New table "apache_log" in hive
CREATE TABLE apachelog (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (-|\\[[^\\]*\\]]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*) (?: ([^ \"]*|\".*\") ([^ \"]*|\".*\"))?"
)
STORED AS TEXTFILE;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
This is an official example, but it is wrong. 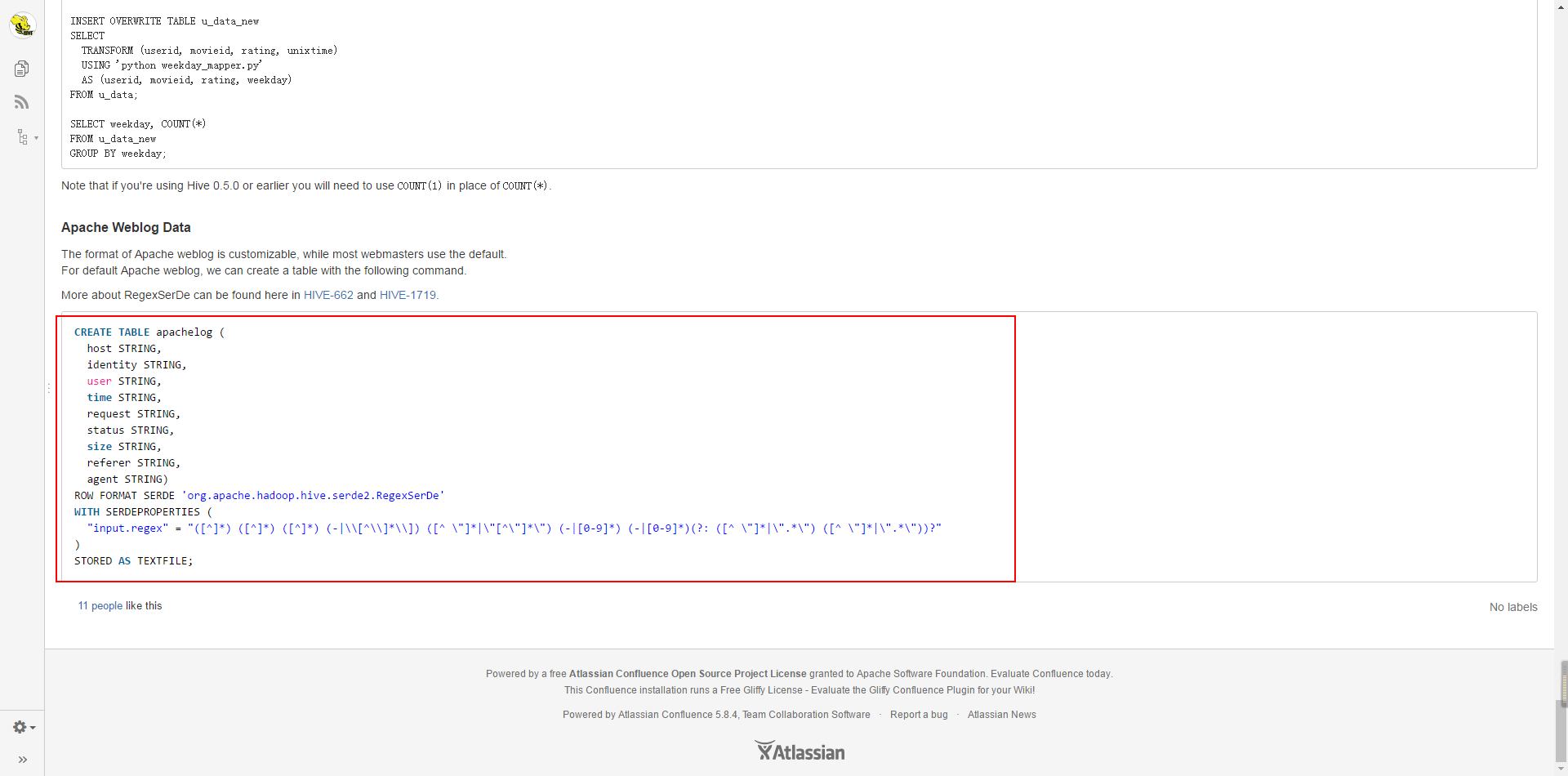
However, changes have been made. 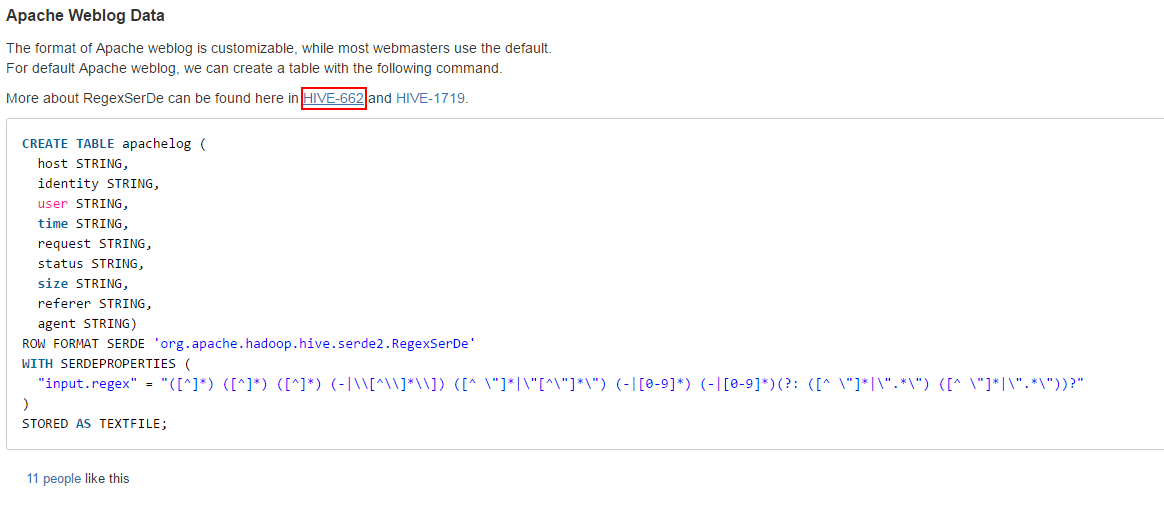
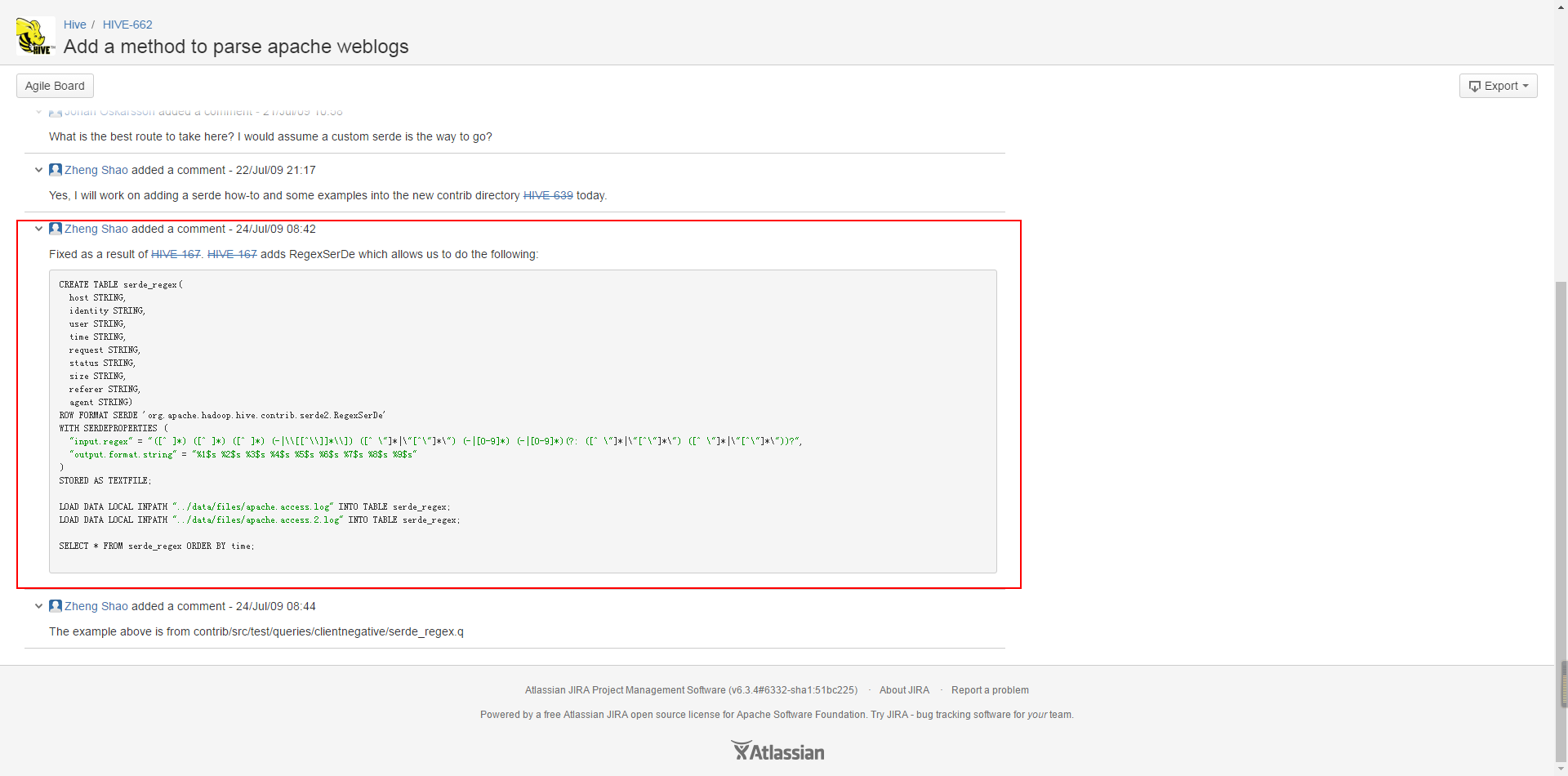
Next, it combines some sample data (the sample data will give download connections in the comments):
27.19.74.143 - - [29/April/2016:17:38:20 +0800] "GET /static/image/common/faq.gif HTTP/1.1" 200 1127
110.52.250.126 - - [29/April/2016:17:38:20 +0800] "GET /data/cache/style_1_widthauto.css?y7a HTTP/1.1" 200 1292
27.19.74.143 - - [29/April/2016:17:38:20 +0800] "GET /static/image/common/hot_1.gif HTTP/1.1" 200 680
27.19.74.143 - - [29/April/2016:17:38:20 +0800] "GET /static/image/common/hot_2.gif HTTP/1.1" 200 682
27.19.74.143 - - [29/April/2016:17:38:20 +0800] "GET /static/image/filetype/common.gif HTTP/1.1" 200 90
110.52.250.126 - - [29/April/2016:17:38:20 +0800] "GET /source/plugin/wsh_wx/img/wsh_zk.css HTTP/1.1" 200 1482
110.52.250.126 - - [29/April/2016:17:38:20 +0800] "GET /data/cache/style_1_forum_index.css?y7a HTTP/1.1" 200 2331
110.52.250.126 - - [29/April/2016:17:38:20 +0800] "GET /source/plugin/wsh_wx/img/wx_jqr.gif HTTP/1.1" 200 1770
27.19.74.143 - - [29/April/2016:17:38:20 +0800] "GET /static/image/common/recommend_1.gif HTTP/1.1" 200 1028
110.52.250.126 - - [29/April/2016:17:38:20 +0800] "GET /static/image/common/logo.png HTTP/1.1" 200 4542
......- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
This is apache server log information, a total of seven fields, respectively: "host", "identity", "user", "time", "request", "status", "size", in the official website of the hive has nine fields, the remaining two are "referer", "agent".
Based on these data, we can experience these three functions from some small requirements.
UDF(user-defined functions)
Small demand:
Extract "time" and convert it into "yyyy-MM-dd HH:mm:ss" format.
