Spark reported an error when submitting the spark job
./spark-shell
19/05/14 05:37:40 WARN util.NativeCodeLoader: Unable to load native-hadoop
library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
19/05/14 05:37:49 ERROR spark.SparkContext: Error initializing SparkContext.
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException):
Operation category READ is not supported in state standby. Visit https://s.apache.org/sbnn-error
at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:88)
at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.checkOperation(NameNode.java:1826)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOperation(FSNamesystem.java:1404)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getFileInfo(FSNamesystem.java:4208)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getFileInfo(NameNodeRpcServer.java:895)
at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.getFileInfo(AuthorizationProviderProxyClientProtocol.java:527)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getFileInfo(ClientNamenodeProtocolServerSideTranslatorPB.java:824)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2086)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2082)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1693)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2080)
Cause analysis
Today, I opened Spark's history server. I used it well during the test, but later I found that the spark job could not be submitted if it could not be started.
By analyzing the log and looking at the Web interface of HDFS, it is found that my spark cannot connect to the ActiveNN of HDFS, and the only service that needs to connect to HDFS when spark starts is to write the job log, so I checked the spark-defaults.conf file that specifies the write path of the sparkJob log, and sure enough, the path specifies standByNN
spark.eventLog.dir hdfs://hadoop002:8020/g6_direcory
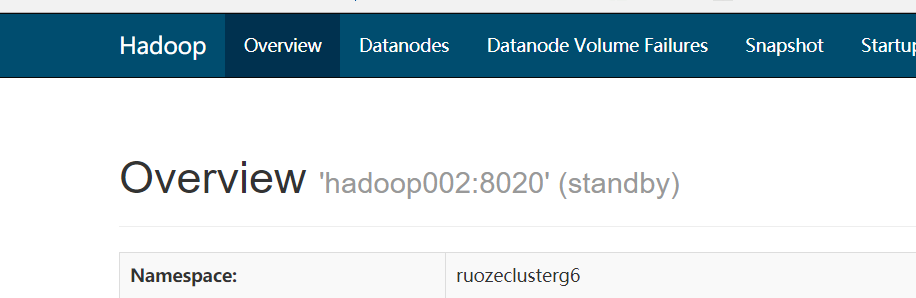
So spark can't write logs to HDFS by connecting to standByNN
Solve
Just change the path of log directory file in spark-defaults.conf and spark-env.sh from single NN to namespace
My namespace is
<property>
<name>fs.defaultFS</name>
<value>hdfs://ruozeclusterg6</value>
</property>Modify spark-defaults.conf
spark.eventLog.enabled true spark.eventLog.dir hdfs://ruozeclusterg6:8020/g6_direcory
Modify spark env.sh
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://ruozeclusterg6:8020/g6_direcory"
test
[hadoop@hadoop002 spark]$ spark-shell
19/05/14 06:00:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop002:4040
Spark context available as 'sc' (master = local[*], app id = local-1557828013138).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.2
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_131)
Type in expressions to have them evaluated.
Type :help for more information.
scala>