See some recent users, code debugging in the local IDE environment after successful debugging, debugging online results do not meet expectations. Because IDE cannot simulate the scenario of distributed debugging UDAF by multiple worker s, some BUG s may need to be debugged online with some simple test data. Here we use the simplest method of manual printing logs to debug the most troublesome example of UDAF in code debugging. Through the positioning and solution of the problem, I hope to give you some ideas when facing the online debugging of UDF.
Initialization
First of all, there may be a lot of real data on the line. Don't debug hundreds of millions of data directly, otherwise it's difficult to locate the reason. In the face of online problems, it is better to simplify the calculation scenario according to the data situation. For example, here I will simplify the test data into:
drop table if exists testUDAF;
create table testUDAF(
str string
) partitioned by (ds string);
--dual Table is a table of data that I have created earlier.
insert overwrite table testUDAF partition (ds)
select str,ds from (
select 'a' as str,1 as ds from dual union all
select 'a' as str,1 as ds from dual union all
select 'b' as str,1 as ds from dual union all
select 'a' as str,2 as ds from dual union all
select 'c' as str,2 as ds from dual union all
select 'c' as str,2 as ds from dual
) a;
select * from testUDAF;
You can see that the analog data is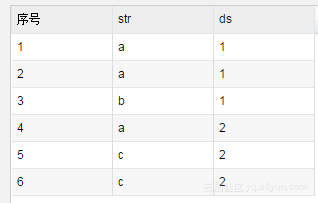
So there are six records distributed in two different partitions.
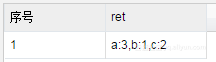
We hope that UDAF's results will be similar:
SELECT wm_concat(',', concat(str, ':', cnt)) AS ret
FROM (
SELECT str, COUNT(*) AS cnt
FROM testUDAF
GROUP BY str
) a;
Code writing
The JAVA code that has been debugged locally is as follows:
package com.aliyun.odps.udaf;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.*;
import java.util.Map.Entry;
import com.aliyun.odps.io.NullWritable;
import com.aliyun.odps.io.Text;
import com.aliyun.odps.io.Writable;
import com.aliyun.odps.udf.UDFException;
import com.aliyun.odps.udf.Aggregator;
import com.aliyun.odps.udf.annotation.Resolve;
@Resolve({"string->string"})
public class MySum extends Aggregator {
private static final String rd = ":";
private static final String fd = ",";
private static class SumBuffer implements Writable {
private HashMap<String, Long> dict = new HashMap<>();
@Override
public void write(DataOutput out) throws IOException {
String dictStr = dict.toString();
out.writeUTF(dictStr);
}
/*
* Make a simple deserialization
* */
@Override
public void readFields(DataInput in) throws IOException {
String dictStr = in.readUTF();
String[] tokens = dictStr.replace("{", "").replace("}", "").replace(" ","").split(",");
for(int i=0;i<tokens.length;i++) {
String[] strings = tokens[i].split("=");
if(strings.length==2) {
dict.put(strings[0], Long.parseLong(strings[1]));
}
}
}
}
@Override
public Writable newBuffer() {
return new SumBuffer();
}
@Override
public void iterate(Writable buffer, Writable[] args) throws UDFException {
SumBuffer iterateDictBuffer = (SumBuffer) buffer;
String content;
if (args[0] instanceof NullWritable) {
content = "Null";
} else {
content = args[0].toString();
}
Long count = iterateDictBuffer.dict.containsKey(content) ? iterateDictBuffer.dict.get(content) : 0L;
iterateDictBuffer.dict.put(content, count + 1);
}
@Override
public void merge(Writable buffer, Writable partial) throws UDFException {
SumBuffer buf = (SumBuffer) buffer;
SumBuffer p = (SumBuffer) partial;
for (Entry<String, Long> entry : p.dict.entrySet()) {
Long count = buf.dict.containsKey(entry.getKey()) ? buf.dict.get(entry.getKey()) + entry.getValue() : entry.getValue();
buf.dict.put(entry.getKey(), count);
}
}
@Override
public Writable terminate(Writable buffer) throws UDFException {
SumBuffer buf = (SumBuffer) buffer;
StringBuilder sb = new StringBuilder();
for (Entry<String, Long> entry : buf.dict.entrySet()) {
sb.append(entry.getKey()).append(rd).append(entry.getValue()).append(fd);
}
Text resault = new Text();
resault.set(sb.substring(0,sb.length()-1));
return resault;
}
}
Because the logic is not complex, no more annotations have been added. You can see that you use a Map to store intermediate data, serialize it with toString, and then write a simple piece of code to deserialize it. When terminate is reached, the required results are spelled and returned.
