1. Preface
elsaticsearch version is 6.8.3. The Java API used is based on Java High Level REST Client
2. data

3. InitClient
Used to initialize clients
package com.htkj.elasticsearch; import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; public class InitClient { public static RestHighLevelClient getClient(){ RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( // new HttpHost("htkj101", 9200, "http"), // new HttpHost("htkj102", 9200, "http"), new HttpHost("htkj224", 9200, "http") ) ); return client; }; }
4. query
4.1 query all
Query all
private static void queryAll(){ try(RestHighLevelClient client = InitClient.getClient()){ //Create SearchRequest SearchRequest searchRequest = new SearchRequest(); //Specify the index as poems searchRequest.indices("poems"); //Create SearchSourceBuilder SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //Create BoolQueryBuilder to add conditions BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); //Sort in ascending order of id in index searchSourceBuilder.sort(new FieldSortBuilder("_uid").order(SortOrder.ASC)); //paging searchSourceBuilder.from(0); searchSourceBuilder.size(20); //Put query criteria into searchSourceBuilder searchSourceBuilder.query(boolQueryBuilder); //searchRequest parsing searchSourceBuilder searchRequest.source(searchSourceBuilder); //Get SearchResponse SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); //Get fragmentation results SearchHits hits = searchResponse.getHits(); SearchHit[] searchHits = hits.getHits(); //Get data for (SearchHit hit : searchHits) { String sourceAsString = hit.getSourceAsString(); System.out.println(sourceAsString); } //Close connection client.close(); } catch (IOException e) { e.printStackTrace(); } }
Result:

4.2match
match query is mainly for matching query under word segmentation. By default, it is based on space
Because I don't set Chinese word segmentation here, the effect is not very good actually
Example 1:
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("content", "Three thousand"); boolQueryBuilder.must(matchQueryBuilder);
Here, you want to find "three thousand" content under the content field, and the desired result should only be to return "sunshine censer produces purple smoke, watching the waterfall hanging in front of Sichuan". Three thousand feet down, the Milky way is believed to have set in nine days. "
But the result is this:

It can be seen that three results have been returned. Only wanglushan waterfall meets the two contents of "three" and "thousand". Only "three" is satisfied when drinking alone under the moon, and "thousand" is satisfied on the first day
4.3term
term query is a full match query, which can only be found if the content of the field is fully matched,
If you use term query, you must use the keyword attribute, otherwise it will be segmented and cannot be found
Example 1: finding the author is Li Bai's result
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("author.keyword", "Li Bai"); boolQueryBuilder.must(termQueryBuilder);
Result:

4.4wildcard
Wildcard query is a wildcard query, equivalent to like in mysql, which also uses the keyword attribute
Example 1: find the content of "3000" in the poem,
WildcardQueryBuilder wildcardQueryBuilder = QueryBuilders.wildcardQuery("content.keyword", "*Three thousand*"); boolQueryBuilder.must(wildcardQueryBuilder);
Result:
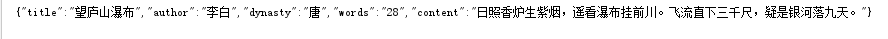
You can see that only one result is returned, which is the difference between wildcard and match
4.5prefix
Prefix query is a prefix query and also uses the keyword attribute
Example 1: find all authors with surname Li
PrefixQueryBuilder prefixQueryBuilder = QueryBuilders.prefixQuery("author.keyword", "Plum"); boolQueryBuilder.must(prefixQueryBuilder);
Result:

4.6 nested query
For multi criteria queries, sometimes you need to create multiple QueryBuilders.boolQuery() to nest
Example 1: find "month" or "wine" and "rain" in the content field
select * from poems where content like 'month' or(content like 'Alcohol' and content like'rain')
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); BoolQueryBuilder boolQueryBuilderContent = QueryBuilders.boolQuery(); WildcardQueryBuilder wildcardQueryBuilderMoon = QueryBuilders.wildcardQuery("content.keyword", "*month*"); WildcardQueryBuilder wildcardQueryBuilderAlcohol = QueryBuilders.wildcardQuery("content.keyword", "*Alcohol*"); WildcardQueryBuilder wildcardQueryBuilderRainy = QueryBuilders.wildcardQuery("content.keyword", "*rain*"); boolQueryBuilderContent.must(wildcardQueryBuilderAlcohol).must(wildcardQueryBuilderRainy); boolQueryBuilder.should(wildcardQueryBuilderMoon).should(boolQueryBuilderContent);
Result:

5. Aggregate statistics
Example 1: count the number of poems of each poet
select author, count(*) as author_count from poems group by author
private static void aggregation(){ try(RestHighLevelClient client = InitClient.getClient()){ SearchRequest searchRequest = new SearchRequest(); searchRequest.indices("poems"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //Specify the count. The author "count here can be named at will TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms("author_count").field("author.keyword"); //Put aggregationBuilder in searchSourceBuilder searchSourceBuilder.aggregation(aggregationBuilder); searchRequest.source(searchSourceBuilder); SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); //Get count. The author "count here corresponds to the name above Terms terms = searchResponse.getAggregations().get("author_count"); //Get results for (Terms.Bucket bucket : terms.getBuckets()) { System.out.println("author=" + bucket.getKey()+" count="+bucket.getDocCount()); } client.close(); } catch (IOException e) { e.printStackTrace(); } }
Result:

Example 2: count the number of poems of each poet in each dynasty
select dynasty,author,count(*) as author_count from poems group by dynasty,author
private static void aggregation(){ try(RestHighLevelClient client = InitClient.getClient()){ SearchRequest searchRequest = new SearchRequest(); searchRequest.indices("poems"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //Set the aggregated fields dynasty and author TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms("dynasty_count").field("dynasty.keyword"); TermsAggregationBuilder aggregationBuilder2 = AggregationBuilders.terms("author_count").field("author.keyword"); //aggregationBuilder2 is a sub aggregation of aggregationBuilder searchSourceBuilder.aggregation(aggregationBuilder.subAggregation(aggregationBuilder2)); searchRequest.source(searchSourceBuilder); SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); //Get Dynasty count Terms terms = searchResponse.getAggregations().get("dynasty_count"); //Get results for (Terms.Bucket bucket : terms.getBuckets()) { System.out.println("dynasty=" + bucket.getKey()+" count="+bucket.getDocCount()); //Get author "count Terms terms2 = bucket.getAggregations().get("author_count"); for (Terms.Bucket bucket2 : terms2.getBuckets()) { System.out.println("author=" + bucket2.getKey()+ "; Number=" + bucket2.getDocCount()); } } client.close(); } catch (IOException e) { e.printStackTrace(); } }
Result:
