Unofficial Code: github codehttps://github.com/jeasinema/VoxelNet-tensorflow
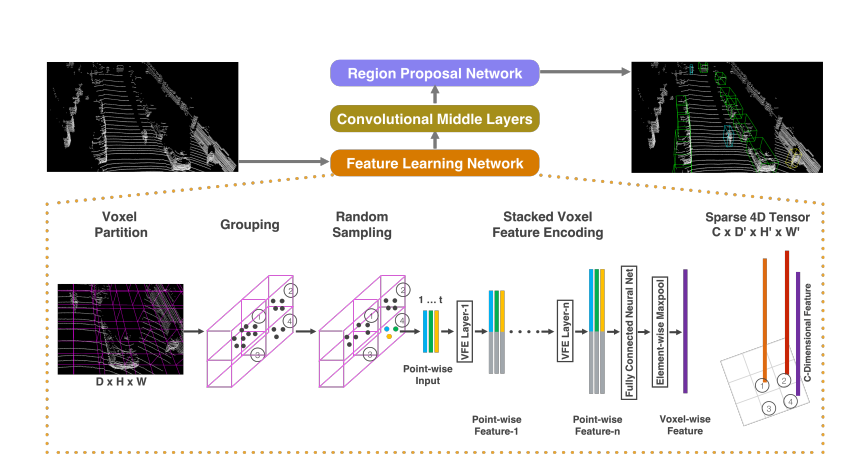 The network structure can be divided into the above three parts: feature learning network, revolutionary middle layers, and the RPN part of the final production forecast results and boxes (refer to fast r-cnn for this part)
The network structure can be divided into the above three parts: feature learning network, revolutionary middle layers, and the RPN part of the final production forecast results and boxes (refer to fast r-cnn for this part)
1, feature learning network
This part mainly divides the point cloud into small voxels, fully connects each voxel containing points, generates VFE layer for each voxel, and finally obtains the four-dimensional tensor, that is, all the steps shown in the figure below are completed.
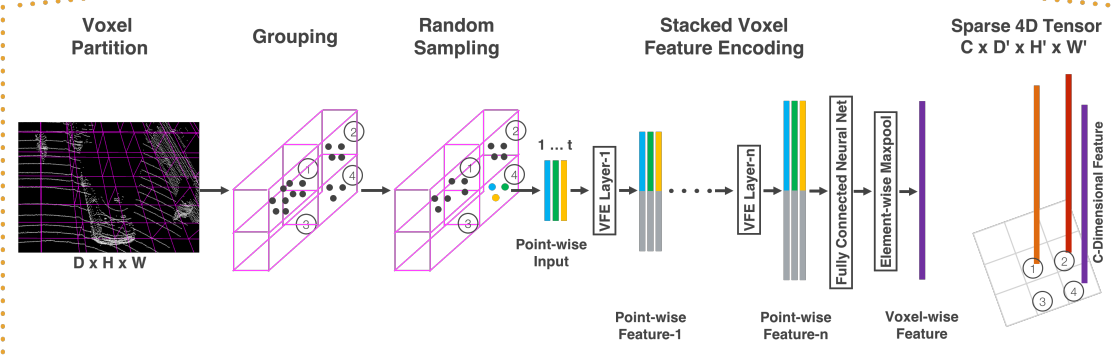
VFE layer
Non empty voxel V (voxel contains T < = t points) is processed, and point Pi includes its XYZ coordinates and reflectivity information [Xi,Yi,Zi,ri].