After packaging, register the functions and test the results:
odps@ >add jar D:\\mysum.jar -f;
OK: Resource 'mysum.jar' have been updated.
odps@ >create function mysum as com.aliyun.odps.udaf.MySum using mysum.jar;
Success: Function 'mysum' have been created.
odps@ >select mysum(str) from testUDAF;
+-----+
| _c0 |
+-----+
| a:3,b:1,c:4 |
+-----+
Investigation thought
As you can see, the value of c here does not know why it has become 4, which is a problem not found locally. Fortunately, our data volume is relatively small, so it is more convenient to locate. The current idea is that we already know exactly what data we're entering and what results we're expecting. So first we need to know where to start in the process of the step-by-step flow of intermediate data is different from what we expected. After locating where the data and expectations do not match, we combine the context code logic to locate the cause of the problem.
First, we add some abnormal printing to the code to see what the data in the flow process is. Through System.err.println, we print the information we want into stderr.
@Override
public void iterate(Writable buffer, Writable[] args) throws UDFException {
SumBuffer iterateDictBuffer = (SumBuffer) buffer;
String content;
if (args[0] instanceof NullWritable) {
content = "Null";
} else {
content = args[0].toString();
}
Long count = iterateDictBuffer.dict.containsKey(content) ? iterateDictBuffer.dict.get(content) : 0L;
System.err.println("input in iterate:" + content+"\tdict:"+iterateDictBuffer.dict); //Get the original input and current status
iterateDictBuffer.dict.put(content, count + 1);
System.err.println("output in iterate:" + iterateDictBuffer.dict); //Printingiterate Output content
}
@Override
public void merge(Writable buffer, Writable partial) throws UDFException {
SumBuffer buf = (SumBuffer) buffer;
SumBuffer p = (SumBuffer) partial;
System.err.println("buffer in merge:" + buf.dict); //Print the mergebuffer Content
System.err.println("partial in merge:" + p.dict); //Print the partial content in merge
for (Entry<String, Long> entry : p.dict.entrySet()) {
Long count = buf.dict.containsKey(entry.getKey()) ? buf.dict.get(entry.getKey()) + entry.getValue() : entry.getValue();
buf.dict.put(entry.getKey(), count);
}
System.err.println("output in merge:" + buf.dict); //Print the output in merge
}
@Override
public Writable terminate(Writable buffer) throws UDFException {
SumBuffer buf = (SumBuffer) buffer;
System.err.println("output in terminate:" + buf.dict); //Print the input in terminate
StringBuilder sb = new StringBuilder();
for (Entry<String, Long> entry : buf.dict.entrySet()) {
sb.append(entry.getKey()).append(rd).append(entry.getValue()).append(fd);
}
System.err.println(sb.substring(0,sb.length()-1)); //Print the output in terminate
Text resault = new Text();
resault.set(sb.substring(0,sb.length()-1));
return resault;
}
Print out these methods first. The main idea of printing this way is to see what the data input and output are when each call is made. So we can find out where the problem begins.
Pack, replace the jar package, and then call the function again, as you can see
odps@ >add jar D:\\mysum.jar -f;
OK: Resource 'mysum.jar' have been updated.
odps@ >select mysum(str) from testUDAF;
+-----+
| _c0 |
+-----+
| a:3,b:1,c:4 |
+-----+
The result data is unchanged, but we can look at the log. Open the logview inside and you can see: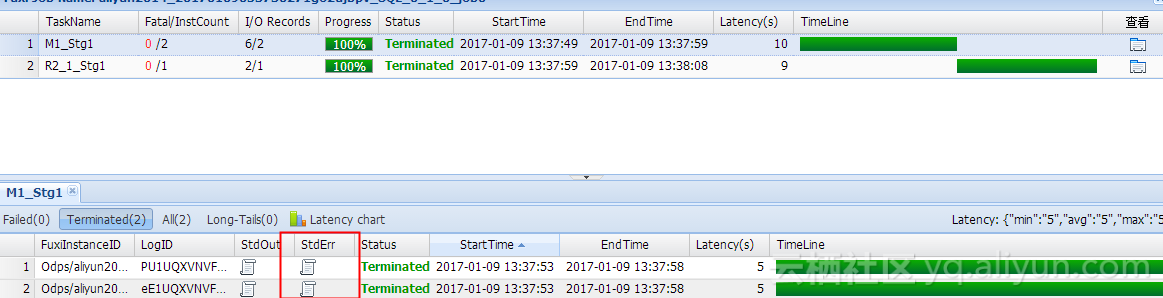
The logs in the two Map s are:
Heap Size: 1024M
input in iterate:a dict:{}
output in iterate:{a=1}
input in iterate:c dict:{a=1}
output in iterate:{a=1, c=1}
input in iterate:c dict:{a=1, c=1}
output in iterate:{a=1, c=2}
Heap Size: 1024M
input in iterate:a dict:{}
output in iterate:{a=1}
input in iterate:a dict:{a=1}
output in iterate:{a=2}
input in iterate:b dict:{a=2}
output in iterate:{a=2, b=1}
See that it's all right, and then look at the results in Reduce:
Heap Size: 1024M
buffer in merge:{}
partial in merge:{a=1, c=2}
output in merge:{a=1, c=2}
buffer in merge:{a=1, c=2}
partial in merge:{a=2, b=1, c=2}
output in merge:{a=3, b=1, c=4}
output in terminate:{a=3, b=1, c=4}
a:3,b:1,c:4
Look, partial in merge:{a=2, b=1, c=2} is not what you expected. As a matter of fact, the output in iterate:{a=2, b=1} is what we output in iterate. How can we get here to {a=2, b=1, c=2}?
