Stream is simply an abstract interface, which is implemented by many objects in Node. For example, the request object that initiates a request to an http server is a Stream and stdout (standard output). There are four flow types in Node:
-
Readable - Readable operation.
-
Writable - Writable operation.
-
Duplex - Readable and Writable Operation.
-
Transform - The operation is written to the data and the result is read out.
Basically all Stream objects are instances of EventEmitter, and the common events are as follows:
-
Data - Triggered when data is readable.
-
end - Triggered when no more data is readable.
-
Error - Triggered when an error occurs in the process of receiving and writing.
-
finish - Triggered when all data has been written to the underlying system.
Let's first create the input.txt file for testing, as follows:
luyaran is my lover
Create the main.js file, code as follows:
var fs = require("fs");
var data = '';
// Creating Readable Stream
var readerStream = fs.createReadStream('input.txt');
// Set the code to utf8.
readerStream.setEncoding('UTF8');
// Processing stream events - > data, end, and error
readerStream.on('data', function(chunk) {
data += chunk;
});
readerStream.on('end',function(){
console.log(data);
});
readerStream.on('error', function(err){
console.log(err.stack);
});
console.log("Completion of program execution");Let's see how to write:
var fs = require("fs");
var data = 'luyaran';
// Create a stream that can be written to the file output.txt
var writerStream = fs.createWriteStream('output.txt');
// Write data using utf8 encoding
writerStream.write(data,'UTF8');
// Mark the end of the file
writerStream.end();
// Processing stream events - > data, end, and error
writerStream.on('finish', function() {
console.log("Write completed.");
});
writerStream.on('error', function(err){
console.log(err.stack);
});
console.log("Completion of program execution");Pipelines provide a mechanism for transferring data from one stream to another. Let's look at the flow chart below.
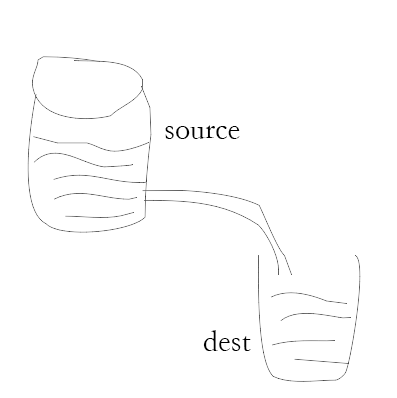
As shown in the picture above, we compare the document to a bucket of water, and water is the content of the document. We use a pipe to connect two buckets so that water flows from one bucket to another. This slowly realizes the process of copying large files.
Let's look at an example:
var fs = require("fs");
// Create a readable stream
var readerStream = fs.createReadStream('input.txt');
// Create a writable stream
var writerStream = fs.createWriteStream('output.txt');
// Pipeline Read-Write Operation
// Read the input.txt file content and write it to the output.txt file
readerStream.pipe(writerStream);
console.log("Completion of program execution");Chain is a mechanism that connects the output stream to another stream and creates multiple flow operation chains. It is generally used for pipeline operation.
Next, we use pipelines and chains to compress and decompress files. The code is as follows:
var fs = require("fs");
var zlib = require('zlib');
// Compressed input.txt file is input.txt.gz
fs.createReadStream('input.txt')
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream('input.txt.gz'));
console.log("File compression is completed.");After doing the above, we can see that the input.txt compressed file input.txt.gz is generated in the current directory. Next, let's unzip the file and create the decompress.js file, which is coded as follows:
var fs = require("fs");
var zlib = require('zlib');
// Unzip the input.txt.gz file as input.txt
fs.createReadStream('input.txt.gz')
.pipe(zlib.createGunzip())
.pipe(fs.createWriteStream('input.txt'));
console.log("The file is decompressed.");Now, there is a need to write the contents of the input into the outInput, but the above method is to reset the contents of the document, the requirements only want to add, and retain the original content. We can operate in the callback function created by the readable stream, as follows:
let fs = require('fs');
let data = '';
let data2 = 'Your little frog is really cute.';
//1. read stream
//Creating Readable Stream
let readStream = fs.createReadStream("input.txt");
//Setting utf-8 encoding
readStream.setEncoding('UTF8');
//Processing Stream Events
readStream.on('data', chunk => data += chunk);
readStream.on('end', () => writeS(data));
readStream.on("error", err => console.log(err.strck));
console.log("Program 1 has been executed");
//2. write stream
//Creating Writable Stream
let writeS = dataS =>{
let writeStream = fs.createWriteStream("outInput.txt");
//Write streams using utf-8
writeStream.write(data2+dataS, "UTF8");
//Mark the end of the file
writeStream.end();
//Handling event flow
writeStream.on("finish", () => console.log("Write completion"));
writeStream.on("error", err => console.log(err.stack));
console.log("Program 2 has been executed");
}We can also set additional parameters for the write stream to solve the problem:
var fs = require('fs');
var read = fs.createReadStream('../data/input.txt');
//Set the second parameter append
var write = fs.createWriteStream('../data/out.txt', { 'flags': 'a' });
//Read-write operation of pipeline flow
read.pipe(write);
console.log('completion of enforcement');Then there is the problem of Chinese scrambling. We can install iconv-lite as a whole.
npm install -g iconv-lite
The code style is as follows:
var iconv = require('iconv-lite');
var fs = require('fs');
var fileStr = fs.readFileSync('D:\\test.csv', {encoding:'binary'});
var buf = new Buffer(fileStr, 'binary');
var str = iconv.decode(buf, 'GBK');
console.log(str);The principle is very simple, that is, first read by binary coding, and then decode by GBK.
Well, that's all for this record.
If you feel good, please give more praise and support.