- Platform: windows10
- Interpreter: Python 3.7
Task requirements
There is an existing excel document containing target data. You need to replace the corresponding content of each line of data in the specified word and save it one by one.
Task Disassembly
First, check the word document format. You can see that the file suffix is. doc. What needs to be replaced is the English part in the red box of the body part.
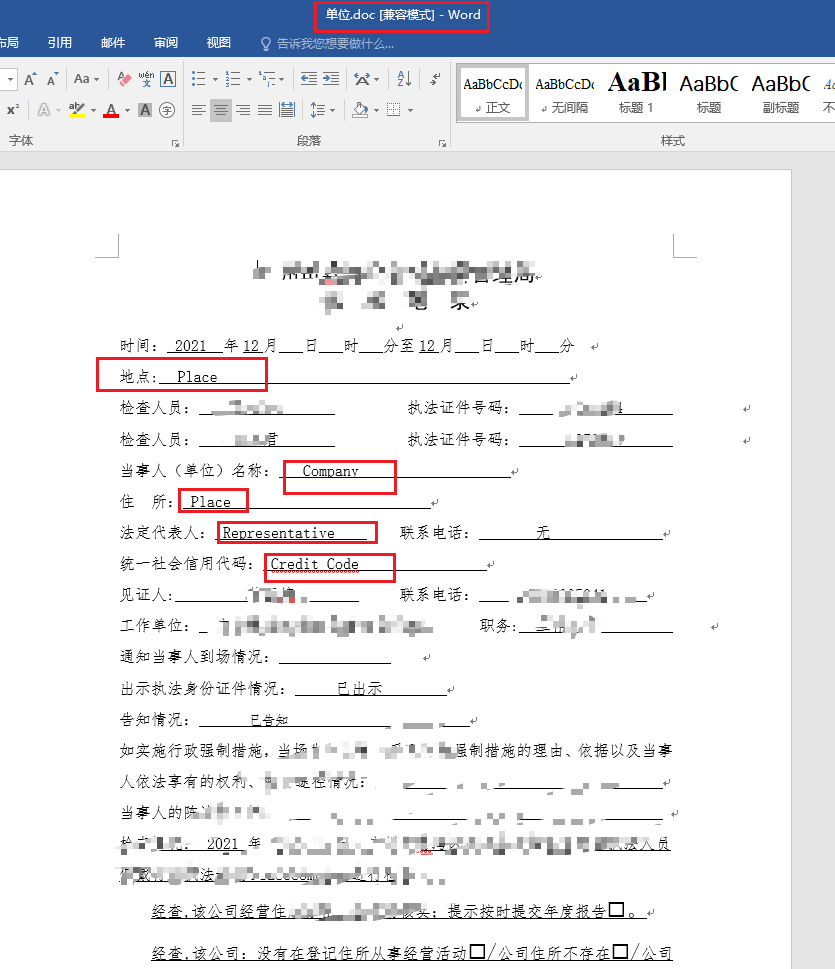
The target data is excel document, and the data under the corresponding column in excel is replaced into word document.
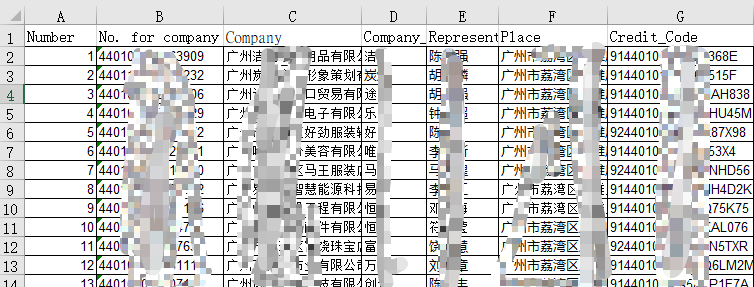
excel data is relatively regular without secondary processing. If the column name does not correspond to or does not exist in the word document, it needs to be adjusted or added. In this way, just consider how to read the doc file and replace it according to a certain logic.
Mission plan
Scheme 1: use python-docx.Document to read word documents
Before this demand, I didn't use python to operate word documents. Thank you for your help in the communication group. Although I wrote the code in step from Python+Excel+Word to produce 100 contract articles in one second, when the execution times were wrong, the target string was not replaced, etc.
- Problem 1: the module is installed incorrectly. In the article, I mistakenly thought that pip install docx was OK. When calling the Document class, I found that there was no such class under the module, so I Baidu. It should be PIP install Python docx and import docx.
- Problem 2: the python docx module cannot operate DOC documents. As mentioned above, the word documents processed this time are doc suffixes, which need to be converted to docx suffixes for normal operation. In fact, a document can be saved as a document through word software, but it is not elegant in Python programming. The main reason is that I am too lazy. At most, I copy the target file path to the code, Therefore, use win32com module to call word program to convert doc document into docx document.