The following are the steps for processing a single V. all non empty V processing is the same
1. Calculate the average value of points in V to obtain (Vx,Vy,Vz)
2. The mean value is extended to the tensor of each point, and the dimension is 7, [Xi, Yi, Zi, RI, Xi VX, Yi vy, Zi VZ]
3. Each point in V is transformed into a feature space through the fully connected network FCN
FCN layer includes linear layer, BN layer and ReLU layer
4. Maximum pooling processes each point feature of the full connection layer
5. Finally, the maximum value pool processing results of each point are combined with the FCN layer processing results


Code analysis training strategy
Setting of learning rate
self.cls = cls
self.single_batch_size = single_batch_size
self.learning_rate = tf.Variable(
float(learning_rate), trainable=False, dtype=tf.float32)
self.global_step = tf.Variable(1, trainable=False)
self.epoch = tf.Variable(0, trainable=False)
self.epoch_add_op = self.epoch.assign(self.epoch + 1)
self.alpha = alpha
self.beta = beta
self.avail_gpus = avail_gpus
boundaries = [80, 120]
values = [ self.learning_rate, self.learning_rate * 0.1, self.learning_rate * 0.01 ]
lr = tf.train.piecewise_constant(self.epoch, boundaries, values)
Use tf.train.piece wise_ Constant() can change the learning rate during training in two ways. The first is the exponential decay of the learning rate, and the second is to specify a learning rate within a certain range of iterations.
tf.train.piecewise_constant() is the second. boundaries = [80, 120] is the range interval. Values = [self.learning_rate, self.learning_rate * 0.1, self.learning_rate * 0.01] defines the learning rate of each interval, that is, the learning rate is self.learning in steps 0 ~ 80_ Rate, 80 ~ 120, the learning rate is self. Learning_ After rate * 0.1120, the learning rate is self.learning_ rate * 0.01. self.epoch represents the number of iterations in the function global_step.
Code analysis II - VFE layer implementation
From model.group is referenced in the code model.py_ Pointcloud imports featurenet to implement the work of this layer
The following parameters are mainly passed in model.py
feature = FeatureNet(training=self.is_train,batch_size=self.single_batch_size)
group_pointcloud.py implements all the contents of the first layer feature learning network for two classes, FeatureNet class, and VFElayer defines how to implement each layer
class VFELayer(object):
def __init__(self, out_channels, name):
super(VFELayer, self).__init__()
self.units = int(out_channels / 2)
with tf.variable_scope(name, reuse=tf.AUTO_REUSE) as scope:
self.dense = tf.layers.Dense(
self.units, tf.nn.relu, name='dense', _reuse=tf.AUTO_REUSE, _scope=scope)#Set the full connection layer. See the following for the specific explanation of the function. Output = m*k, k=out_channels / 2
self.batch_norm = tf.layers.BatchNormalization(
name='batch_norm', fused=True, _reuse=tf.AUTO_REUSE, _scope=scope)#Set BN layer
def apply(self, inputs, mask, training):
# [K, T, 7] tensordot [7, units] = [K, T, units]
pointwise = self.batch_norm.apply(self.dense.apply(inputs), training)
#n [K, 1, units]
aggregated = tf.reduce_max(pointwise, axis=1, keep_dims=True)#axis=1, calculate the maximum value according to the row, that is, pool the characteristics of each point obtained by FCN layer
# [K, T, units]
repeated = tf.tile(aggregated, [1, cfg.VOXEL_POINT_COUNT, 1])#Copy the result of the maximum value of the column on each column so that subsequent point features can be combined
# [K, T, 2 * units]
concatenated = tf.concat([pointwise, repeated], axis=2)#Combine the pool processing result of the maximum value of each point with the FCN layer processing result
mask = tf.tile(mask, [1, 1, 2 * self.units])
concatenated = tf.multiply(concatenated, tf.cast(mask, tf.float32))#The pool processing result of the maximum value of each point in the non empty voxel is combined with the FCN layer processing result
return concatenated
class FeatureNet(object):
