1. Background introduction:
With the upgrade of MaxCompute version 2.0, the data types supported by Java UDF have expanded from BIGINT, STRING, DOUBLE, BOOLEAN to more basic data types, as well as complex types such as ARRAY, MAP, STRUCT, and Writable parameters.Java UDF uses a method of complex data types, STRUCT corresponds to com.aliyun.odps.data.Struct.Field Name and Field Type cannot be seen from reflection by com.aliyun.odps.data.Struct, so the @Resolve annotation is needed to assist.That is, if STRUCT is required in UDF, the @Resolve annotation is also required on the UDF Class.But when we have many fields in the field of the Struct type, it's not so friendly to need us to manually add the @Resolve annotation at this time.To solve this problem, we can use GenericUDF in Hive.MaxCompute 2.0 supports Hive-style UDFs, some of which can be used directly on MaxCompute.
2. UDF examples of complex data types
The example defines a UDF with three complex data types, the first with ARRAY as the parameter, the second with MAP as the parameter, and the third with STRUCT as the parameter.Since the third Overloads uses STRUCT as a parameter or return value, you must add the @Resolve annotation to the UDF Class to specify the specific type of STRUCT.
1. Coding
@Resolve("struct<a:bigint>,string->string") public class UdfArray extends UDF { public String evaluate(List<String> vals, Long len) { return vals.get(len.intValue()); } public String evaluate(Map<String,String> map, String key) { return map.get(key); } public String evaluate(Struct struct, String key) { return struct.getFieldValue("a") + key; } }
2. Play jar packages to add resources
add jar UdfArray.jar
3. Create Functions
create function my_index as 'UdfArray' using 'UdfArray.jar';
4. Use UDF functions
select id, my_index(array('red', 'yellow', 'green'), colorOrdinal) as color_name from colors;
3. GenericUDF using Hive
Here we use the Struct complex data type as an example. The main logic is to not return when there is no difference between the two fields in our structure. If there is a difference between the two fields, the new fields and their values will be returned as a new structure.Struct has three Field s in the example.The GenericUDF approach solves the need to manually add the @Resolve annotation.
1. Create a MaxCompute table
CREATE TABLE IF NOT EXISTS `tmp_ab_struct_type_1` ( `a1` struct<a:STRING,b:STRING,c:string>, `b1` struct<a:STRING,b:STRING,c:string> );
2. The data structure in the table is as follows
insert into table tmp_ab_struct_type_1 SELECT named_struct('a',1,'b',3,'c','2019-12-17 16:27:00'), named_struct('a',5,'b',6,'c','2019-12-18 16:30:00');
The query data is as follows:

3. Write GenericUDF processing logic
(1) QSC_DEMOO class
package com.aliyun.udf.struct; import org.apache.hadoop.hive.ql.exec.UDFArgumentException; import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException; import org.apache.hadoop.hive.ql.metadata.HiveException; import org.apache.hadoop.hive.ql.udf.generic.GenericUDF; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory; import org.apache.hadoop.hive.serde2.objectinspector.StructField; import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector; import java.util.ArrayList; import java.util.List; /** * Created by ljw on 2019-12-17 * Description: */ @SuppressWarnings("Duplicates") public class QSC_DEMOO extends GenericUDF { StructObjectInspector soi1; StructObjectInspector soi2; /** * Avoid frequent Struct objects */ private PubSimpleStruct resultStruct = new PubSimpleStruct(); private List<? extends StructField> allStructFieldRefs; //1. This method is called only once and before the evaluate() method.The parameter accepted by this method is an arguments array.This method checks to accept the correct parameter type and number. //2. Definition of output type @Override public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException { String error = ""; //Verify that the number of parameters is correct if (arguments.length != 2) { throw new UDFArgumentException("Two parameters are required"); } //Determine whether the parameter type is correct - struct ObjectInspector.Category arg1 = arguments[0].getCategory(); ObjectInspector.Category arg2 = arguments[1].getCategory(); if (!(arg1.equals(ObjectInspector.Category.STRUCT))) { error += arguments[0].getClass().getSimpleName(); throw new UDFArgumentTypeException(0, "\"array\" expected at function STRUCT_CONTAINS, but \"" + arg1.name() + "\" " + "is found" + "\n" + error); } if (!