The data set contains six kinds of garbage, namely, cardboard, glass, metal, paper, plastic and other waste products. The amount of data is small and only for learning.
The preparation of data set label includes dividing data set into training set and test set, and making label file. Code utils.py
import os
import shutil
import json
path="e://Dataset / / garbage "classification" ා this path is the directory of the six categories in the above figure, which can be modified according to its own dataset path.
classes=[garbage for garbage in os.listdir(path)]
if os.path.exists(os.path.join(os.getcwd(),'train'))==False:
os.makedirs(os.path.join(os.getcwd(),'train'))
if os.path.exists(os.path.join(os.getcwd(),'val'))==False:
os.makedirs(os.path.join(os.getcwd(),'val'))
f = open("garbage_train.json", 'w')
g = open("garbage_val.json", 'w')
for garbage in classes:
s = 0
for imgname in os.listdir(os.path.join(path,garbage)):
if s%7!=0:
data = {'name': imgname, 'label':classes.index(garbage)}
jsondata = json.dumps(data)
f.write(jsondata)
shutil.copy(os.path.join(path, garbage, imgname),os.path.join(os.getcwd(),'train'))
else:
data = {'name': imgname, 'label': classes.index(garbage)}
jsondata = json.dumps(data)
g.write(jsondata)
shutil.copy(os.path.join(path, garbage, imgname),os.path.join(os.getcwd(),'val'))
s+=1Running the above code will generate the following folder.

Next, we write a data set preprocessing class. data.py. Root is the root directory of the data set processed in the above figure, and data json is two json folders.
from PIL import Image
import torch
import os
import json
class MyDataset(torch.utils.data.Dataset): # Create your own class: MyDataset, which is the inherited torch.utils.data.Dataset
def __init__(self, root, datajson, transform=None, target_transform=None): # Initialize some parameters that need to be passed in
super(MyDataset, self).__init__()
fh = open(datajson, 'r') # Open the text and read the content according to the path and txt text parameters passed in
load_dict = json.load(fh)
imgs = [] # Create an empty list called img for later loading
for line in load_dict: # Loop through the contents of the txt text by line
#line = line.rstrip()# Delete the specified character at the end of the string string on this line. This method describes how to query python in detail.
#words = line.split() # Slice the string by specifying the separator, which defaults to all empty characters, including space, line feed, tab, etc.
imgs.append((line['name'], int(line['label']))) # Read the contents of txt into the imgs list and save them. The specific words depends on the contents of txt.
self.root=root
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
fn, label = self.imgs[index] # fn It's a picture. path #fn and label respectively obtain imgs[index], that is, the information of word[0] and word[1] in each line just now.
img = Image.open(os.path.join(self.root,fn)).convert('RGB') # according to path Read the picture. from PIL import Image # Read pictures by path
if self.transform is not None:
img = self.transform(img) # transform or not
return img, label # Return is very important. What is the content of return? What can we get when we cycle through each batch in training?
def __len__(self): # This function must also be written. It returns the length of the dataset, that is, the number of images, which should be distinguished from the length of the loader.
return len(self.imgs)Define the RESNET network again. resnet.py, it needs to be explained here. Because the data set is not large enough, many pictures are not more than 224. I plan to input 112. Here are a variety of RESNET series options. I use the simplest resnet18.