- Problem 3: Python+Excel+Word makes a hundred contracts in one second. It is to locate the specific text segment for replacement. When trying for the first time, it is found that the replacement cannot succeed. Run the code step by step to locate the problem. It can be imagined that Document divides the whole word Document into multiple paragraphs. A paragraph has many lines and each line has multiple text blocks. Due to the unclear division of text blocks in each line, Chinese / English input in different ways of Chinese and English input methods will lead to the disassembly of a word, or it may be caused by a certain format in the word Document, such as underline, When there is no underline, the words are not separated. Try to replace the content with paragraphs.text. The text can be replaced successfully, but the format of the underline is discarded. Therefore, only the text method under the text block can be used for replacement. Input English with the same input method in the original word file (corresponding to the column name of Excel, it should be ensured that the string does not appear elsewhere in word, that is, Chinese is also OK. The recommended writing method: # column name #)
After solving the above problems one by one, enter the target file path and input path.
Source code:
from copy import deepcopy
from pathlib import Path
from win32com import client as wc
from docx import Document # pip install python-docx
import pandas as pd
# Python docx can't process doc documents. Use win32com to save them as docx documents
def doctransform2docx(doc_path):
docx_path = doc_path + 'x'
suffix = doc_path.split('.')[1]
assert 'doc' in suffix, 'Passed in is not word Document, please re-enter!'
if suffix == 'docx':
return Path(doc_path)
word = wc.Dispatch('Word.Application')
doc = word.Documents.Open(doc_path)
doc.SaveAs2(docx_path, 16) # docx is 16
doc.Close()
word.Quit()
return Document(docx_path)
# Replace the specific characters in docx. Since the run method has poor display effect in formatted docx files, fill the space occupied by English characters for the text in docx
def replace_docx(name, values, wordfile, path_name = 'Company'):
wordfile_copy = deepcopy(wordfile) # Prevent the original file from being tampered with, and deepcopy is a copy
for col_name, value in zip(name, values):
if col_name == 'Company':
path_name = str(value)
for paragraphs in wordfile_copy.paragraphs:
for run in paragraphs.runs:
run.text = run.text.replace(col_name, str(value))
# The docx document is replaced and saved as. Be sure to use the absolute path
wordfile_copy.save(f'{save_folder}/{path_name}.docx')
if __name__ == '__main__':
# Define the file path to process
doc_path = r"D:\solve_path\Company.doc"
excel_path = r"D:\solve_path\information.xls"
save_folder = Path('D:/docx_save')
save_folder.mkdir(parents=True, exist_ok=True) # Automatically create a folder when it does not exist
# Get excel data
data = pd.read_excel(excel_path)
wordfile = doctransform2docx(doc_path)
data_save = data.apply(lambda x: replace_docx(x.index, x.values, wordfile), axis=1)
When I thought I was finished, the problem came and the box in the original file was gone (omitted!!!)
design sketch:

I think there must be a corresponding solution in Python docx, but I tried for the first time. The source code is like a Book of heaven. After calling the method many times, I found that one of the parameters is output, wordfile.part.blob:
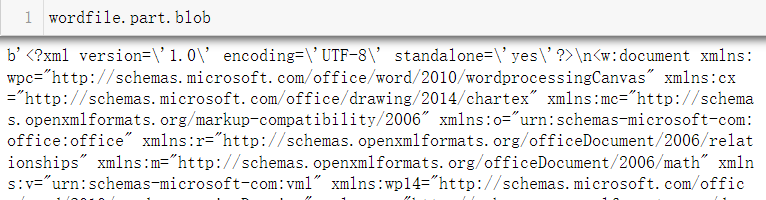
The output reminds me of the xml file at the beginning of the file I saw when decrypting excel. Then I first tried to replace the text in it. I thought it would be like run.text = run.text.replace(col_name, str(value)). However, an error was reported and modification is prohibited.

Scheme 2: zipfile to skillfully solve word documents
Just when I thought there was no other way, I gave it up. Baidu Encyclopedia helped me:
The docx document is essentially an XML file, emmmm. It's wonderful. In order to extract the pictures in xlsx, the xlsx file was decompressed and then extracted. As expected, it is feasible. The replaced main file is the document.xml file in the word folder
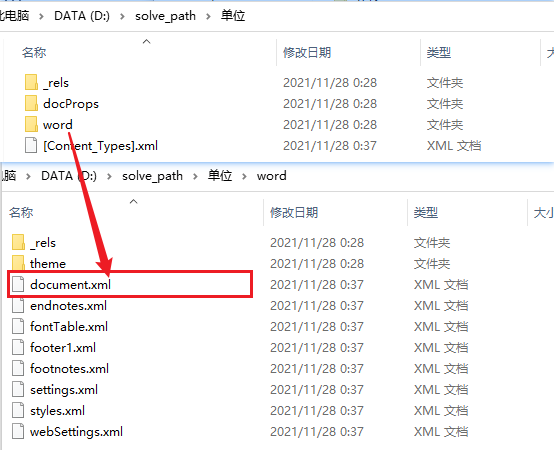
Of course, before writing the code, first try whether you can manually restore to docx. Restore with 7z default parameters fails. After many searches, you can compress with zip type. There is no limit to the software. Manual decompression and replacement character compression are successful, and start typing the code.