This change happened when we passed between multiple worker s, we did serial number and deserialization, so we logged here again:
@Override
public void write(DataOutput out) throws IOException {
String dictStr = dict.toString();
out.writeUTF(dictStr);
System.err.println("dict in write:" + dictStr); //Print serialized output
}
/*
* Make a simple deserialization
* */
@Override
public void readFields(DataInput in) throws IOException {
String dictStr = in.readUTF();
System.err.println("dictStr in readFields:" + dictStr); //Print deserialized output
String[] tokens = dictStr.replace("{", "").replace("}", "").replace(" ","").split(",");
for(int i=0;i<tokens.length;i++) {
String[] strings = tokens[i].split("=");
if(strings.length==2) {
dict.put(strings[0], Long.parseLong(strings[1]));
}
}
System.err.println("dict in readFields:" + dict); //Print deserialized output
}
Repack and run again. This time I saw the log as follows:
--map Stage:
dict in write:{a=1, c=2}
dict in write:{a=2, b=1}
--reduce Stage:
dictStr in readFields:{a=1, c=2}
dict in readFields:{a=1, c=2}
dictStr in readFields:{a=2, b=1}
dict in readFields:{a=2, b=1, c=2}
Sure enough, the output will be a problem when deserializing. But there is no clear evidence from here about which line of code went wrong. To see that the output of dict is not up to expectations, let's first look at the time of input. Then add a line of logs:
@Override
public void readFields(DataInput in) throws IOException {
String dictStr = in.readUTF();
System.err.println("dictStr in readFields:" + dictStr); //Print deserialized output
System.err.println("dict in readFields before put:" + dict); //Print deserialized output
String[] tokens = dictStr.replace("{", "").replace("}", "").replace(" ","").split(",");
for(int i=0;i<tokens.length;i++) {
String[] strings = tokens[i].split("=");
if(strings.length==2) {
dict.put(strings[0], Long.parseLong(strings[1]));
}
}
System.err.println("dict in readFields:" + dict); //Print deserialized output
}
See the reduce phase log for this meeting
dictStr in readFields:{a=1, c=2}
dict in readFields before put:{}
dict in readFields:{a=1, c=2}
dictStr in readFields:{a=2, b=1}
dict in readFields before put:{a=1, c=2}
dict in readFields:{a=2, b=1, c=2}
Now the truth is clear. The second time we call readFields to serialize the string {a=2, b=1}, we find that the contents of dict that should have been empty are actually the result of the last calculation. In fact, in readFields, SumBuffer in the same worker is reused. In this case, in order to ensure the accuracy of the calculation, we can empty the contents of dict by ourselves.
@Override
public void readFields(DataInput in) throws IOException {
String dictStr = in.readUTF();
dict = new HashMap<>();
String[] tokens = dictStr.replace("{", "").replace("}", "").replace(" ","").split(",");
for(int i=0;i<tokens.length;i++) {
String[] strings = tokens[i].split("=");
if(strings.length==2) {
dict.put(strings[0], Long.parseLong(strings[1]));
}
}
}
}
That's right at last.
odps@ >add jar D:\\mysum.jar -f;
OK: Resource 'mysum.jar' have been updated.
odps@ >select mysum(str) from testUDAF;
+-----+
| _c0 |
+-----+
| a:3,b:1,c:2 |
+-----+
summary
There's more to optimize the code. However, in order to explain the debugging process and simplify the code logic, no more efforts have been made in this regard. The actual business code also needs to take into account performance and exception capture issues.
System.err.println is a very clumsy approach, but it works, doesn't it?