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
"""Basic Block for resnet 18 and resnet 34
"""
#BasicBlock and BottleNeck block
#have different output size
#we use class attribute expansion
#to distinct
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
#residual function
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
#shortcut
self.shortcut = nn.Sequential()
#the shortcut output dimension is not the same with residual function
#use 1*1 convolution to match the dimension
if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class BottleNeck(nn.Module):
"""Residual block for resnet over 50 layers
"""
expansion = 4
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, stride=stride, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BottleNeck.expansion, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion),
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels * BottleNeck.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BottleNeck.expansion, stride=stride, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class ResNet(nn.Module):
def __init__(self, block, num_block, num_classes=6):
super().__init__()
self.in_channels = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=1,padding=1, bias=False),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True))
#we use a different inputsize than the original paper
#so conv2_x's stride is 1
self.conv2_x = self._make_layer(block, 64, num_block[0], 1)
self.conv3_x = self._make_layer(block, 128, num_block[1], 2)
self.conv4_x = self._make_layer(block, 256, num_block[2], 2)
self.conv5_x = self._make_layer(block, 512, num_block[3], 2)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride):
"""make resnet layers(by layer i didnt mean this 'layer' was the
same as a neuron netowork layer, ex. conv layer), one layer may
contain more than one residual block
Args:
block: block type, basic block or bottle neck block
out_channels: output depth channel number of this layer
num_blocks: how many blocks per layer
stride: the stride of the first block of this layer
Return:
return a resnet layer
"""
# we have num_block blocks per layer, the first block
# could be 1 or 2, other blocks would always be 1
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
output = self.conv1(x)
output = self.conv2_x(output)
output = self.conv3_x(output)
output = self.conv4_x(output)
output = self.conv5_x(output)
output = self.avg_pool(output)
output = output.view(output.size(0), -1)
output = self.fc(output)
return output
def resnet18():
""" return a ResNet 18 object
"""
return ResNet(BasicBlock, [2, 2, 2, 2])
def resnet34():
""" return a ResNet 34 object
"""
return ResNet(BasicBlock, [3, 4, 6, 3])
def resnet50():
""" return a ResNet 50 object
"""
return ResNet(BottleNeck, [3, 4, 6, 3])
def resnet101():
""" return a ResNet 101 object
"""
return ResNet(BottleNeck, [3, 4, 23, 3])
def resnet152():
""" return a ResNet 152 object
"""
return ResNet(BottleNeck, [3, 8, 36, 3])If you want to train more than one class, you can modify num'u classes = 6. If you want to train 224 size pictures, you can change the parameter strip in self.conv'u 1 to 2.
As I said above, my input image is 112, so the stripe is set to 1.
Set the super parameter global settings.py before the official training
import os from datetime import datetime #directory to save weights file CHECKPOINT_PATH = 'checkpoint' #total training epoches EPOCH = 200 MILESTONES = [60, 120, 160] #initial learning rate #INIT_LR = 0.1 #time of we run the script TIME_NOW = datetime.now().isoformat() #tensorboard log dir LOG_DIR = 'runs' #save weights file per SAVE_EPOCH epoch SAVE_EPOCH = 10
Next is direct training, train.py
import sys
import argparse
from datetime import datetime
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.autograd import Variable
from tensorboardX import SummaryWriter
import glabol_settings as settings
def get_network(args, use_gpu=True):
if args.net == 'resnet18':
from models.resnet import resnet18
net = resnet18()
elif args.net == 'resnet34':
from models.resnet import resnet34
net = resnet34()
elif args.net == 'resnet50':
from models.resnet import resnet50
net = resnet50()
elif args.net == 'resnet101':
from models.resnet import resnet101
net = resnet101()
elif args.net == 'resnet152':
from models.resnet import resnet152
net = resnet152()
from data import *
path=os.getcwd()
class WarmUpLR(_LRScheduler):
"""warmup_training learning rate scheduler
Args:
optimizer: optimzier(e.g. SGD)
total_iters: totoal_iters of warmup phase
"""
def __init__(self, optimizer, total_iters, last_epoch=-1):
self.total_iters = total_iters
super().__init__(optimizer, last_epoch)
def get_lr(self):
"""we will use the first m batches, and set the learning
rate to base_lr * m / total_iters
"""
return [base_lr * self.last_epoch / (self.total_iters + 1e-8) for base_lr in self.base_lrs]
