Configure python 2.7
bs4 requests
Install sudo pip install bs4 with pip
sudo pip install requests
Brief description of the use of bs4 because it is crawling the web page, so we introduce find and find_all
The difference between find_all and find_all is that different find returns the first tag and the content in the tag that matches it.
find_all returns a list
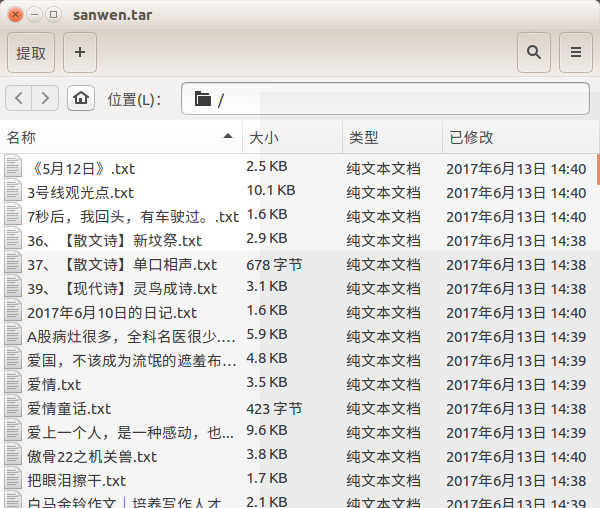
For example, we write a test.html to test the difference between find and find_all. The contents are as follows:
<html> <head> </head> <body> <div id="one"><a></a></div> <div id="two"><a href="#">abc</a></div> <div id="three"><a href="#">three a</a><a href="#">three a</a><a href="#">three a</a></div> <div id="four"><a href="#">four<p>four p</p><p>four p</p><p>four p</p> a</a></div> </body> </html>
Then the code for test.py is:
from bs4 import BeautifulSoup import lxml if __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('div') print s.find_all('div') print "------------------------------" print s.find('div',id='one') print s.find_all('div',id='one') print "------------------------------" print s.find('div',id="two") print s.find_all('div',id="two") print "------------------------------" print s.find('div',id="three") print s.find_all('div',id="three") print "------------------------------" print s.find('div',id="four") print s.find_all('div',id="four") print "------------------------------"
After running, we can see that the difference between the two is not very significant when we get a set of tags, and the difference between the two will be shown when we get a set of tags.
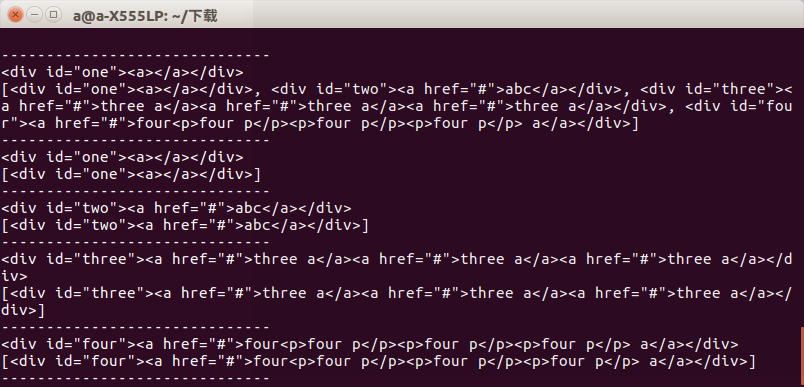
So when we use it, we should pay attention to what is the bottom line, otherwise there will be errors.
The next step is to get web information through requests. I don't quite understand why people write hearts and other things.
I visited the web page directly, got several classified secondary pages of the prose Web through get, and then crawled all the pages through a group of tests.
def get_html(): url = "https://www.sanwen.net/" two_html = ['sanwen','shige','zawen','suibi','rizhi','novel'] for doc in two_html: i=1 if doc=='sanwen': print "running sanwen -----------------------------" if doc=='shige': print "running shige ------------------------------" if doc=='zawen': print 'running zawen -------------------------------' if doc=='suibi': print 'running suibi -------------------------------' if doc=='rizhi': print 'running ruzhi -------------------------------' if doc=='nove': print 'running xiaoxiaoshuo -------------------------' while(i<10): par = {'p':i} res = requests.get(url+doc+'/',params=par) if res.status_code==200: soup(res.text) i+=i
In this part of the code, I have not processed res.status_code which is not 200. The problem is that there will be no display errors and the crawled content will be lost. Then we analyze the website of Prose Web and find that it is www.sanwen.net/rizhi/&p=1.
The maximum value of p is 10, which is not very clear. Most of the last tray climbing was 100 pages. After calculating, we will analyze it again. Then get the content of each page through get method.
After getting the content of each page, I will analyze the author and the title code.
def soup(html_text): s = BeautifulSoup(html_text,'lxml') link = s.find('div',class_='categorylist').find_all('li') for i in link: if i!=s.find('li',class_='page'): title = i.find_all('a')[1] author = i.find_all('a')[2].text url = title.attrs['href'] sign = re.compile(r'(//)|/') match = sign.search(title.text) file_name = title.text if match: file_name = sign.sub('a',str(title.text))
When you get the title, there is a pit daddy. Why do you write prose with slash? Not only add one but also add two. This problem directly causes the file name to be wrong when I write the file later. So write regular expressions. I'll change it for you.
Finally, it is to get the prose content, through the analysis of each page, get the article address, and then get the content directly. Originally, I wanted to get it directly by changing the page address one by one, which is also easy.
def get_content(url): res = requests.get('https://www.sanwen.net'+url) if res.status_code==200: soup = BeautifulSoup(res.text,'lxml') contents = soup.find('div',class_='content').find_all('p') content = '' for i in contents: content+=i.text+'\n' return content
Finally, write the file to save ok
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
The problem is that I don't know why some proses have been lost and I can only get about 400 articles. This is much worse than the prose articles on Prose. But it's really a page-by-page acquisition. I hope you can help me with this problem. Maybe we should deal with the inaccessibility of web pages. Of course, I think it has something to do with the broken web in my dormitory, but f = open(file_name+'.txt','w').
print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
Nearly the rendering
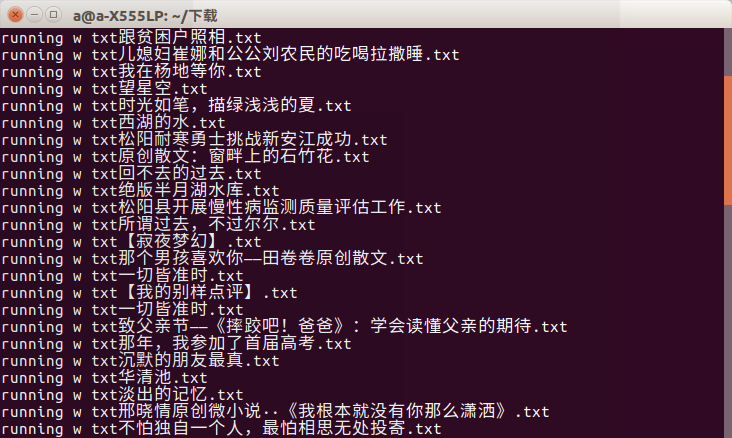
Can there be a timeout phenomenon, it can only be said that university must choose a good network ah!
Make a little progress every day, hoping that the bad dog can stay away from me...