Flume's main function is to read the data from the server's local disk in real time and write the data to HDFS.
The Flume architecture is as follows:

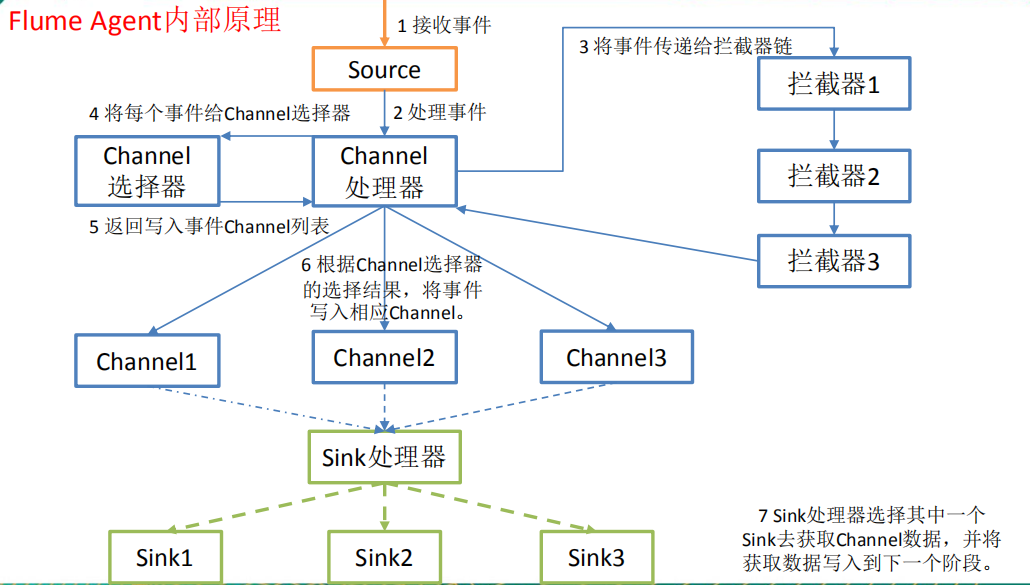
The internal principle of Flume Agent is shown in the figure.
1. Configure hive log file storage location:

2. Modify configuration items:

Create the logs folder under the root directory of his
3. Create configuration files for flume
Create a job folder under the root directory of flume to store the configuration files for flume:

Create file-flume-hdfs.conf configuration file:

The file-flume-hdfs.conf configuration file is as follows:
# Name the components on this agent a2.sources = r2 #Define source a2.sinks = k2 #Define sink a2.channels = c2 #Define channel # Describe/configure the source a2.sources.r2.type = exec #Defining source type as exec executable command a2.sources.r2.command = tail -F /usr/local/hive/logs/hive.log #hive log information store information a2.sources.r2.shell = /bin/bash -c #Absolute path to execute shell script # Describe the sink a2.sinks.k2.type = hdfs a2.sinks.k2.hdfs.path = hdfs://master:9000/flume/%Y%m%d/%H a2.sinks.k2.hdfs.filePrefix = logs- #Prefix for uploading files a2.sinks.k2.hdfs.round = true #Whether to scroll folders according to time a2.sinks.k2.hdfs.roundValue = 1 #How much time to create a new folder a2.sinks.k2.hdfs.roundUnit = hour #Redefining unit of time a2.sinks.k2.hdfs.useLocalTimeStamp = true #Whether to use local timestamp a2.sinks.k2.hdfs.batchSize = 1000 #How many Event s are saved to flush to HDFS once a2.sinks.k2.hdfs.fileType = DataStream #Set file type to support compression a2.sinks.k2.hdfs.rollInterval = 600 #How often to generate a new file a2.sinks.k2.hdfs.rollSize = 134217700 #Set the scroll size for each file a2.sinks.k2.hdfs.rollCount = 0 #File scrolling is independent of the number of Event s a2.sinks.k2.hdfs.minBlockReplicas = 1 #Minimum Redundancy Number # Use a channel which buffers events in memory a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2
4. Upload the jar package to the lib folder of flume:

