Demand background
The business system stores all kinds of reports and statistical data in ES. Due to historical reasons, the system makes statistics in full amount every day. As time goes on, the data storage space of ES is under great pressure. At the same time, because the use of ES index is not well planned, some indexes even exceed the maximum number of documents. The challenge for the operation and maintenance personnel is to solve this problem at the lowest cost. The following example of Intranet development and test environment uses python script to solve this problem.
Each Elasticsearch shard is a Lucene index. There is a maximum number of documents you can have in a single Lucene index. As of LUCENE-5843, the limit is 2,147,483,519 (= Integer.MAX_VALUE - 128) documents. You can monitor shard sizes using the _cat/shards API.
Implementation ideas
Es itself supports the form of "delete by query" to delete the queried data. First of all, we get all index information on the current es service through the "UC at / indexes" portal.
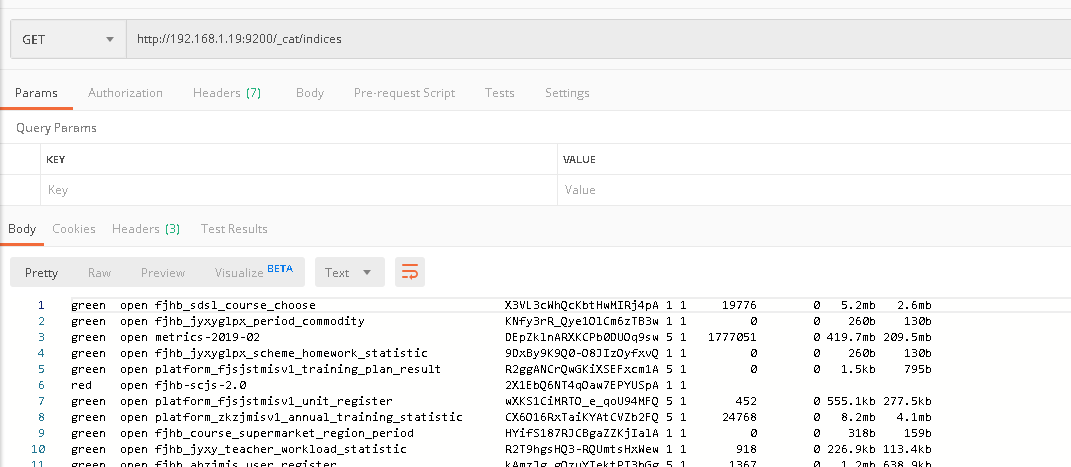
The first column indicates the current health status of the index
The third column indicates the name of the index
The fourth column indicates the storage directory name of the index on the server
The fifth and sixth columns represent the number of copies and partition information of the index
The seventh column represents the number of documents currently indexed
The last two columns represent the storage space of the current index, and the last two columns are equal to the last one multiplied by the number of copies
Secondly, we use curl form to splice the deletion command and send it to es server for execution. The createtime field is the data generation time, in milliseconds
curl -X POST "http://192.168.1.19:9400/fjhb-surveyor-v2/_delete_by_query?pretty" -H 'Content-Type: application/json' -d '
{"query":{ "range": {
"createTime": {
"lt": 1580400000000,
"format": "epoch_millis"
}
}
}}'Concrete realization
#!/usr/bin/python
# -*- coding: UTF-8 -*-
###Import required modules
import requests
import time
import datetime
import os
#Define the function to get ES data dictionary, return the dictionary of index name and storage space occupied by index
def getData(env):
header = {"Content-Type": "application/x-www-form-urlencoded",
"user-agent": "User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"
}
data = {}
with open('result.txt','w+') as f:
req = requests.get(url=env+'/_cat/indices',headers=header).text
f.write(req)
f.seek(0)
for line in f.readlines():
data[line.split()[2]] = line.split()[-1]
return data
#Define unix time conversion function, return in milliseconds, return value is int type
def unixTime(day):
today = datetime.date.today()
target_day = today + datetime.timedelta(day)
unixtime = int(time.mktime(target_day.timetuple())) * 1000
return unixtime
#Define the delete es data function, call the curl command of the system to delete, which requires the parameters of the time range (i.e. the data before how many days) that need to be transferred into the environment and deleted. Due to the large number of indexes, we can only handle indexes that exceed 1G
def delData(env,day):
header = 'Content-Type: application/json'
for key, value in getData(env).items():
if 'gb' in value:
size = float(value.split('gb')[0])
if size > 1:
url = dev + '/' + key + '/_delete_by_query?pretty'
command = ("curl -X POST \"%s\" -H '%s' "
"-d '{\"query\":{ \"range\": {\"createTime\": {\"lt\": %s,\"format\": \"epoch_millis\"}}}}'" % (
url, header, day))
print(command)
os.system(command)
if __name__ == '__main__':
dev = 'http://192.168.1.19:9400'
test1 = 'http://192.168.1.19:9200'
test2 = 'http://192.168.1.19:9600'
day = unixTime(-30)
delData(dev,day)
delData(test1,day)
delData(test2,day)
Result verification
Before deleting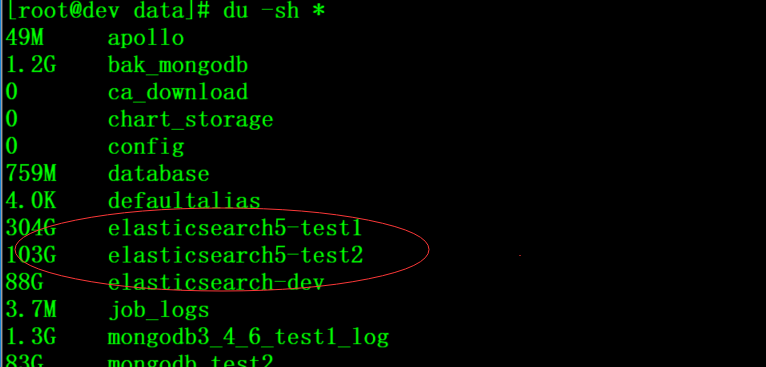
After deletion
Matters needing attention
1. At present, the scripts are scheduled in crontab mode, and run once a day
2. The first deletion takes a long time because of the large amount of data, and the subsequent deletion of one day's data per day has a fair efficiency
3. The script does not consider exceptions such as server error reporting and alarm notification. The actual application scenario needs to be supplemented
4. The script does not consider logging, so the actual application scenario needs to be supplemented