Main points:
1. Inheritance from "org.apache.hadoop.hive.ql.exec.UDF";
2. Implement the "evaluate()" method.
*JAVA Code*
package com.hadoop.hivetest.udf;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import org.apache.hadoop.hive.ql.exec.UDF;
public class MyDateParser extends UDF{
public String evaluate(String s){
SimpleDateFormat formator = new SimpleDateFormat("dd/MMMMM/yyyy:HH:mm:ss Z",Locale.ENGLISH);
if(s.indexOf("[")>-1){
s = s.replace("[", "");
}
if(s.indexOf("]")>-1){
s = s.replace("]", "");
}
try {
//Converting input string s to date data types
Date date = formator.parse(s);
SimpleDateFormat rformator = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
return rformator.format(date);
} catch (ParseException e) {
e.printStackTrace();
return "";
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
Episode
Export as a jar package and send it to Linux. This time we can use the editplus editor to upload:
Open editplus and select File-FTP-FTP Setting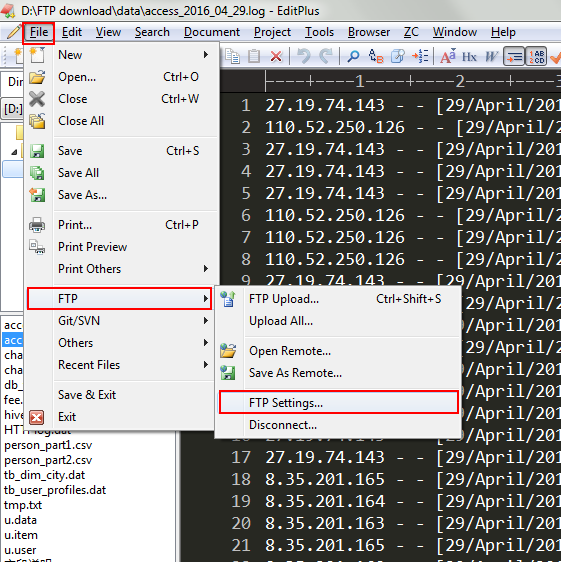
Select Add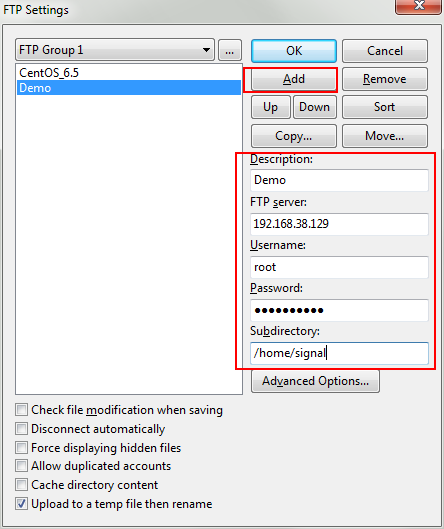
And fill in the values on the corresponding fields. For Subdirectory, fill in which directory you want to upload to Linux.
Click on Advanced Options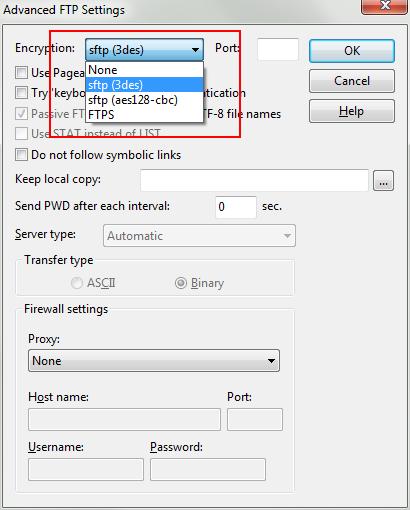
Then you can go all the way back to OK.
- Select FTP Upload _____________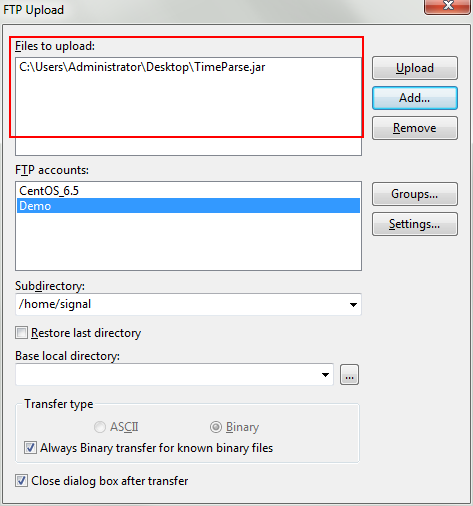
Find the file to upload here, choose which account to upload to, and choose "Upload".
