In this article, we will explore how to build a simple network model with triple loss. It is widely used in face verification, face recognition and signature verification. Before entering the code, let's learn what triple loss is and how to implement it in PyTorch.
Triple loss
Triple loss function is a widely used loss function at present. It was first proposed by Google research team in the paper FaceNet: A Unified Embedding for Face Recognition. The advantage of triple loss lies in the distinction of details, that is, when the two inputs are similar, triple loss can better model the details, It is equivalent to adding the measurement of the difference between two inputs to learn a better representation of the input.
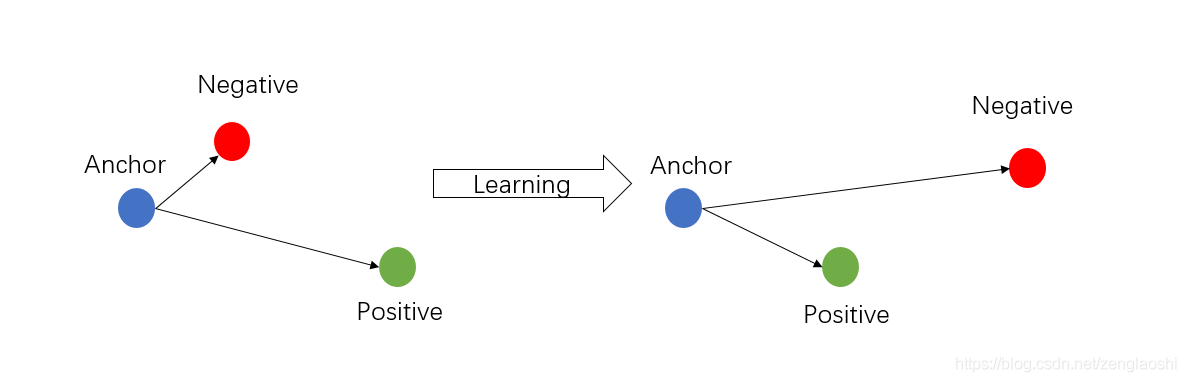
The logic here is that we take a total of three images at a time, namely our anchor, positive and negative samples. Our training method for the model is to minimize the distance between anchor and positive. The distance between anchor and negative is maximized. In order to achieve this goal, we need to use a special loss function triple loss.
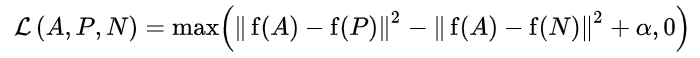
We use Euclidean distance to measure the distance between features extracted from each image. alpha in the formula refers to the boundary limit / threshold that separates positive from negative when the comparison occurs.
Let's take margin = 0.2 as an example and apply it to the above formula,
Example (1): dist (a, P) = 0.7 & dist (a, n) = 0.5 - applying this condition, we have max(0.7 – 0.5 + 0.2, 0) and get max(0.4,0) = 0.4. Whenever the distance between anchor and positive is greater than anchor and negative, the loss value will be very high. The goal of our model learning is to narrow the gap between a & P and open the space between a & n.
Case (2): dist (a, P) = 0.1 & dist (a, n) = 0.5 - in this case, the value is expected. When we put all these into the formula, we get 0 (i.e.) max(0.1 – 0.5 + 0.2, 0).
Implementation in pytoch: we create a new class for the loss function, which inherits the abstract class nn.Module and has a fixed margin of 0.2.
We also change the two main methods of the class__ init__ And forward. We use "relu" activation in forward propagation because the Euclidean distance is calculated between positive numbers. Therefore, when calculating the loss, return zero for zero and negative "relu", which is the result we need. The loss we need is mainly the value when the value in brackets is positive. Therefore, Siamese model tries to learn the mode to reduce the loss value.
#define triplet loss functionclass triplet_loss(nn.Module):
def __init__(self):
super(triplet_loss, self).__init__()
self.margin = 0.2def forward(self, anchor, positive, negative):
pos_dist = (anchor - positive).pow(2).sum(1)
neg_dist = (anchor - negative).pow(2).sum(1)
loss = F.relu(pos_dist - neg_dist + self.margin)
return loss.mean()#we can also use #torch.nn.functional.pairwise_distance(anchor,positive, keep_dims=True), which #computes the euclidean distance.
Encoder with pre training model
Now that we have defined the loss function, the next step is the model. Here, we use resnet152 and set pre trained = true, so that we can use the and training weights of Imagenet. We also keep the extracted final features to a length of 128.
#define a siamese network using ResNet152
custom_model = models.resnet152(pretrained=True)
#display the names of the individual blocks
for name, model in custom_model.named_children():
print(name)
output: conv1 bn1 relu maxpool layer1 layer2 layer3 layer4 avgpool fc
Let's show the last layer and see what it looks like,
#the last layer is the one we want to modify to 128 as this will be used for distance metric comparison custom_model.fc Linear(in_features=2048, out_features=1000, bias=True)
Since the output of the last layer is 1000, we may want to change it to 128.
in_ftrs = custom_model.fc.in_features
out_ftrs = custom_model.fc.out_features
print('number of input features of the model:', in_ftrs)
print('number of output features of the model:', out_ftrs )
output:
number of input features of the model: 2048
number of output features of the model: 1000
#now update the last layer output to a length of 128
custom_model.fc = nn.Linear(in_ftrs, 128)
#print the updated model
custom_model.fc
output:
Linear(in_features=2048, out_features=128, bias=True)
Now convert the model to use "cuda".
custom_model = custom_model.to(device)
The training steps can be given as follows,
loss_fun = triplet_loss()
optimizer = Adam(custom_model.parameters(), lr = 0.001)
for epoch in range(30):
total_loss = 0
for i, (anchor, positive, negative) in enumerate(custom_loader):
anchor = anchor['image'].to(device)
positive = positive['image'].to(device)
negative = negative['image'].to(device)
anchor_feature = custom_model(anchor)
positive_feature = custom_model(positive)
negative_feature = custom_model(negative)
optimizer.zero_grad()
loss = loss_fun(anchor_feature, positive_feature, negative_feature)
loss.backward()
optimizer.step()
The above is just the code for training. Besides the loss of three tuple, there is a similar contrastive loss. If you are interested in this, you can find the code in our official account.
Author: Nandhini