5. Start flume

6. Open HDFS to view files:
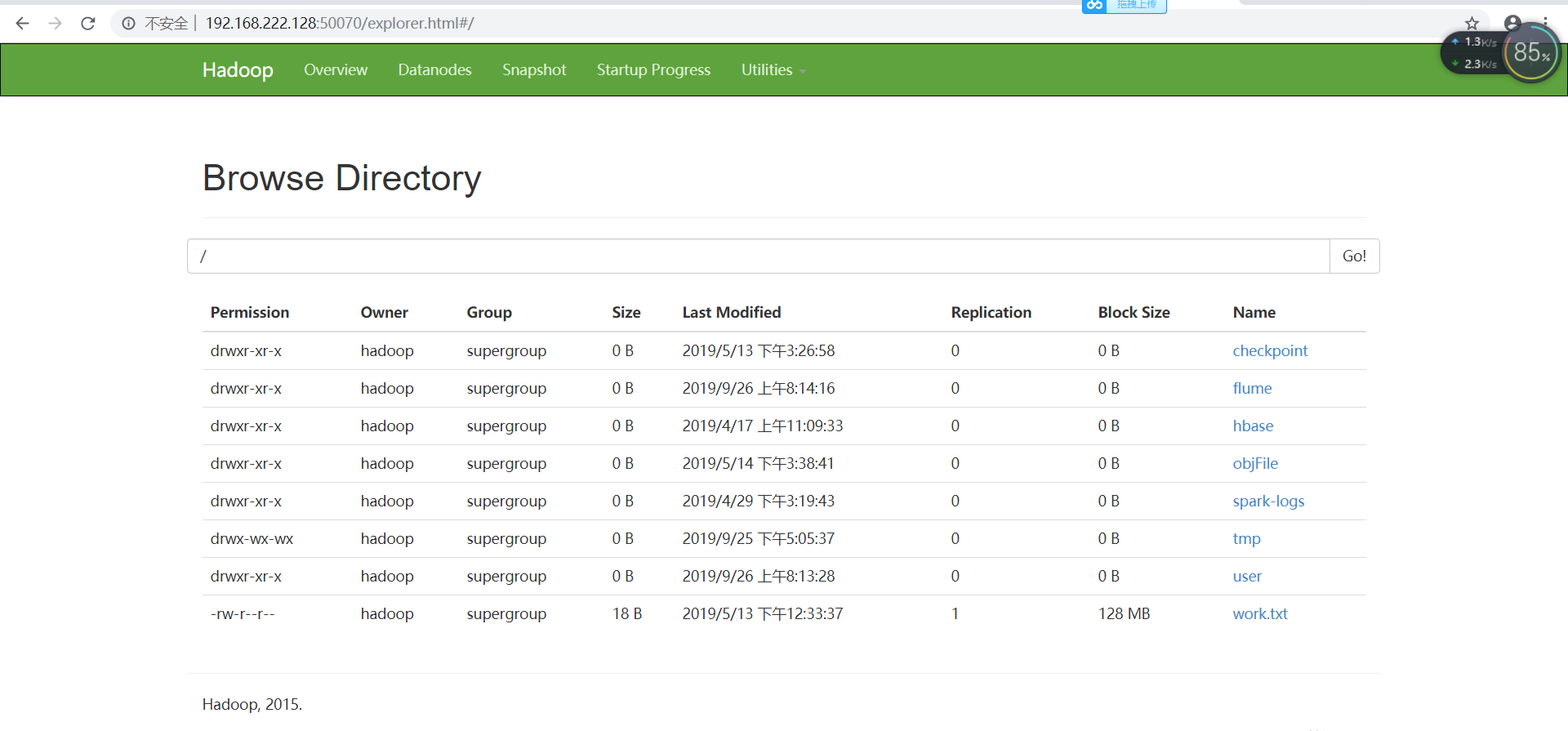

In this way, hive's log files are sent to HDFS in real time.