Then we can look for our files in the directory we wrote in Subdirectory. 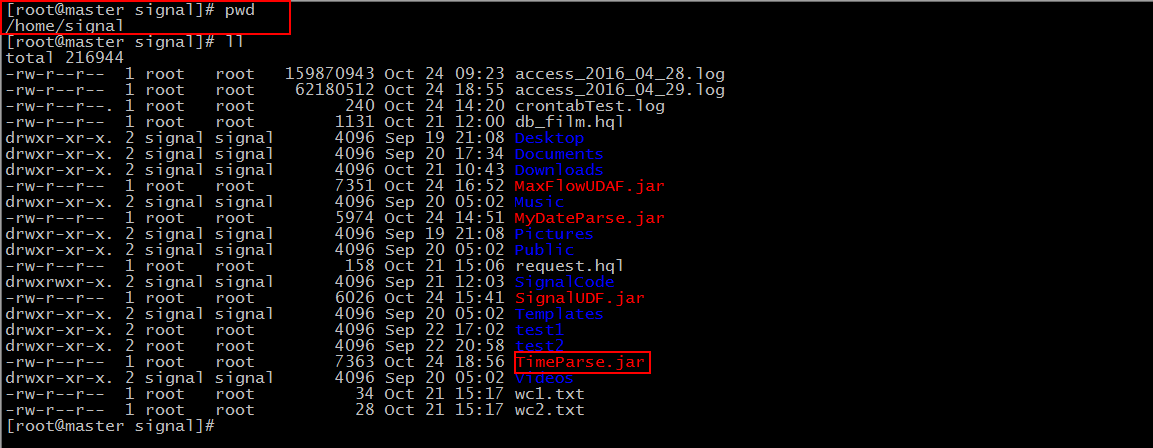
End of the episode
Then we use the beeline client to connect to hive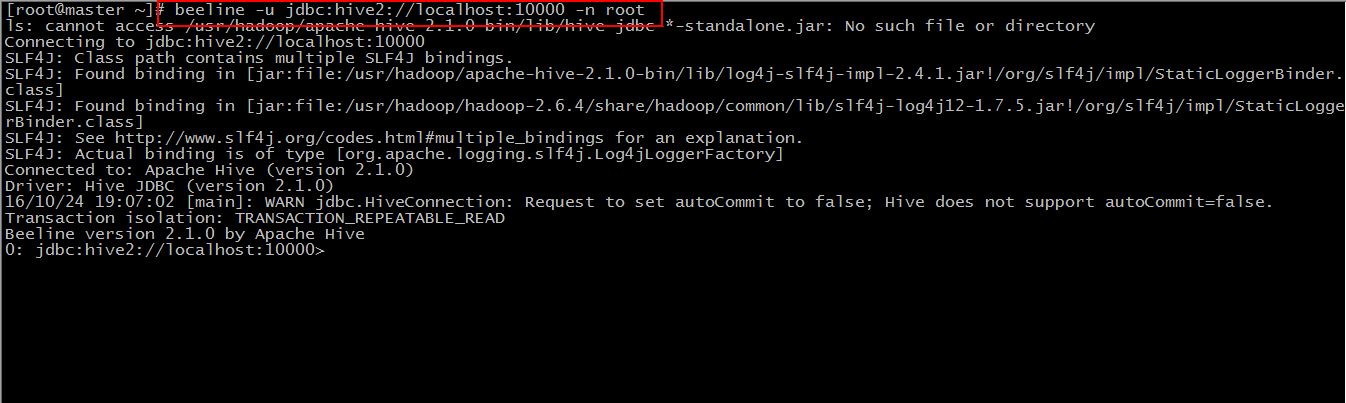
Then we can create a new database and use the previous table statement to create "apache_log" and import the data (by default everyone will ^. ^). 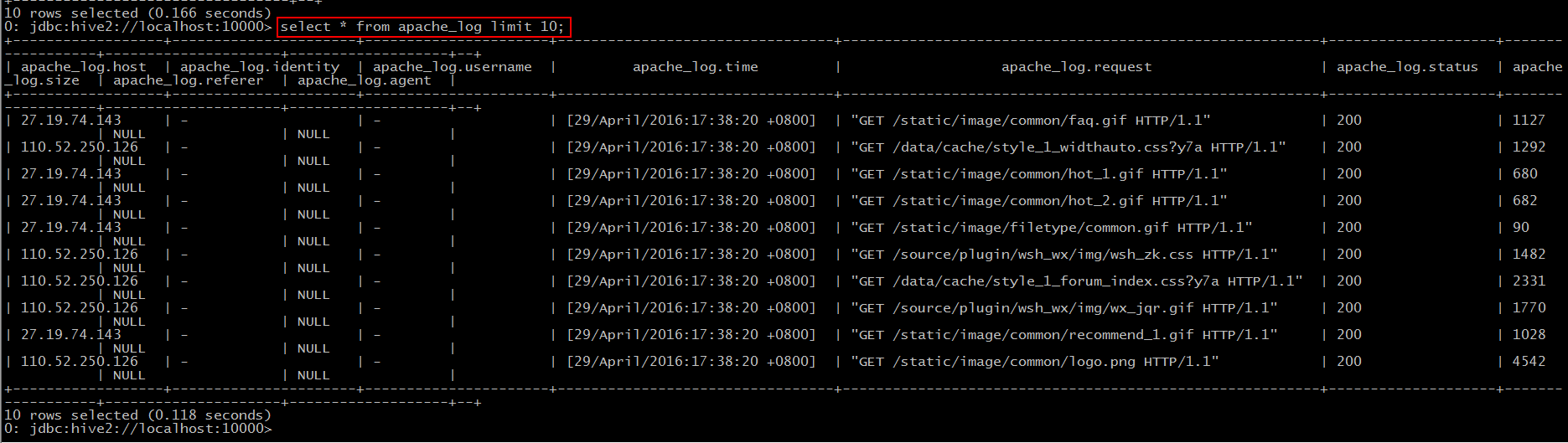
Step 1: add jar "jar-path" 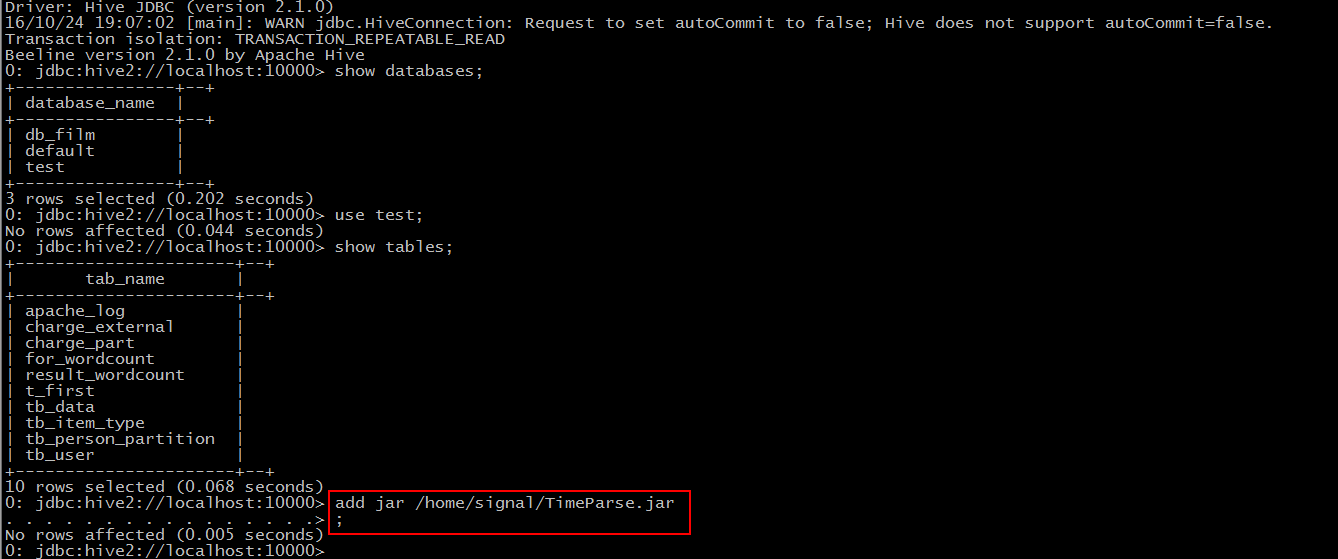
Step 2: create function timeparse as `package name + class name'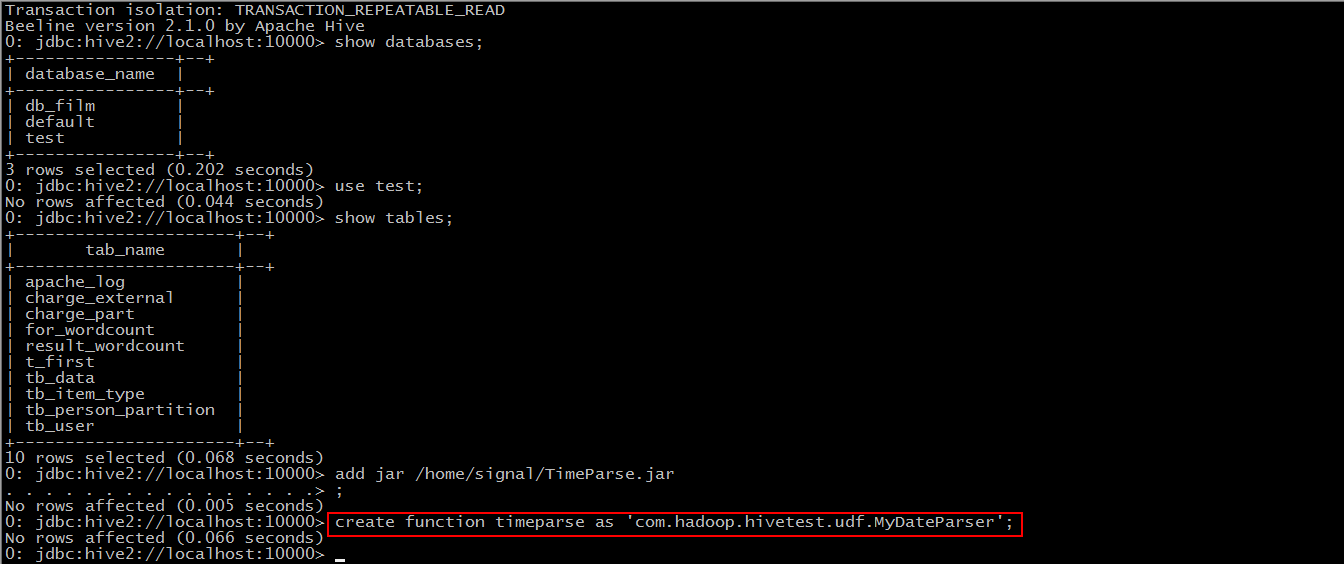
Step 3: Use this function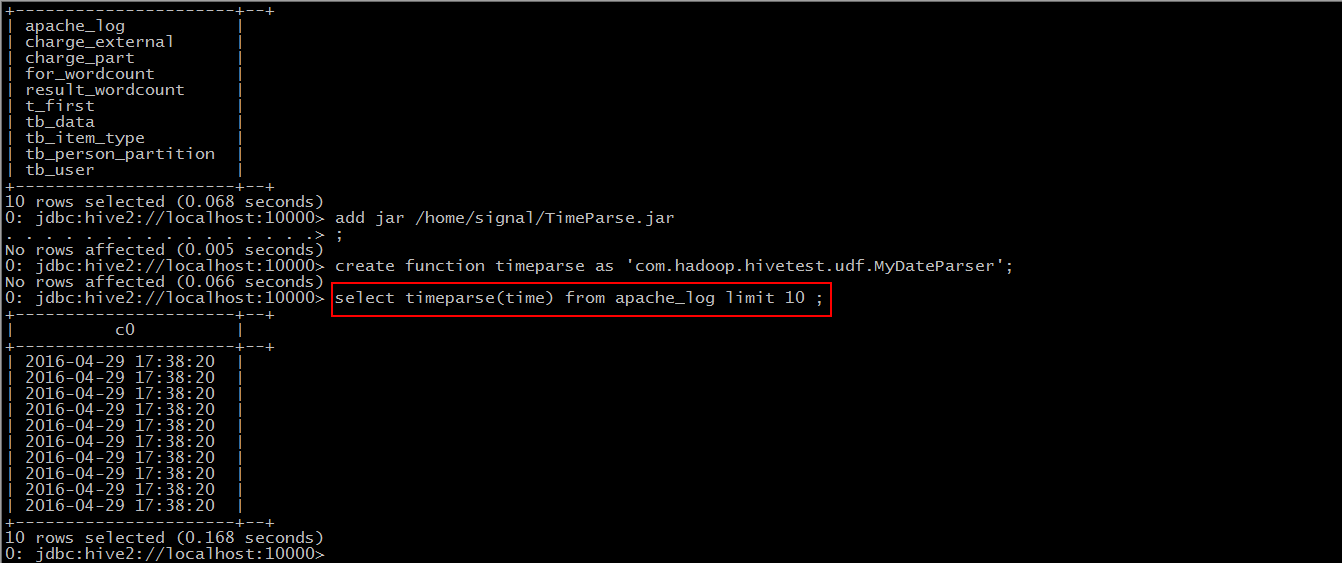
Compare the data we imported before.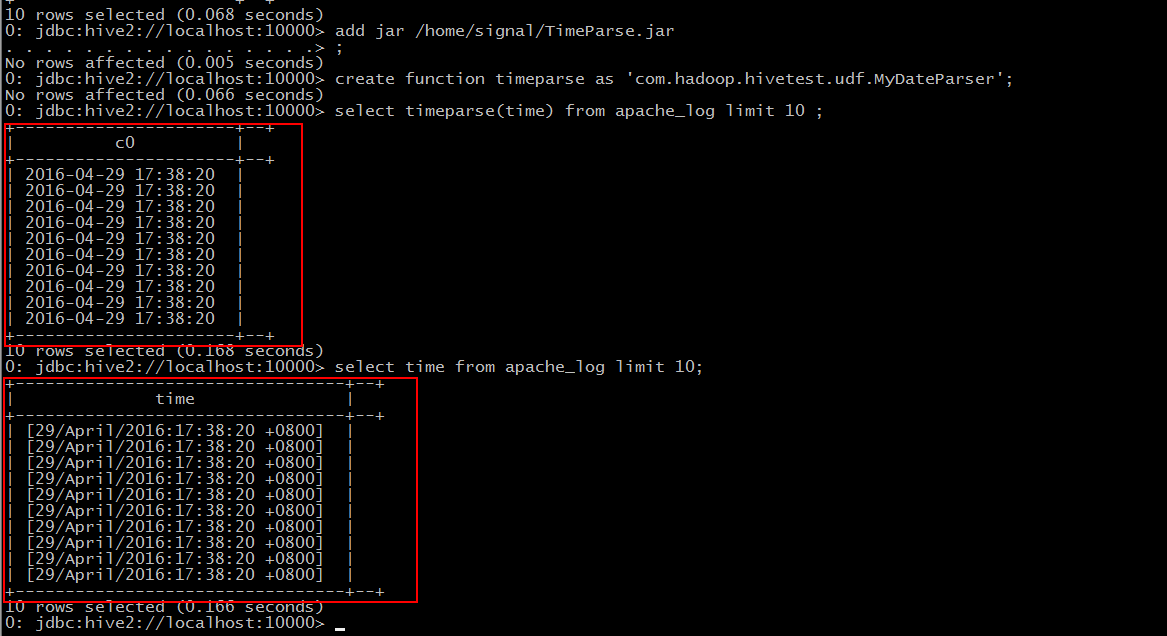
UDTF(user-defined table-generating functions)
Small demand:
For the "request" field, split it to get the user's request connection.
The first part represents the way of request, the second part is the connection of user request, and the third part is the Concorde version number.
Main points:
1. Inheritance from "org.apache.hadoop.hive.ql.udf.generic.GenericUDTF";
2. Implement three methods: initialize(), process(), close().
*JAVA Code