def train(epoch):
net.train()
for batch_index, (images, labels) in enumerate(train_set):
if epoch <= args.warm:
warmup_scheduler.step()
print('label:',labels.shape)
images = Variable(images)
labels = Variable(labels)
labels = labels.cuda()
images = images.cuda()
optimizer.zero_grad()
outputs = net(images)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
n_iter = (epoch - 1) * len(train_set) + batch_index + 1
last_layer = list(net.children())[-1]
for name, para in last_layer.named_parameters():
if 'weight' in name:
writer.add_scalar('LastLayerGradients/grad_norm2_weights', para.grad.norm(), n_iter)
if 'bias' in name:
writer.add_scalar('LastLayerGradients/grad_norm2_bias', para.grad.norm(), n_iter)
print('Training Epoch: {epoch} [{trained_samples}/{total_samples}]\tLoss: {:0.4f}\tLR: {:0.6f}'.format(
loss.item(),
optimizer.param_groups[0]['lr'],
epoch=epoch,
trained_samples=batch_index * args.b + len(images),
total_samples=len(train_set.dataset)
))
#update training loss for each iteration
writer.add_scalar('Train/loss', loss.item(), n_iter)
for name, param in net.named_parameters():
layer, attr = os.path.splitext(name)
attr = attr[1:]
writer.add_histogram("{}/{}".format(layer, attr), param, epoch)
def eval_training(epoch):
net.eval()
test_loss = 0.0 # cost function error
correct = 0.0
for (images, labels) in test_set:
images = Variable(images)
labels = Variable(labels)
images = images.cuda()
labels = labels.cuda()
outputs = net(images)
loss = loss_function(outputs, labels)
test_loss += loss.item()
_, preds = outputs.max(1)
correct += preds.eq(labels).sum()
print('Test set: Average loss: {:.4f}, Adduracy: {:.4f}'.format(
test_loss / len(test_set.dataset),
correct.float() / len(test_set.dataset)
))
print()
#add informations to tensorboard
writer.add_scalar('Test/Average loss', test_loss / len(test_set.dataset), epoch)
writer.add_scalar('Test/Adduracy', correct.float() / len(test_set.dataset), epoch)
return correct.float() / len(test_set.dataset)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-net', type=str, default="resnet18", help='net type')
parser.add_argument('-gpu', type=bool, default=True, help='use gpu or not')
parser.add_argument('-w', type=int, default=2, help='number of workers for dataloader')
parser.add_argument('-b', type=int, default=8, help='batch size for dataloader')
parser.add_argument('-s', type=bool, default=True, help='whether shuffle the dataset')
parser.add_argument('-warm', type=int, default=1, help='warm up training phase')
parser.add_argument('-lr', type=float, default=0.001, help='initial learning rate')
args = parser.parse_args()
net = get_network(args, use_gpu=args.gpu)
#data preprocessing:
mean = [0.5071, 0.4867, 0.4408]
stdv = [0.2675, 0.2565, 0.2761]
train_transforms = transforms.Compose([
transforms.RandomCrop(112),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=stdv),
])
test_transforms = transforms.Compose([
transforms.RandomCrop(112),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=stdv),
])
# Datasets
train_set = MyDataset(root='****/train_img',
datajson='**/train.json', transform=train_transforms)
test_set = MyDataset(root='**/val_img',
datajson='**/val.json', transform=test_transforms)
train_set = DataLoader(
train_set, shuffle=True, num_workers=1, batch_size=8)
test_set= DataLoader(
test_set, shuffle=True, num_workers=1, batch_size=8)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=0.9, weight_decay=5e-4)
train_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=settings.MILESTONES, gamma=0.2) #learning rate decay
iter_per_epoch = len(train_set)
warmup_scheduler = WarmUpLR(optimizer, iter_per_epoch * args.warm)
checkpoint_path = os.path.join(settings.CHECKPOINT_PATH, args.net, 'lj')
#use tensorboard
if not os.path.exists(settings.LOG_DIR):
os.mkdir(settings.LOG_DIR)
log_dir = os.path.join(
settings.LOG_DIR, args.net,'lj')
print(log_dir)
writer = SummaryWriter(log_dir)
input_tensor = torch.Tensor(8, 3, 112, 112).cuda()
print("done")
#writer.add_graph(net, Variable(input_tensor, requires_grad=True))
#create checkpoint folder to save model
if not os.path.exists(checkpoint_path):
os.makedirs(checkpoint_path)
checkpoint_path = os.path.join(checkpoint_path, '{net}-{epoch}-{type}.pth')
best_add = 0.0
for epoch in range(1, settings.EPOCH):
if epoch > args.warm:
train_scheduler.step(epoch)
train(epoch)
add = eval_training(epoch)
#start to save best performance model after learning rate decay to 0.01
if epoch > settings.MILESTONES[1] and best_add < add:
torch.save(net.state_dict(), checkpoint_path.format(net=args.net, epoch=epoch, type='best'))
best_add = add
continue
if not epoch % settings.SAVE_EPOCH:
torch.save(net.state_dict(), checkpoint_path.format(net=args.net, epoch=epoch, type='regular'))
writer.close()After the training, we get the model saved in checkpoints path, resnet18.pth.
