCreateDate(System.currentTimeMillis()); //Comment time
Long parent = commentParam.getParent(); //Parent comment id
if (parent == null || parent == 0) {
comment.setLevel(1); //The parent comment id does not exist. The level of the current comment is 1
}else{
comment.setLevel(2); //The parent comment id exists, and the level of the current comment is set to 2
}
//If it is empty, the parent is 0
comment.setParentId(parent == null ? 0 : parent); //Parent comment id
Long toUserId = commentParam.getToUserId(); //Commented user
comment.setToUid(toUserId == null ? 0 : toUserId);
this.commentMapper.insert(comment);
return Result.success(null);
}
15. Publish articles
You need to find out all the classification and label information before publishing the article (this is very simple)
Realize publishing articles
// @The RequestBody is mainly used to receive the data in the json string passed from the front end to the back end (the data in the request body);
// The most common way to use the request body to transfer parameters is undoubtedly the POST request, so when using @ RequestBody to receive data, it is generally submitted in the form of POST.
@PostMapping("publish")
public Result publish(@RequestBody ArticleParam articleParam){
return articleService.publish(articleParam);
}
@Override
@Transactional
public Result publish(ArticleParam articleParam) {
//Note that if you want to get the data, you must add the interface to the interceptor
SysUser sysUser = UserThreadLocal.get();
/**
* 1. The purpose of publishing an Article is to build an Article object
* 2. Author id current login user
* 3. Tag to add a tag to the association list
* 4. body Content store article bodyId
*/
Article article = new Article();
article.setAuthorId(sysUser.getId());
article.setCategoryId(articleParam.getCategory().getId());
article.setCreateDate(System.currentTimeMillis());
article.setCommentCounts(0);
article.setSummary(articleParam.getSummary());
article.setTitle(articleParam.getTitle());
article.setViewCounts(0);
article.setWeight(Article.Article_Common);
article.setBodyId(-1L);
//After insertion, an article id will be generated (because the newly created article does not have an article id, you need to insert it
//The official website explains: "after insart, the primary key will be automatically 'set to the ID field of the entity, so you only need" getid()
// Using the auto increment of the primary key, the id value of mp will return to the parameter object after the insert operation
//https://blog.csdn.net/HSJ0170/article/details/107982866
this.articleMapper.insert(article);
//tags
List<TagVo> tags = articleParam.getTags();
if (tags != null) {
for (TagVo tag : tags) {
ArticleTag articleTag = new ArticleTag();
articleTag.setArticleId(article.getId());
articleTag.setTagId(tag.getId());
this.articleTagMapper.insert(articleTag);
}
}
//body
ArticleBody articleBody = new ArticleBody();
articleBody.setContent(articleParam.getBody().getContent());
articleBody.setContentHtml(articleParam.getBody().getContentHtml());
articleBody.setArticleId(article.getId());
articleBodyMapper.insert(articleBody);
//After insertion, give an id
article.setBodyId(articleBody.getId());
//When does the save method in MybatisPlus execute insert and update
// https://www.cxyzjd.com/article/Horse7/103868144
//Insert or update only when the database is changed. General query is OK
articleMapper.updateById(article);
ArticleVo articleVo = new ArticleVo();
articleVo.setId(article.getId());
return Result.success(articleVo);
}
16. AOP log
Reference article: [SpringBoot: configuring AOP print logs]
17. Article picture upload
Springboot integrates qiniu cloud to upload pictures
18. List of all labels and classifications
These two are very simple. No parameters are required. Just check the corresponding two tables directly!