def __init__(self, training, batch_size, name=''):
super(FeatureNet, self).__init__()
self.training = training
# scalar
self.batch_size = batch_size
# [ΣK, 35/45, 7]
self.feature = tf.placeholder(
tf.float32, [None, cfg.VOXEL_POINT_COUNT, 7], name='feature')
# [ΣK]
self.number = tf.placeholder(tf.int64, [None], name='number')
# [ΣK, 4], each row stores (batch, d, h, w)
self.coordinate = tf.placeholder(
tf.int64, [None, 4], name='coordinate')
with tf.variable_scope(name, reuse=tf.AUTO_REUSE) as scope:
self.vfe1 = VFELayer(32, 'VFE-1')
self.vfe2 = VFELayer(128, 'VFE-2')
# boolean mask [K, T, 2 * units]
mask = tf.not_equal(tf.reduce_max(
self.feature, axis=2, keep_dims=True), 0)#Determine the non empty set tf.not_equal(x,y) returns X= True value of Y
x = self.vfe1.apply(self.feature, mask, self.training)
x = self.vfe2.apply(x, mask, self.training)
# [ΣK, 128]
voxelwise = tf.reduce_max(x, axis=1)
# car: [N * 10 * 400 * 352 * 128]
# pedestrian/cyclist: [N * 10 * 200 * 240 * 128]
self.outputs = tf.scatter_nd(
self.coordinate, voxelwise, [self.batch_size, 10, cfg.INPUT_HEIGHT, cfg.INPUT_WIDTH, 128])#Spread the updates to the new (initially zero) tensor according to indices. The final sparse tensor is obtained
1,tf.layers.dense( input, units=k )
Author: Mr Fenrir
Link: https://www.jianshu.com/p/3855908b4c29
Source: Jianshu
The function automatically generates a weight matrix kernel and an offset term bias internally. The specific dimensions of each variable are as follows: for the two-dimensional tensor input with size [m, n], TF. Layers. Deny() will generate a weight matrix kernel with size [n, k] and an offset term bias with size [m, k]. The internal calculation process is y = input * kernel + bias, and the dimension of the output value y is [M, k].
Routine:
import tensorflow as tf
# 1. Call tf.layers.deny to calculate
input = tf.reshape(tf.constant([[1., 2.], [2., 3.]]), shape=[4, 1])
b1 = tf.layers.dense(input,
units=2,
kernel_initializer=tf.constant_initializer(value=2), # shape: [1,2]
bias_initializer=tf.constant_initializer(value=1)) # shape: [4,2]
# 2. Calculate by matrix multiplication
kernel = tf.reshape(tf.constant([2., 2.]), shape=[1, 2])
bias = tf.reshape(tf.constant([1., 1., 1., 1., 1., 1., 1., 1.]), shape=[4, 2])
b2 = tf.add(tf.matmul(input, kernel), bias)
with tf.Session()as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(b1))
print(sess.run(b2))
2,tf.reduce_max()
https://blog.csdn.net/lllxxq141592654/article/details/85345864
import tensorflow as tf
import numpy as np
a=np.array([[1, 2],
[5, 3],
[2, 6]])
b = tf.Variable(a)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(b))
print('************')
# For a two-dimensional matrix, the axis=0 axis can be understood as the row growth direction (down), and the axis=1 axis can be understood as the column growth direction (right)
print(sess.run(tf.reduce_max(b, axis=1, keepdims=False))) # keepdims=False,axis=1 is subtracted
print('************')
print(sess.run(tf.reduce_max(b, axis=1, keepdims=True)))
print('************')
print(sess.run(tf.reduce_max(b, axis=0, keepdims=True)))
[[1 2] [5 3] [2 6]] ************ [2 5 6] ************ [[2] [5] [6]] ************ [[5 6]]
3,tf.title()
https://www.cnblogs.com/yibeimingyue/p/11869882.html
tf.tile() usage introduction
tile() means tile, which is used for copying on the same dimension
tile(
input, #input
multiples, #Number of copies on the same dimension
name=None
)
Examples are as follows:
with tf.Graph().as_default():
a = tf.constant([1,2],name='a')
b = tf.tile(a,[3])
sess = tf.Session()
print(sess.run(b))
Copy the same dimension of [1,2] three times. The dimensions of the multiples parameter should be consistent with the input dimension. The results are as follows:
[1 2 1 2 1 2]
with tf.Graph().as_default():
a = tf.constant([[1,2],[3,4]],name='a')
b = tf.tile(a,[2,3])
sess = tf.Session()
print(sess.run(b))
Output:
[[1 2 1 2 1 2] [3 4 3 4 3 4] [1 2 1 2 1 2] [3 4 3 4 3 4]]
4,tf.scatter_nd()
Spread the updates to the new (initially zero) tensor according to indices.
indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([9, 10, 11, 12])
shape = tf.constant([8])
scatter = tf.scatter_nd(indices, updates, shape)
with tf.Session() as sess:
print(sess.run(scatter))
2, Revolutionary middle layers
3, Region Proposal Network
The contents of the last two networks are put together in the program
model.py is defined as follows:
rpn = MiddleAndRPN(input=feature.outputs, alpha=self.alpha, beta=self.beta, training=self.is_train)
This function is in rpn.py
class MiddleAndRPN:
def __init__(self, input, alpha=1.5, beta=1, sigma=3, training=True, name=''):
# scale = [batchsize, 10, 400/200, 352/240, 128] should be the output of feature learning network
self.input = input
self.training = training
# groundtruth(target) - each anchor box, represent as △x, △y, △z, △l, △w, △h, rotation
self.targets = tf.placeholder(
tf.float32, [None, cfg.FEATURE_HEIGHT, cfg.FEATURE_WIDTH, 14])
# postive anchors equal to one and others equal to zero(2 anchors in 1 position)
self.pos_equal_one = tf.placeholder(
tf.float32, [None, cfg.FEATURE_HEIGHT, cfg.FEATURE_WIDTH, 2])
self.pos_equal_one_sum = tf.placeholder(tf.float32, [None, 1, 1, 1])
self.pos_equal_one_for_reg = tf.placeholder(
tf.float32, [None, cfg.FEATURE_HEIGHT, cfg.FEATURE_WIDTH, 14])
# negative anchors equal to one and others equal to zero
self.neg_equal_one = tf.placeholder(
tf.float32, [None, cfg.FEATURE_HEIGHT, cfg.FEATURE_WIDTH, 2])
self.neg_equal_one_sum = tf.placeholder(tf.float32, [None, 1, 1, 1])
with tf.variable_scope('MiddleAndRPN_' + name):
# convolutinal middle layers
temp_conv = ConvMD(3, 128, 64, 3, (2, 1, 1),
(1, 1, 1), self.input, name='conv1')
temp_conv = ConvMD(3, 64, 64, 3, (1, 1, 1),
(0, 1, 1), temp_conv, name='conv2')
temp_conv = ConvMD(3, 64, 64, 3, (2, 1, 1),
(1, 1, 1), temp_conv, name='conv3')
temp_conv = tf.transpose(temp_conv, perm=[0, 2, 3, 4, 1])
temp_conv = tf.reshape(
temp_conv, [-1, cfg.INPUT_HEIGHT, cfg.INPUT_WIDTH, 128])
# rpn
# block1:
temp_conv = ConvMD(2, 128, 128, 3, (2, 2), (1, 1),
temp_conv, training=self.training, name='conv4')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv5')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv6')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv7')
deconv1 = Deconv2D(128, 256, 3, (1, 1), (0, 0),
temp_conv, training=self.training, name='deconv1')
# block2:
temp_conv = ConvMD(2, 128, 128, 3, (2, 2), (1, 1),
temp_conv, training=self.training, name='conv8')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv9')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv10')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv11')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv12')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv13')
deconv2 = Deconv2D(128, 256, 2, (2, 2), (0, 0),
temp_conv, training=self.training, name='deconv2')
# block3:
temp_conv = ConvMD(2, 128, 256, 3, (2, 2), (1, 1),
temp_conv, training=self.training, name='conv14')
temp_conv = ConvMD(2, 256, 256, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv15')
temp_conv = ConvMD(2, 256, 256, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv16')
temp_conv = ConvMD(2, 256, 256, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv17')
temp_conv = ConvMD(2, 256, 256, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv18')
temp_conv = ConvMD(2, 256, 256, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv19')
deconv3 = Deconv2D(256, 256, 4, (4, 4), (0, 0),