package com.hadoop.hivetest.udf;
import java.util.ArrayList;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class MyRequestParser extends GenericUDTF {
@Override
public StructObjectInspector initialize(ObjectInspector[] arg0) throws UDFArgumentException {
if(arg0.length != 1){
throw new UDFArgumentException("The parameters are incorrect.");
}
ArrayList<String> fieldNames = new ArrayList<String>();
ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
//Add return field settings
fieldNames.add("rcol1");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("rcol2");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("rcol3");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
//Set the return field to the return value type of the UDTF
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void close() throws HiveException {
}
//The process of processing the input and output of a function.
@Override
public void process(Object[] args) throws HiveException {
String input = args[0].toString();
input = input.replace("\"", "");
String[] result = input.split(" ");
//If the parsing error or failure occurs, all three fields are returned."--"
if(result.length != 3){
result[0] = "--";
result[1] = "--";
result[2] = "--";
}
forward(result);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
Follow the steps above to export the jar package and upload it to the Linux server. In fact, there is another way to upload documents. I will teach you next time.
Step 1: add jar "jar-path"
slightly
Step 2: create function request parse as `package name + class name'
Step 3: Use this function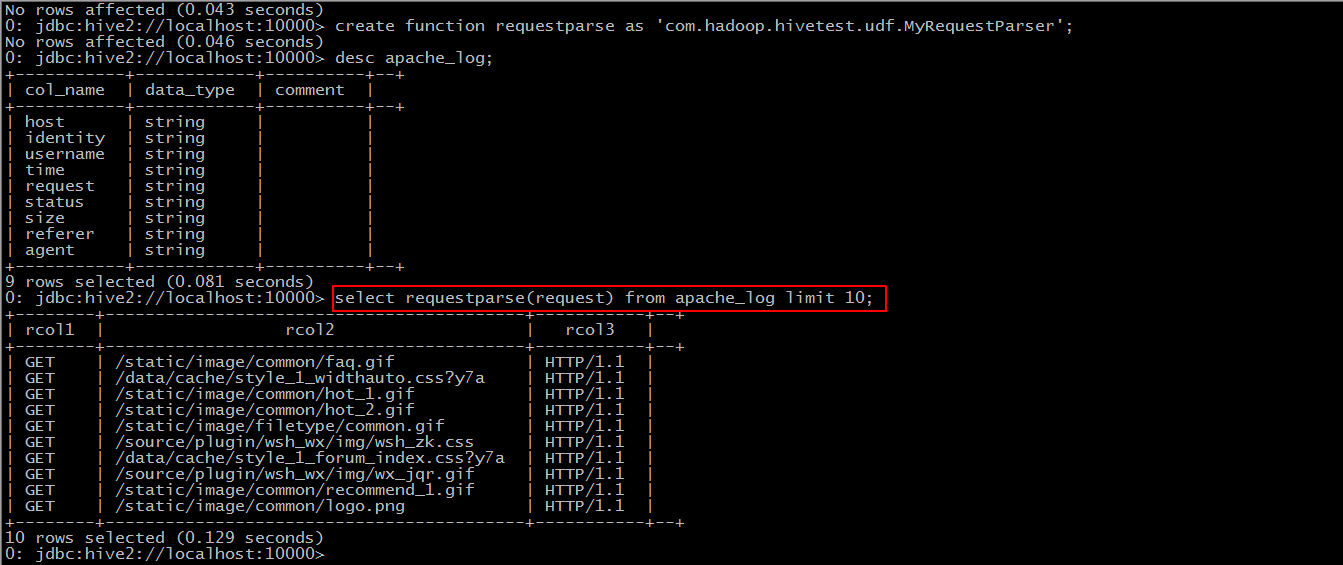
Compare the data we imported before.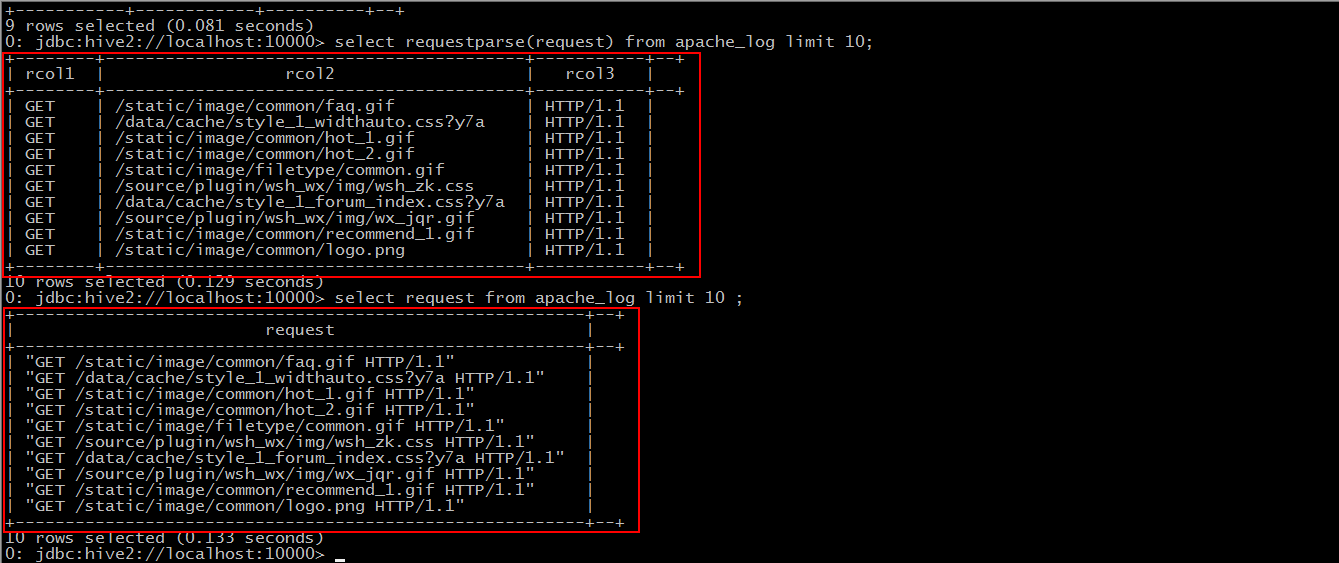
UDAF(user-defined aggregation functions)
Small demand:
Find the Maximum Flow Value
Main points:
1. Inheritance from "org.apache.hadoop.hive.ql.exec.UDAF";
2. Custom internal class implements interface "org.apache.hadoop.hive.ql.exec.UDAFEvaluator";
3. Implement four methods: iterate(), terminatePartial(), merge(), terminate().
*JAVA Code
package com.hadoop.hivetest.udf;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.io.IntWritable;
@SuppressWarnings("deprecation")
public class MaxFlowUDAF extends UDAF {
public static class MaxNumberUDAFEvaluator implements UDAFEvaluator{
private IntWritable result;
public void init() {
result = null;
