Next, you need to store the stock data in csv format in mysql database:
Here are two methods:
+Using pymysql
+Using sqlalchemy
See mysql installation here: https://blog.csdn.net/tonydz0523/article/details/82501177
Using pymysql
Install pip install pymysql
You also need to use pandas PIP install pandas
First, establish a connection with mysql
import pymysql
# Set the output to dictionary mode and connect to the local user ffzs password to 666
config = dict(host='localhost', user='ffzs', password='666',
cursorclass=pymysql.cursors.DictCursor
)
# Establish connection
conn = pymysql.Connect(**config)
# Auto confirm commit True
conn.autocommit(1)
# Set cursor
cursor = conn.cursor()Use pandas to read the csv file. Those who need data test can go to NetEase Finance and economics for the next one: http://quotes.money.163.com/trade/lsjysj_600508.html#01b07
Let's first look at what the data looks like: 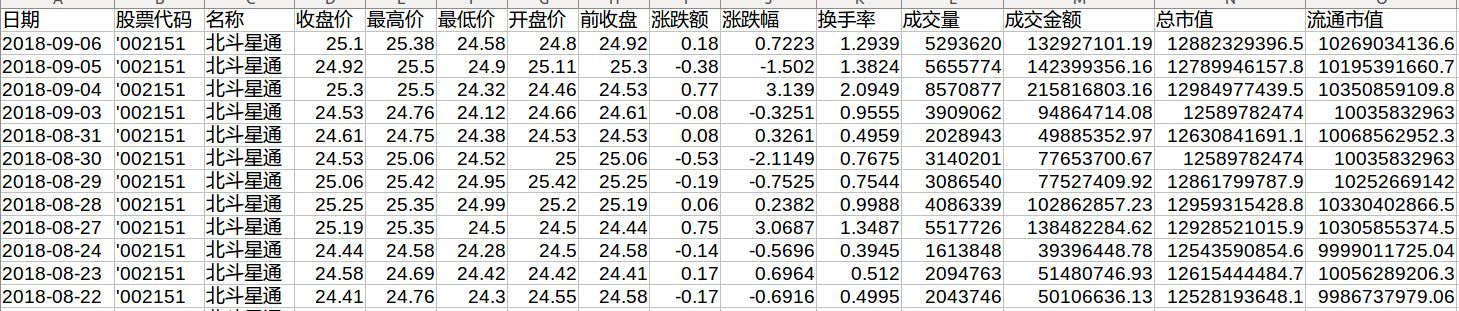
There are a lot of parameters. I only need date, closing price, maximum price, minimum price, opening price and trading volume. I don't need any other data
import pandas as pd
# pandas reads the file. Here, I found a name of the stock file I crawled
# usecols means that I only use these columns. I don't need other columns
# Because csv only stores str, int, and float formats, it can't store date formats, so the reading is to set the date column as the time format
df = pd.read_csv('stock.csv', encoding='gbk', usecols=[0, 3, 4, 5, 6, 11], parse_dates=['date'] )df.head() results are as follows:
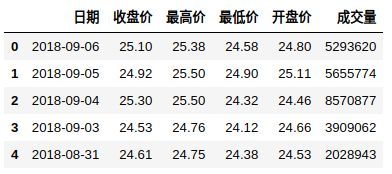
Format conversion: when creating a table, you need to set the column type. Write a function here to convert the pandas type to sql type:
# Set the type of table according to the automatic recognition type of Panda
def make_table_sql(df):
columns = df.columns.tolist()
types = df.ftypes
# Add id brake incremental primary key mode
make_table = []
for item in columns:
if 'int' in types[item]:
char = item + ' INT'
elif 'float' in types[item]:
char = item + ' FLOAT'
elif 'object' in types[item]:
char = item + ' VARCHAR(255)'
elif 'datetime' in types[item]:
char = item + ' DATETIME'
make_table.append(char)
return ','.join(make_table)Create a table and batch write it to mysql:
# Input csv format into mysql
def csv2mysql(db_name, table_name, df):
# Create database
cursor.execute('CREATE DATABASE IF NOT EXISTS {}'.format(db_name))
# Choose to connect to database
conn.select_db(db_name)
# Create table
cursor.execute('DROP TABLE IF EXISTS {}'.format(table_name))
cursor.execute('CREATE TABLE {}({})'.format(table_name,make_table_sql(df)))
# The extracted data is transferred to the list, and the time mode of pandas cannot be written. Therefore, the format of mysql has been set by changing to str
df['date'] = df['date'].astype('str')
values = df.values.tolist()
# According to the number of columns
s = ','.join(['%s' for _ in range(len(df.columns))])
# executemany batch operation insert data batch operation is much faster than one by one operation
cursor.executemany('INSERT INTO {} VALUES ({})'.format(table_name,s), values)Then run function:
csv2mysql(db_name=stock, table_name=test1 , df)Test whether the following is written successfully:
cursor.execute('SELECT * FROM test1 LIMIT 5')
# scroll(self, value, mode='relative') Move pointer to a row; If mode='relative',Move from the current line value strip,If mode='absolute',Move from the first row of the result set value strip.
