The first few classes you need to understand
StreamingContext
How to read data
DStream
Processing data functions There are many RDD s stored in DStream
PairDStreamFunctions
When the data type processed is a tuple,
Automatic implicit conversion of DStream to PairDStream Functions
RDD
Output function, which saves the results to the external system
def foreachFunc: (RDD[T], Time) => Unit = {
(rdd: RDD[T], time: Time) => {
....
}}
NC (netcat) tool installation
introduce

install
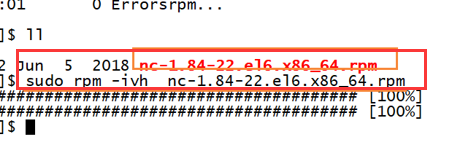
test
Monitor: nc-v host name 9999 Send: nc-lk 9999
Real-time word frequency statistics
Open the nc service beforehand and test that it can communicate
Code Implementation Method 1: Using DStream Function
import java.sql.{Connection, DriverManager, PreparedStatement}
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.dstream.ReceiverInputDStream
object Wordount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[3]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.sparkContext.setLogLevel("WARN")
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("host name", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.foreachRDD(rdd=>{
if(!rdd.isEmpty()){
println("------------------------------")
rdd.coalesce(1).foreachPartition(
item=>{
Class.forName("com.mysql.jdbc.Driver")
val url = "jdbc:mysql://Host name / test“
val userName = "root"
val password = "123456"
var conn: Connection = null
try {
//Get an instance of a database connection
conn = DriverManager.getConnection(url, userName, password)
val pst: PreparedStatement = conn.prepareStatement("INSERT INTO tb_wordcount(word,count) VALUES(?,?)")
//insert data
item.foreach {
case (k,v) => {
println(s"word=$k,count=$v")
pst.setString(1,k)
pst.setInt(2,v)
//Data is executed once a day
pst.executeUpdate()
}
}
} catch {
case e:Exception =>e.printStackTrace()
} finally {
if(conn !=null) conn.close()
}
}
)
}
})
ssc.start()
ssc.awaitTermination()
}
}
Code Implementation Method 2: Use DStream's transform function to convert higher-order functions in RDD
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[3]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.sparkContext.setLogLevel("WARN")
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("bigdata-hpsk01.huadian.com", 9999)
//Use RDD functions as much as possible. Using DStream functions may involve checkpoints that cannot be restored.
val wordCountStreaming: DStream[(String, Int)] = lines.transform(rdd=>{
val wordCount =rdd.flatMap(_.split("\\s+"))
.filter(_.trim.length>0)
.map((_,1))
.reduceByKey(_ + _)
wordCount
})
wordCountStreaming.print()
ssc.start()
ssc.awaitTermination()
}
}