19. Category, tag, article list
Check the classification details through our classification id | tag id, and then check the qualified articles in the article table through the classification id | tag id
Paging query article
@Override
public Result listArticle(PageParams pageParams) {
/**
* 1,Paging query article database table
*/
Page<Article> page = new Page<>(pageParams.getPage(), pageParams.getPageSize());
LambdaQueryWrapper<Article> queryWrapper = new LambdaQueryWrapper<>();
//Add the classification id to the query article parameter. If it is not empty, add the classification condition
if (pageParams.getCategoryId()!=null) {
//and category_id=#{categoryId}
queryWrapper.eq(Article::getCategoryId,pageParams.getCategoryId());
}
//Whether to sort by placing it at the top or not, / / arrange it in reverse chronological order, which is equivalent to order by create_data desc
queryWrapper.orderByDesc(Article::getWeight,Article::getCreateDate);
Page<Article> articlePage = articleMapper.selectPage(page, queryWrapper);
//Paging query usage https://blog.csdn.net/weixin_41010294/article/details/105726879
List<Article> records = articlePage.getRecords();
// To return the vo data defined by us is the corresponding front-end data. We should not only return the current data, but need to further process it
List<ArticleVo> articleVoList =copyList(records,true,true);
return Result.success(articleVoList);
}
The same is true for labels
20. List of archived articles
You need to query all articles by month and year as a condition, which is realized by dynamic sql
@Override
public Result listArticle(PageParams pageParams) {
Page<Article> page = new Page<>(pageParams.getPage(),pageParams.getPageSize());
IPage<Article> articleIPage = this.articleMapper.listArticle(page,pageParams.getCategoryId(),pageParams.getTagId(),pageParams.getYear(),pageParams.getMonth());
return Result.success(copyList(articleIPage.getRecords(),true,true));
}
<?xml version="1.0" encoding="UTF-8" ?>
<!--MyBatis configuration file-->
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.huel.dao.mapper.ArticleMapper">
<!--Make a result set mapping-->
<resultMap id="articleMap" type="com.huel.dao.pojo.Article">
<id column="id" property="id" />
<result column="author_id" property="authorId"/>
<result column="comment_counts" property="commentCounts"/>
<result column="create_date" property="createDate"/>
<result column="summary" property="summary"/>
<result column="title" property="title"/>
<result column="view_counts" property="viewCounts"/>
<result column="weight" property="weight"/>
<result column="body_id" property="bodyId"/>
<result column="category_id" property="categoryId"/>
</resultMap>
<!--Query Archive-->
<select id="listArchives" resultType="com.huel.dao.dos.Archives">
SELECT YEAR(FROM_UNIXTIME(create_date/1000)) YEAR,
MONTH(FROM_UNIXTIME(create_date/1000)) MONTH,
COUNT(*) COUNT FROM ms_article
GROUP BY YEAR,MONTH;
</select>
<!--Query article list-->
<select id="listArticle" resultMap="articleMap">
select * from ms_article
<where>
1 = 1
<if test="categoryId != null">
and category_id=#{categoryId}
</if>
<if test="tagId != null">
and id in (select article_id from ms_article_tag where tag_id=#{tagId})
</if>
<if test="year != null and year.length>0 and month != null and month.length>0">
and (FROM_UNIXTIME(create_date/1000,'%Y') =#{year} and
FROM_UNIXTIME(create_date/1000,'%m')=#{month})
</if>
</where>
order by weight desc ,create_date desc
</select>
</mapper>
21. Global cache optimization*
The access speed of memory is much higher than that of disk (from 1000 times)
Summary of ideas
We add annotations to an interface, which is equivalent to a pointcut. Our pointcut performs surround notification for this pointcut. We can get the method enhancement in the pointcut
The method name, class name, parameter and the name in the annotation of the pointcut. Next, encrypt the parameters through MD5, and then splice these parameters together,
The newly generated string is Redis key. When we call this interface, we will first go to Redis to determine whether the key corresponds to value,
-
If it exists, return it directly. This is Redis (CACHE)
-
If it does not exist, continue to call the interface, get the result of the interface, get the result to < Redis key, and save the result in Redis,
It is then cached directly as the return value
22. Set up management background
Only one user's permission management is done in the background, and spring security is used
Note: the login here is for background login, and the previous login is for users, not the same table!
Write SecurityConfig configuration
/***
* SpringSecurity Configuration of
*/
@Configuration
public class SecurityConfig extends WebSecurityConfigurerAdapter {
//Encrypted object
@Bean
public BCryptPasswordEncoder bCryptPasswordEncoder(){ //BCrypt encryption is adopted
return new BCryptPasswordEncoder();
}
//Used to generate test data
public static void main(String[] args) {
//Encryption policy MD5 unsafe rainbow table MD5 salt
String password = new BCryptPasswordEncoder().encode("admin");
System.out.println(password);
}
@Override
public void configure(WebSecurity web) throws Exception {
super.configure(web);
}
/*Customize authorization rules to customize the permissions required by the request*/
@Override
protected void configure(HttpSecurity http) throws Exception {
//Chain programming
http.authorizeRequests() //Turn on login authentication
// . antMatchers("/user/findAll").hasRole("admin") / / the provider needs the role of admin
.antMatchers("/css/**").permitAll()
.antMatchers("/img/**").permitAll() //Release
.antMatchers("/js/**").permitAll()
.antMatchers("/plugins/**").permitAll()
//All requests with / admin / * * must be authenticated. After being processed by authService, return true to indicate that the authentication has passed, and return false to indicate that the authentication has failed!
.antMatchers("/admin/**").access("@authService.auth(request,authentication)") //Customize the service to realize real-time authority authentication
//All requests with / pages / * * can be accessed as long as the login is successful
.antMatchers("/pages/**").authenticated()
// We don't have permission to enter the default login page. We use our own login page instead of the default login page
.and().formLogin()
.loginPage("/login.html") //Custom login page
.loginProcessingUrl("/login") //Login processing interface (the login interface provided by spring security)
.usernameParameter("username") //The key that defines the user name during login is username by default
.passwordParameter("password") //Define the password key when logging in. The default is password
.defaultSuccessUrl("/pages/main.html") //Page to which login successfully jumps
.failureUrl("/login.html") //Login failed, jump to the page
.permitAll() //By not intercepting, it is determined by the previously configured path, which means that all interfaces related to the login form pass through
.and().logout() //Exit login configuration
.logoutUrl("/logout") //Exit login interface
.logoutSuccessUrl("/login.html")
.permitAll() //Exit login interface release
.and()
.httpBasic()
.and() //Turn off csrf function: Cross Site Request Forgery. By default, logout requests can only be submitted through post
.csrf().disable() //csrf Close if the custom login needs to be closed (if it is not written, there will be a problem with one of the login or logout! 404)
.headers().frameOptions().sameOrigin(); //Support iframe nesting
}
}
/***
* SpringSecurity Process: 1. First, we customize the authentication rules for requests in the configuration file. What permissions are required for each request to access
* 2,Then, when we access a request and intercept it, we need to judge whether the current user is authenticated (logged in)
* 3,If it is authentication (login), jump to the login interface. If the authentication is successful, find the corresponding permission id according to the user id, and then obtain the permission of the current user
* 4,Users can access according to their own permissions!
*
*/
When our user is not authenticated, we will request / login by default to let the user log in and authenticate. When our user logs in, we will use the following method: verify the user name!
By judging whether the user exists in the database,
- If it does not exist, throw the exception UsernameNotFoundException directly!
- If it exists, obtain the username, password (encrypted in the database) and permission list of the object (the permission checked by the user name)
Then, the result is encapsulated as a User object of security itself, and the returned password part is handed over to our security for judgment. No judgment is made here
loadUserByUsername(String username)
/***
* Our spring security authentication function (login)
*
*/
@Component
public class SecurityUserService implements UserDetailsService {
@Autowired
private AdminService adminService ;
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
/***
* 1,The username will be passed here when logging in
* 2,Query the admin table through username. If admin exists, tell spring security the password
* 3,If it does not exist, null is returned, and authentication fails
*
*/
Admin admin = adminService.findAdminByUsername(username);
if (admin == null){
//Login failed
return null ;
}
//Login succeeded (only this user exists in the database!)
//Verify the password (leave the part of verifying the password to spring security)
UserDetails userDetails = new User(username,admin.getPassword(),new ArrayList<>()) ;
return userDetails;
}
}
//Login succeeded!
Then we judge the authorization of our current user and execute auth method: execute when we call an interface that requires permission
- First, get which interface is currently requested (that is, the user's request path)
- Then, judge whether the user exists, whether it is a tourist, etc. if so, return false, indicating that the current user does not exist and does not have permission to access the interface! Otherwise, it indicates that the user exists, obtain the user's permission, and then verify it!
- Get the id of the current user. If the id is 1, it means that the current user is a super administrator. There is no need to judge the permissions. He has all permissions! Otherwise, obtain the current user permission through id
- Compared with the interface, if the user has the current permission, it will return true and the access is successful! Otherwise, return false, no permission to access!
to be finished!