cursor.scroll(4)
cursor.fetchall()The results are as follows:

Log in to the database to view
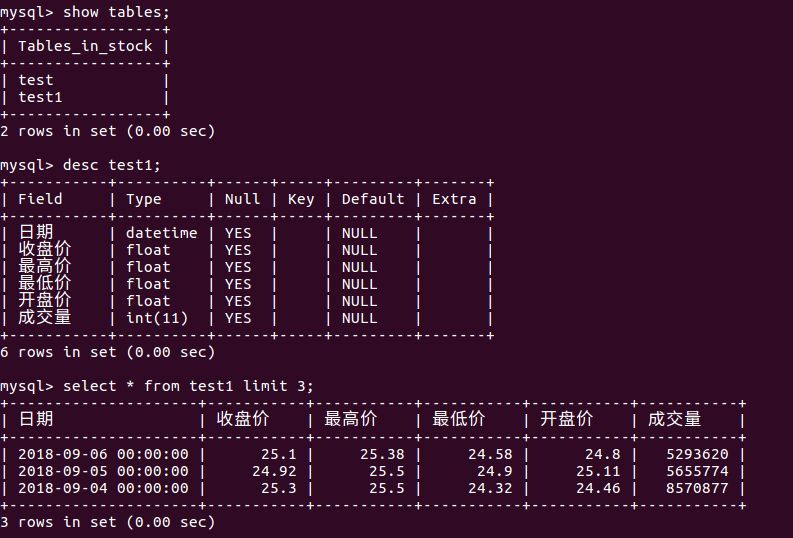
Close cursor and connection after use:
# Cursor closing
cursor.close()
# Connection closure
conn.close()Using sqlalchemy
Using sqlalchemy is simpler than pymysql
Install pip install sqlalchemy
Also, establish a connection with mysql first:
import pandas as pd
from sqlalchemy import create_engine
from datetime import datetime
from sqlalchemy.types import NVARCHAR, Float, Integer
# Connection settings connection mysql user name ffzs password 666 address localhost: 3306 database: stock
engine = create_engine('mysql+pymysql://ffzs:666@localhost:3306/stock')
# Establish connection
con = engine.connect()pandas reads the csv file:
df = pd.read_csv('stock.csv', encoding='gbk',usecols=[0, 3, 4, 5, 6, 11], parse_dates=['date'])Type conversion function
# pandas type and sql type conversion
def map_types(df):
dtypedict = {}
for i, j in zip(df.columns, df.dtypes):
if "object" in str(j):
dtypedict.update({i: NVARCHAR(length=255)})
if "float" in str(j):
dtypedict.update({i: Float(precision=2, asdecimal=True)})
if "int" in str(j):
dtypedict.update({i: Integer()})
return dtypedictSave to mysql:
dtypedict = map_types(df)
# Set the type to dict format {"col" name ": type} through dtype
df.to_sql(name='test2', con=con, if_exists='replace', index=False, dtype=dtypedict)Look at the results:
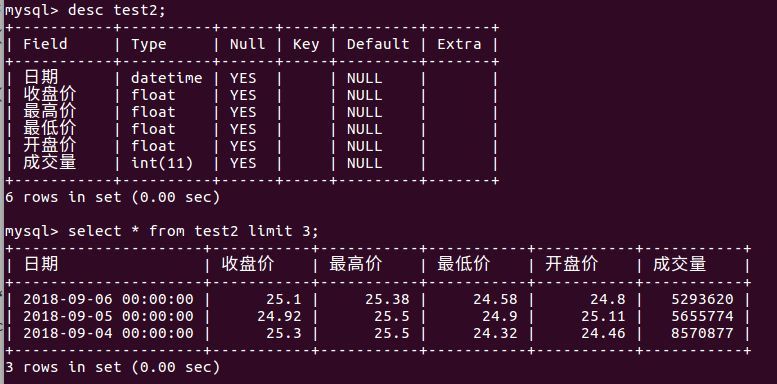
Next, we will analyze the stock data..