(arg2.equals(ObjectInspector.Category.STRUCT))) { error += arguments[1].getClass().getSimpleName(); throw new UDFArgumentTypeException(0, "\"array\" expected at function STRUCT_CONTAINS, but \"" + arg2.name() + "\" " + "is found" + "\n" + error); } //Output structure definition ArrayList<String> structFieldNames = new ArrayList(); ArrayList<ObjectInspector> structFieldObjectInspectors = new ArrayList(); soi1 = (StructObjectInspector) arguments[0]; soi2 = (StructObjectInspector) arguments[1]; StructObjectInspector toValid = null; if (soi1 == null) toValid = soi2; else toValid = soi1; //Setting the return type allStructFieldRefs = toValid.getAllStructFieldRefs(); for (StructField structField : allStructFieldRefs) { structFieldNames.add(structField.getFieldName()); structFieldObjectInspectors.add(structField.getFieldObjectInspector()); } return ObjectInspectorFactory.getStandardStructObjectInspector(structFieldNames, structFieldObjectInspectors); } //This method is similar to the evaluate() method of UDF.It handles the real parameters and returns the final result. @Override public Object evaluate(DeferredObject[] deferredObjects) throws HiveException { //Convert the struct type from hive to com.aliyun.odps.data.Struct. If there are errors, debug to see what the data from deferredObjects looks like //Then re-encapsulate it yourself!!! ArrayList list1 = (ArrayList) deferredObjects[0].get(); ArrayList list2 = (ArrayList) deferredObjects[1].get(); int len = list1.size(); ArrayList fieldNames = new ArrayList<>(); ArrayList fieldValues = new ArrayList<>(); for (int i = 0; i < len ; i++) { if (!list1.get(i).equals(list2.get(i))) { fieldNames.add(allStructFieldRefs.get(i).getFieldName()); fieldValues.add(list2.get(i)); } } if (fieldValues.size() == 0) return null; return fieldValues; } //This method is used to print out prompts when an implementation of GenericUDF fails.The hint is the string you returned at the end of the implementation. @Override public String getDisplayString(String[] strings) { return "Usage:" + this.getClass().getName() + "(" + strings[0] + ")"; } }
(2) PubSimpleStruct class
package com.aliyun.udf.struct; import com.aliyun.odps.data.Struct; import com.aliyun.odps.type.StructTypeInfo; import com.aliyun.odps.type.TypeInfo; import java.util.List; public class PubSimpleStruct implements Struct { private StructTypeInfo typeInfo; private List<Object> fieldValues; public StructTypeInfo getTypeInfo() { return typeInfo; } public void setTypeInfo(StructTypeInfo typeInfo) { this.typeInfo = typeInfo; } public void setFieldValues(List<Object> fieldValues) { this.fieldValues = fieldValues; } public int getFieldCount() { return fieldValues.size(); } public String getFieldName(int index) { return typeInfo.getFieldNames().get(index); } public TypeInfo getFieldTypeInfo(int index) { return typeInfo.getFieldTypeInfos().get(index); } public Object getFieldValue(int index) { return fieldValues.get(index); } public TypeInfo getFieldTypeInfo(String fieldName) { for (int i = 0; i < typeInfo.getFieldCount(); ++i) { if (typeInfo.getFieldNames().get(i).equalsIgnoreCase(fieldName)) { return typeInfo.getFieldTypeInfos().get(i); } } return null; } public Object getFieldValue(String fieldName) { for (int i = 0; i < typeInfo.getFieldCount(); ++i) { if (typeInfo.getFieldNames().get(i).equalsIgnoreCase(fieldName)) { return fieldValues.get(i); } } return null; } public List<Object> getFieldValues() { return fieldValues; } @Override public String toString() { return "PubSimpleStruct{" + "typeInfo=" + typeInfo + ", fieldValues=" + fieldValues + '}'; } }
3. Play jar packages to add resources
add jar test.jar;
4. Create Functions
CREATE FUNCTION UDF_DEMO as 'com.aliyun.udf.test.UDF_DEMOO' using 'test.jar';
5. Testing using UDF functions
set odps.sql.hive.compatible=true; select UDF_DEMO(a1,b1) from tmp_ab_struct_type_1;
The results of the query are as follows:
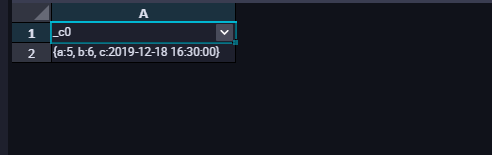
Be careful:
(1) When using compatible Hive UDF, you need to add set odps.sql.hive.compatible=true before SQL; statement, set statement, and SQL statement are submitted for execution together.
(2) Compatible version of HIV is currently supported at 2.1.0, corresponding to Hadoop version 2.7.2.If UDF was developed in another version of Hive/Hadoop, you may need to recompile it with this version of Hive/Hadoop.
In doubt, you can consult Aliyun MaxCompute technical support: Liu Jianwei
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>2.1.0</version> </dependency>
This article is the content of Aliyun and cannot be reproduced without permission.