Take a simple example to see how LSTM does classification in tensorflow.
This is a particularly simple example of how LSTM works by counting 1 of a 20-length binary string to something you can do with a for.
You can stop here and see what you think.
import numpy as np
from random import shuffleinput has a total of 2^20 combinations, so much data is generated
train_input = ['{0:020b}'.format(i) for i in range(2**20)]
shuffle(train_input)
train_input = [map(int,i) for i in train_input]train_input:
[1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0]
[0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1]
[0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1]
Convert each input into tensor form
In dimensions =[batch_size, sequence_length, input_dimension],
sequence_length = 20 and input_dimension = 1,
Each input becomes A list of 20 lists
ti = []
for i in train_input:
temp_list = []
for j in i:
temp_list.append([j])
ti.append( np.array(temp_list) )
train_input = titrain_input :
[[1][0][0][0][1][1][1][0][1][0][0][0][0][1][0][0][0][1][0][0]]
Generate actual output data
train_output = []
for i in train_input:
count = 0
for j in i:
if j[0] == 1:
count+=1
temp_list = ([0]*21)
temp_list[count]=1
train_output.append(temp_list)train_output: There is a 1 in the last position, indicating that there are several 1 in the input, and the length is 21
[0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Take 0.9% as training data and the other as test data
NUM_EXAMPLES = 10000
test_input = train_input[NUM_EXAMPLES:]
test_output = train_output[NUM_EXAMPLES:] #everything beyond 10,000
train_input = train_input[:NUM_EXAMPLES]
train_output = train_output[:NUM_EXAMPLES] #till 10,000Define two variables
Where the dimension of data = [Batch Size, Sequence Length, Input Dimension]
data = tf.placeholder(tf.float32, [None, 20,1])
target = tf.placeholder(tf.float32, [None, 21])Define hidden dimension=24
Too much overfitting, too little is not good, you can adjust to see the change.
Model uses LSTM, version of tf 1.0.0 used here
num_hidden = 24
# cell = tf.nn.rnn_cell.LSTMCell(num_hidden,state_is_tuple=True)
cell = tf.contrib.rnn.LSTMCell(num_hidden,state_is_tuple=True)Save this output with val ue
val, _ = tf.nn.dynamic_rnn(cell, data, dtype=tf.float32)
Change the dimension once and take the last of Vals as last
val = tf.transpose(val, [1, 0, 2])
last = tf.gather(val, int(val.get_shape()[0]) - 1)
Define weight and bias
weight = tf.Variable(tf.truncated_normal( [num_hidden, int(target.get_shape()[1])] ))
bias = tf.Variable(tf.constant(0.1, shape=[target.get_shape()[1]]))softmax gets prediction on reactivation
prediction = tf.nn.softmax(tf.matmul(last, weight) + bias)
Use cross_entropy for cost function, the goal is to minimize it, use AdamOptimizer
cross_entropy = -tf.reduce_sum(target * tf.log(tf.clip_by_value(prediction,1e-10,1.0)))
optimizer = tf.train.AdamOptimizer()
minimize = optimizer.minimize(cross_entropy)Define the form of an error, which is how many locations are different between predictions and reality
mistakes = tf.not_equal(tf.argmax(target, 1), tf.argmax(prediction, 1))
error = tf.reduce_mean(tf.cast(mistakes, tf.float32))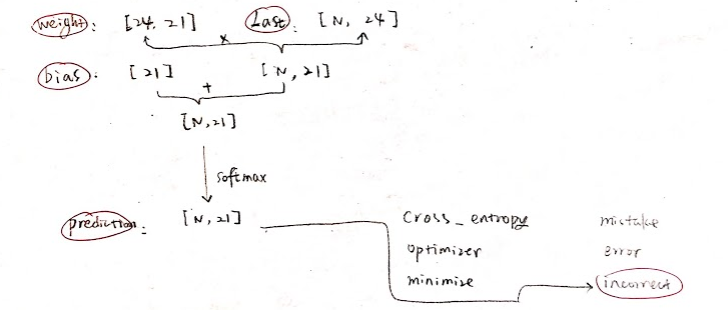
Once you've defined the model and variables, start session here
init_op = tf.initialize_all_variables() sess = tf.Session() sess.run(init_op)
60 iterations to reach 0.3% error
batch_size = 1000
no_of_batches = int(len(train_input)) / batch_size
epoch = 600for i in range(epoch):
ptr = 0
for j in range(no_of_batches):
inp, out = train_input[ptr:ptr+batch_size], train_output[ptr:ptr+batch_size]
ptr += batch_size
sess.run(minimize,{data: inp, target: out})
print "Epoch ",str(i)
incorrect = sess.run(error,{data: test_input, target: test_output})
print sess.run(prediction, {data: [[[1],[0],[0],[1],[1],[0],[1],[1],[1],[0],[1],[0],[0],[1],[1],[0],[1],[1],[1],[0]]]})
print('Epoch {:2d} error {:3.1f}%'.format(i + 1, 100 * incorrect))
sess.close()The final result:
[[ 2.80220238e-08 3.24575727e-10 5.68697936e-11 3.57573054e-10
9.62089857e-08 1.30921896e-08 2.14473985e-08 5.21751364e-10
2.29034747e-08 8.47907577e-10 3.60394756e-06 2.30961153e-03
9.82593179e-01 1.50928665e-02 4.23395448e-07 1.06428047e-07
6.70640388e-09 1.78888765e-10 3.22445395e-08 3.09186134e-08
3.70296416e-09]]
Epoch 600 error 0.3%Learning materials:
http://monik.in/a-noobs-guide-to-implementing-rnn-lstm-using-tensorflow/
Recommended reading
Summary of historical technology blog links
Maybe you can find what you want