In addition to the habit of reading excel files with pandas, there is no need to install other packages. They are built-in packages in current Python 3.7.
Use zipfile to decompress the compressed class file. This article comes from: How to compress and decompress files in python , the article is very detailed. I only rewrite os.path to pathlib.
However, there is a problem when compressing and restoring the files in the directory to docx documents:
- Question 1: How to compress and decompress files in python The compressed file type in is
Zipfile.zip_flattened compresses all traversed files into one directory, which causes the file hierarchy mismatch in the restored docx, and the docx reading fails. Use zipfile.zlib.flattened to successfully compress by hierarchy. - Problem 2: when saving a zipfile compressed file, there should be a file name and its alias, and the alias cannot be an absolute path. In order to restore normally, the original name should also be used, which is f.write (file path, file path alias) in the code
Source code:
from win32com import client as wc
from shutil import rmtree
import zipfile
from copy import deepcopy
from pathlib import Path
import pandas as pd
# The doc document does not contain the required xml file. Use win32com to save it as a docx document
def doctransform2docx(doc_path):
docx_path = doc_path + 'x'
suffix = doc_path.split('.')[1]
assert 'doc' in suffix, 'Passed in is not word Document, please re-enter!'
if suffix == 'docx':
return Path(doc_path)
word = wc.Dispatch('Word.Application')
doc = word.Documents.Open(doc_path)
doc.SaveAs2(docx_path, 16) # docx is 16
doc.Close()
word.Quit()
return Path(docx_path)
# docx document decompression
def docx_unzip(docx_path):
docx_path = Path(docx_path) if isinstance(docx_path, str) else docx_path
upzip_path = docx_path.with_name(docx_path.stem)
with zipfile.ZipFile(docx_path, 'r') as f:
for file in f.namelist():
f.extract(file, path=upzip_path)
xml_path = upzip_path.joinpath('word/document.xml')
with xml_path.open(encoding='utf-8') as f:
xml_file = f.read()
return upzip_path, xml_path, xml_file
# Compress all files in the folder into docx documents
def docx_zipped(docx_path, zipped_path):
docx_path = Path(docx_path) if isinstance(docx_path, str) else docx_path
with zipfile.ZipFile(zipped_path, 'w', zipfile.zlib.DEFLATED) as f:
for file in docx_path.glob('**/*.*'):
f.write(file, file.as_posix().replace(docx_path.as_posix() + '/', ''))
# Delete the generated unzipped folder
def remove_folder(path):
path = Path(path) if isinstance(path, str) else path
if path.exists():
rmtree(path)
else:
raise "The system cannot find the specified file"
# Replace the specific characters in docx and re save document.xml to the directory to be compressed
def replace_docx(name, values, xml_file, xml_path, unzip_path, path_name='Company'):
xml_path = Path(xml_path) if isinstance(xml_path, str) else xml_path
xml_file_copy = deepcopy(xml_file) # Deep copy xml content
for col_name, value in zip(name, values):
if col_name == 'Company':
path_name = str(value)
xml_file_copy = xml_file_copy.replace(col_name, str(value))
with xml_path.open(mode='w', encoding='utf-8') as f:
f.write(xml_file_copy)
# After the xml document is replaced, it is recompressed by zipfile and saved as a docx document
docx_zipped(unzip_path, f'{save_folder}/{path_name}.docx')
if __name__ == '__main__':
# Define the file path to process
doc_path = r"D:\solve_path\Company.doc"
excel_path = r"D:\solve_path\information.xls"
save_folder = Path('D:/docx_save')
save_folder.mkdir(parents=True, exist_ok=True) # Automatically create a folder when it does not exist
# Get excel data
data = pd.read_excel(excel_path)
docx_path = doctransform2docx(doc_path)
unzip_path, xml_path, xml_file = docx_unzip(docx_path)
data_save = data.apply(lambda x: replace_docx(x.index, x.values, xml_file, xml_path, unzip_path), axis=1)
remove_folder(unzip_path)
Open the generated file, the box does not disappear, and the underline is also in.

summary
After several attempts, my knowledge is not deep. I stumbled to find a scheme that can replace the string in docx and will not change the original format. I believe there will be a better scheme. But I didn't find it at this time. Time keeps moving forward, and I shouldn't fall down in order to achieve common prosperity. If you have any questions, please leave a message in the comment area.
Made on 28 November 2021