1, How to set utf8mb4 up
For string types in mysql, charset can be set exactly to the field.
If only one field is set utf8mb4, other fields will not be affected.
If it is set for the table, the existing field will still be utf8, and there will be more utf8 tags, and then the created field will be utf8mb4.
If it is set for the library, the existing table will still be utf8, and then the created table will be utf8mb4.
In addition, when connecting to the database, we should also indicate charset=utf8mb4. Otherwise, the connection cannot write data to the field of utf8mb4, and the reading is garbled.
Of course, tools like navicate have been optimized, and it seems that it is OK not to specify, but we need to specify it manually in the code.
2, Question
1. Why should we distinguish between utf8 and utf8mb4 when storing
It is reasonable to say that no matter whether I save a single byte or multiple bytes, they are binary in nature. You can save whatever I write. Why should there be restrictions. This is because MySQL defines the length of each field. For example, varchar(10) represents 10 characters, not bytes. Therefore, when storing data, MySQL parses it to know how many characters are in the string; When faced with 4-byte characters, MySQL will still parse according to the 3-byte encoding rules. Obviously, there will be parsing errors, so it will not be written.
MySQL added this utf8mb4 code after 5.5.3. Mb4 means most bytes 4, which is specially used to be compatible with four byte unicode. Fortunately, utf8mb4 is a superset of utf8. No other conversion is required except changing the encoding to utf8mb4. Of course, in order to save space, utf8 is generally enough.
utf8 is a character set in Mysql. It only supports UTF-8 characters with a maximum length of three bytes. It may be because there are no 4-byte characters in Unicode at the beginning of Mysql development. As for why the subsequent versions do not support UTF-8 characters with a length of 4 bytes, it should be for the sake of backward compatibility. In addition, 4-byte characters are rarely used.
2. Why distinguish between utf8 and utf8mb4 when reading
It is reasonable that I read binary, whether three or four bytes. I will show myself why when reading utf8mb4 fields, I get garbled code by using utf8 connection and normal code by using utf8mb4 connection. In fact, my computer can display four byte characters.
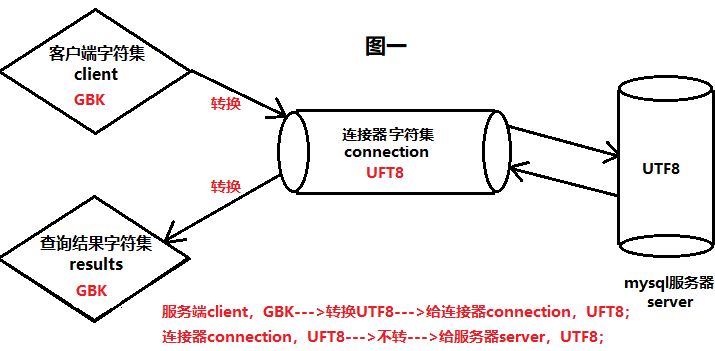
Because mysql has a connector component, which is between the client and the server for character set conversion.
Now there is a field name. In order to be compatible with emoj expression, the field is set to utf8mb4. When writing, the database connection is set to charset=utf8mb4, so it can be written normally; When reading, the database connection is set to charset=utf8, so it is garbled when reading and displaying. If it is changed to charset=utf8mb4, it can be displayed normally. That is to say, the result read by utf8 connection is not real data, but after conversion by the connector, it converts utf8mb4 into utf8, and four byte characters into three bytes, Naturally, it's garbled.
So, why is there this transcoding process?
That's because mysql supports a lot of character encoding.
mysql> show character set; +----------+-----------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+-----------------------------+---------------------+--------+ | big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 | | dec8 | DEC West European | dec8_swedish_ci | 1 | | cp850 | DOS West European | cp850_general_ci | 1 | | hp8 | HP West European | hp8_english_ci | 1 | | koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 | | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | | swe7 | 7bit Swedish | swe7_swedish_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | ujis | EUC-JP Japanese | ujis_japanese_ci | 3 | | sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 | | hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 | | tis620 | TIS620 Thai | tis620_thai_ci | 1 | | euckr | EUC-KR Korean | euckr_korean_ci | 2 | | koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 | | gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 | | greek | ISO 8859-7 Greek | greek_general_ci | 1 | | cp1250 | Windows Central European | cp1250_general_ci | 1 | | gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 | | latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 | | armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 | | cp866 | DOS Russian | cp866_general_ci | 1 | | keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 | | macce | Mac Central European | macce_general_ci | 1 | | macroman | Mac West European | macroman_general_ci | 1 | | cp852 | DOS Central European | cp852_general_ci | 1 | | latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 | | utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 | | cp1251 | Windows Cyrillic | cp1251_general_ci | 1 | | utf16 | UTF-16 Unicode | utf16_general_ci | 4 | | utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 | | cp1256 | Windows Arabic | cp1256_general_ci | 1 | | cp1257 | Windows Baltic | cp1257_general_ci | 1 | | utf32 | UTF-32 Unicode | utf32_general_ci | 4 | | binary | Binary pseudo charset | binary | 1 | | geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 | | cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 | | eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 | +----------+-----------------------------+---------------------+--------+ 40 rows in set
Collation is the collation and Maxlen is the maximum number of bytes.
Different coding rules will get different binary numbers, so correct coding conversion is necessary.
View current encoding
mysql> show variables like '%char%'; +--------------------------+--------+ | Variable_name | Value | +--------------------------+--------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | | +--------------------------+--------+
Set client encoding
mysql -h rm-m5e45006nl8xcq803ro.mysql.rds.aliyuncs.com -u adminuser -p Sls6us53 mysql> set names gbk; mysql> show variables like '%char%'; +--------------------------+--------+ | Variable_name | Value | +--------------------------+--------+ | character_set_client | gbk | | character_set_connection | gbk | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | gbk | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | | +--------------------------+--------+
When we connect to the database, charset=utf8 is internally called set names utf8.
Therefore, there are three codes representing the client, which are basically the same. The others are server-side codes.
character_set_client client
character_set_connection connector
character_ set_ The result set returned by results
Since it is the same, why should the client make three configurations? This should be seen from the data transmission process.
Connector: connects the client and server for character set conversion.
Workflow of connector:
request
character_set_client --> character_set_connection -->character_set_server
response
character_set_server --> character_set_connection --> character_set_results
Illustration