temp_conv, training=self.training, name='deconv3')
# final:
temp_conv = tf.concat([deconv3, deconv2, deconv1], -1)
# Probability score map, scale = [None, 200/100, 176/120, 2]
p_map = ConvMD(2, 768, 2, 1, (1, 1), (0, 0), temp_conv,
training=self.training, activation=False, bn=False, name='conv20')
# Regression(residual) map, scale = [None, 200/100, 176/120, 14]
r_map = ConvMD(2, 768, 14, 1, (1, 1), (0, 0),
temp_conv, training=self.training, activation=False, bn=False, name='conv21')
# softmax output for positive anchor and negative anchor, scale = [None, 200/100, 176/120, 1]
self.p_pos = tf.sigmoid(p_map)
#self.p_pos = tf.nn.softmax(p_map, dim=3)
self.output_shape = [cfg.FEATURE_HEIGHT, cfg.FEATURE_WIDTH]
self.cls_pos_loss = (-self.pos_equal_one * tf.log(self.p_pos + small_addon_for_BCE)) / self.pos_equal_one_sum
self.cls_neg_loss = (-self.neg_equal_one * tf.log(1 - self.p_pos + small_addon_for_BCE)) / self.neg_equal_one_sum
self.cls_loss = tf.reduce_sum( alpha * self.cls_pos_loss + beta * self.cls_neg_loss )
self.cls_pos_loss_rec = tf.reduce_sum( self.cls_pos_loss )
self.cls_neg_loss_rec = tf.reduce_sum( self.cls_neg_loss )
self.reg_loss = smooth_l1(r_map * self.pos_equal_one_for_reg, self.targets *
self.pos_equal_one_for_reg, sigma) / self.pos_equal_one_sum
self.reg_loss = tf.reduce_sum(self.reg_loss)
self.loss = tf.reduce_sum(self.cls_loss + self.reg_loss)
self.delta_output = r_map
self.prob_output = self.p_pos
def smooth_l1(deltas, targets, sigma=3.0):
sigma2 = sigma * sigma
diffs = tf.subtract(deltas, targets)
smooth_l1_signs = tf.cast(tf.less(tf.abs(diffs), 1.0 / sigma2), tf.float32)
smooth_l1_option1 = tf.multiply(diffs, diffs) * 0.5 * sigma2
smooth_l1_option2 = tf.abs(diffs) - 0.5 / sigma2
smooth_l1_add = tf.multiply(smooth_l1_option1, smooth_l1_signs) + \
tf.multiply(smooth_l1_option2, 1 - smooth_l1_signs)
smooth_l1 = smooth_l1_add
return smooth_l1
def ConvMD(M, Cin, Cout, k, s, p, input, training=True, activation=True, bn=True, name='conv'):
temp_p = np.array(p)
temp_p = np.lib.pad(temp_p, (1, 1), 'constant', constant_values=(0, 0))
with tf.variable_scope(name) as scope:
if(M == 2):
paddings = (np.array(temp_p)).repeat(2).reshape(4, 2)
pad = tf.pad(input, paddings, "CONSTANT")
temp_conv = tf.layers.conv2d(
pad, Cout, k, strides=s, padding="valid", reuse=tf.AUTO_REUSE, name=scope)
if(M == 3):
paddings = (np.array(temp_p)).repeat(2).reshape(5, 2)
pad = tf.pad(input, paddings, "CONSTANT")
temp_conv = tf.layers.conv3d(
pad, Cout, k, strides=s, padding="valid", reuse=tf.AUTO_REUSE, name=scope)
if bn:
temp_conv = tf.layers.batch_normalization(
temp_conv, axis=-1, fused=True, training=training, reuse=tf.AUTO_REUSE, name=scope)
if activation:
return tf.nn.relu(temp_conv)
else:
return temp_conv
def Deconv2D(Cin, Cout, k, s, p, input, training=True, bn=True, name='deconv'):
temp_p = np.array(p)
temp_p = np.lib.pad(temp_p, (1, 1), 'constant', constant_values=(0, 0))
paddings = (np.array(temp_p)).repeat(2).reshape(4, 2)
pad = tf.pad(input, paddings, "CONSTANT")
with tf.variable_scope(name) as scope:
temp_conv = tf.layers.conv2d_transpose(
pad, Cout, k, strides=s, padding="SAME", reuse=tf.AUTO_REUSE, name=scope)
if bn:
temp_conv = tf.layers.batch_normalization(
temp_conv, axis=-1, fused=True, training=training, reuse=tf.AUTO_REUSE, name=scope)
return tf.nn.relu(temp_conv)
if(__name__ == "__main__"):
m = MiddleAndRPN(tf.placeholder(
tf.float32, [None, 10, cfg.INPUT_HEIGHT, cfg.INPUT_WIDTH, 128]))