Test set to test the effect of a single demo, demo.py
import argparse
#from dataset import *
#from skimage import io
from matplotlib import pyplot as plt
import torch
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.autograd import Variable
import gloal_settings as settings
from PIL import Image
import torchvision.transforms as transforms
import glabol_settings as settings
def get_network(args, use_gpu=True):
if args.net == 'resnet18':
from models.resnet import resnet18
net = resnet18()
elif args.net == 'resnet34':
from models.resnet import resnet34
net = resnet34()
elif args.net == 'resnet50':
from models.resnet import resnet50
net = resnet50()
elif args.net == 'resnet101':
from models.resnet import resnet101
net = resnet101()
elif args.net == 'resnet152':
from models.resnet import resnet152
net = resnet152()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-net', type=str, default="resnet18", help='net type')
parser.add_argument('-weights', type=str, default="checkpoint/resnet18/lj/resnet18.pth", help='the weights file you want to test')
parser.add_argument('-gpu', type=bool, default=True, help='use gpu or not')
#parser.add_argument('-w', type=int, default=2, help='number of workers for dataloader')
#parser.add_argument('-b', type=int, default=16, help='batch size for dataloader')
#parser.add_argument('-s', type=bool, default=True, help='whether shuffle the dataset')
args = parser.parse_args()
net = get_network(args)
net.load_state_dict(torch.load(args.weights), args.gpu)
print(net)
net.eval()
correct_1 = 0.0
correct_5 = 0.0
total = 0
transform_test = transforms.Compose([
transforms.RandomCrop(112),
transforms.ToTensor(),
transforms.Normalize(settings.CIFAR100_TRAIN_MEAN,settings.CIFAR100_TRAIN_STD)
])
imgs=Image.open("test.jpg")
img=transform_test(imgs)
img=img.unsqueeze(0)
image = Variable(img).cuda()
print(image.shape)
import time
#label = Variable(img).cuda()
start=time.time()
output = net(image)
print(time.time()-start)
print(output)
_, pred = output.topk(1, 1, largest=True, sorted=True)
print(class_car[pred[0].item()])
imgs.show()Let me test one!
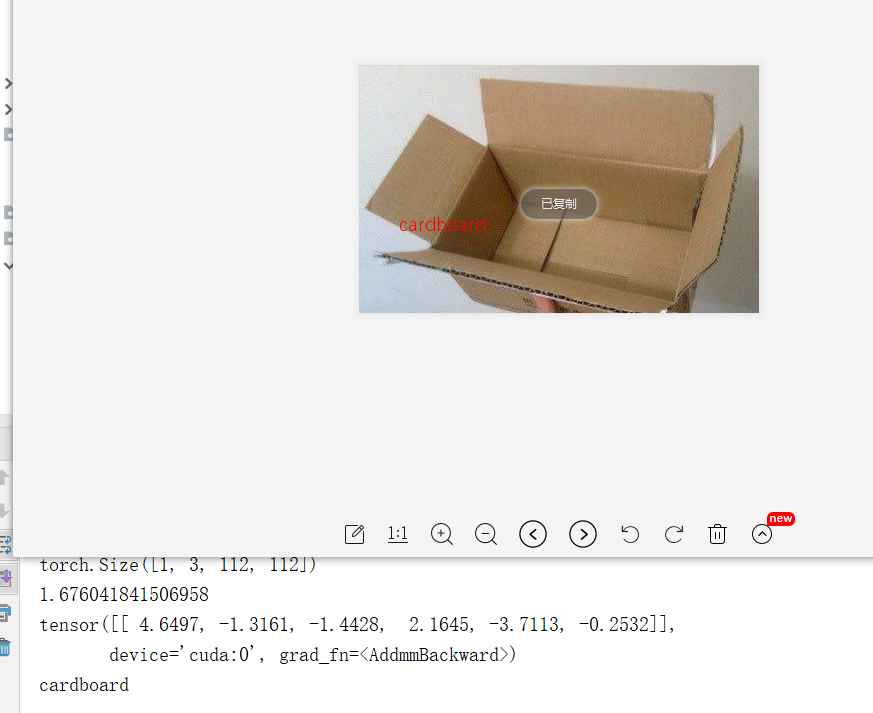
Identified as cardboard. If you are interested, please leave a message. I will send the data set and training model pth file later.