}
//The aggregated value of each row in the aggregated multi-line is called the interate method, so in this method we define the aggregation rule.
public boolean iterate(IntWritable value){
if(value == null){
return false;
}
if(result == null){
result = new IntWritable(value.get());
}else{
//Demand is to find the maximum flow. Here, we compare the flow and put the maximum into the result.
result.set(Math.max(result.get(), value.get()));
}
return true;
}
//hive calls this method when it needs a partial aggregation result, returning the current result as a partial aggregation result.
public IntWritable terminatePartial(){
return result;
}
//Aggregated values, values that are not processed by new rows call merge to join the aggregation, where iterate, the aggregation rule method defined above, is called directly.
public boolean merge(IntWritable other){
return iterate(other);
}
//hive needs the method called when the final aggregation result is aggregated, returning the final aggregation result
public IntWritable terminate(){
return result;
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
Export jar package and upload it to Linux server.
Step 1: add jar 'jar-path'
slightly
Step 2: create function maxflow as `package name + class name'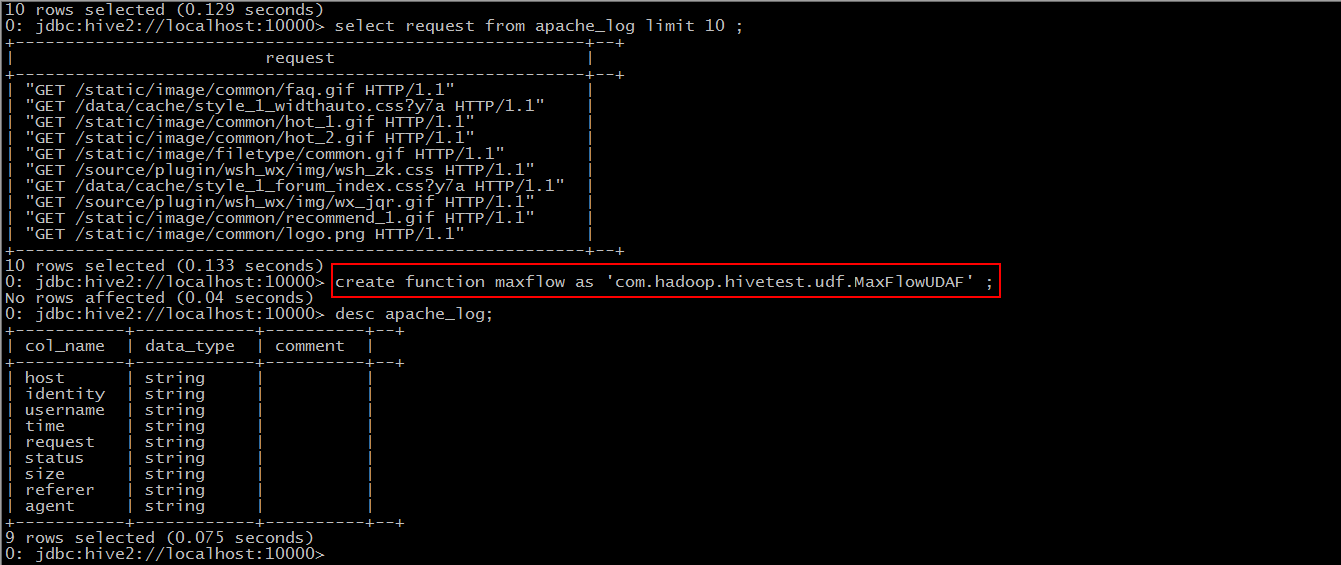
Step 3: Use this function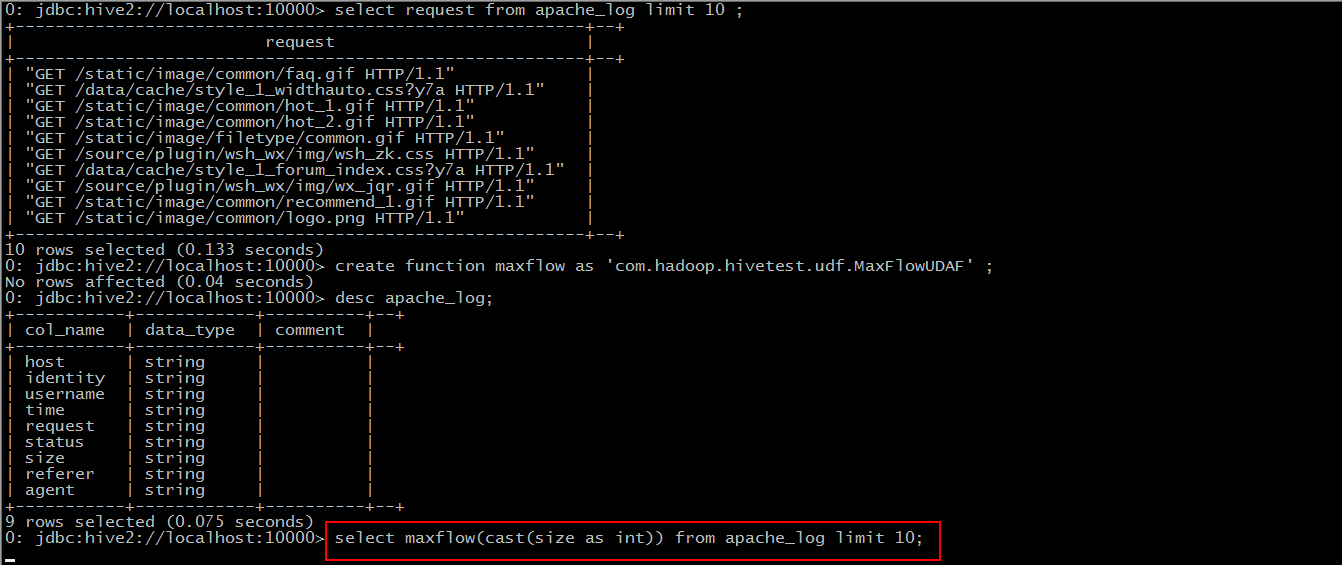
At this point, hive converts the sql statement into a mapreduce task to execute. 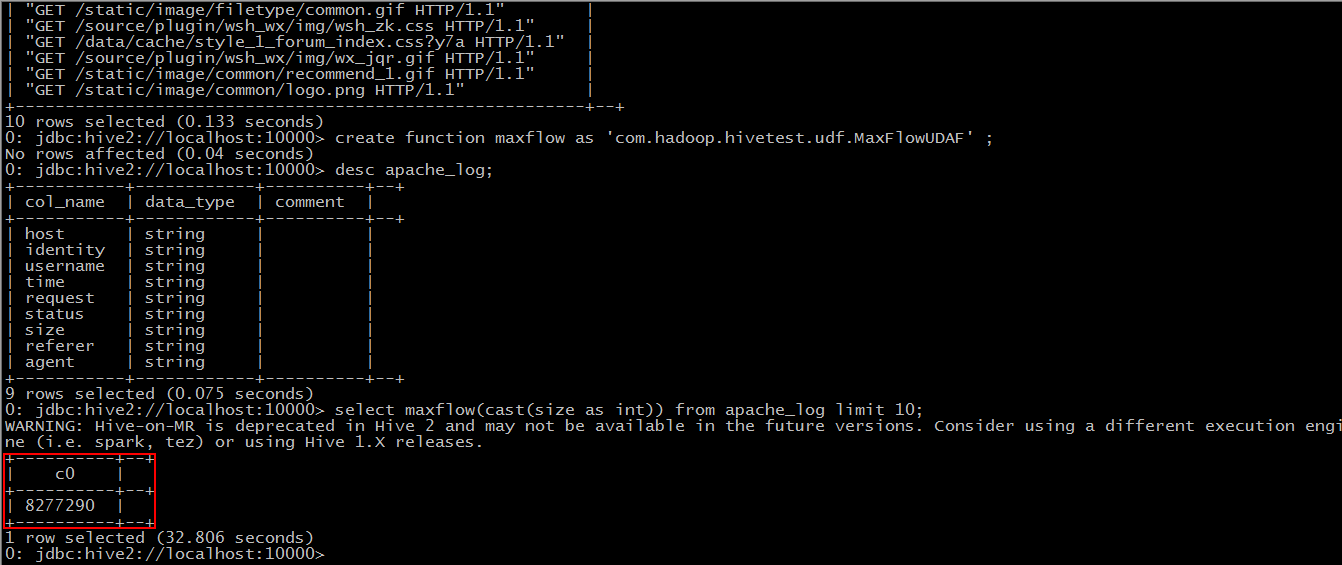
When we create a function and the result is not what we want, we modify the Java code, upload the package again, and add it to hive's classpath, but the result of the newly created function is the same as before. This is because the newly modified class name repeats the previous class name, and in the current session, the function will be created prior to the previous one. There are two ways to solve this problem. One is to disconnect the current connection, re-use the beeline client to login once, and the other is to change the modified Java class to a name, re-import, and use the new Java class to create functions.
Of course, these are just the skin of UDF. We can find that we can save writing a lot of sql by using custom functions, and by using api, we can operate fields in the database more freely, and achieve a variety of calculations and statistics.