Data: Link: https://pan.baidu.com/s/1knjoihbkmall6pn6e XW Extraction code: iamy
**
’’"1 top five directors with the largest number of films"
**
import sqlite3
import pandas as pd#Common tools for data analysis
from pyecharts import Pie#Pie chart
conn=sqlite3.connect(r'D:\BaiduNetdiskDownload\navicat12\navicat\database\spider.db')#Connect to database and
//Select the corresponding table operation and use pandas to read
sql="""select * from douban_movies"""
movie=pd.read_sql(sql,conn)
print(movie.columns)#Print column names just to copy and paste...
movie_conductor=movie['conductor_name'].value_counts().head(5).to_dict()#Choose the top five directors with a large number of films
//And into a dictionary
#The following operations are specific, and both attr and v1 are in the form of lists
attr = list(movie_conductor.keys())
v1 = list(movie_conductor.values())
pie = Pie("")
pie.add("director", attr, v1, is_label_show=True)
pie.render('Top 5 directors at most.html')
The results are as follows: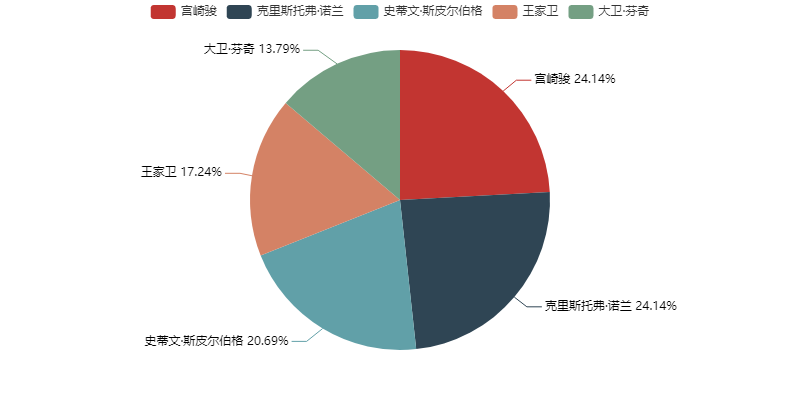
’’"2 count the number of films released by each country"
Here is a pit where attr and value are in English, while ours are in Chinese. It took us a long time to find out, so we need to make statistics by ourselves...
#The operation of connecting to the database is the same
import sqlite3
import pandas as pd
from pyecharts import Map
conn=sqlite3.connect(r'D:\BaiduNetdiskDownload\navicat12\navicat\database\spider.db')
sql="""select * from douban_movies"""
movie=pd.read_sql(sql,conn)
# print(movie.columns)
l=[]
country_dict=movie['desgin_country'].value_counts().to_dict()#Count the number of countries and turn it into a dictionary
print(country_dict)
country_list=list(country_dict.keys())#Convert to key (country) list
for countrys_list in country_list:#Traversal list
countrys=countrys_list.split('/')#Press / cut
for country in countrys:#Recirculation
if country not in l:#Add if not in empty list l
l.append(country.strip())#Remove character, default white space character
l1=list(set(l))#Duplicate removal
dt={}#Count the number of countries and their corresponding films in the dictionary
for country1 in l1:
num=0
num+=len(movie[movie['desgin_country'].str.contains(country1)])
dt[country1]=num
dt['Chinese Mainland']=dt['Chinese Mainland']+dt['Hong Kong']+dt['Taiwan']#Merge the number of Chinese movies, remove the other two keys, and then convert both the keys and values to the list
dt.pop('Hong Kong')
dt.pop('Taiwan')
value1=list(dt.values())
attr1=list(dt.keys())
#Since the world map only displays English, it can only be added manually. In addition, the United States is the United States
attr=['Austria','Netherlands','Thailand','India','Argentina','Poland','Iceland','Spain',
'China','Switzerland','Greece','United Arab Emirates','Iran','Japan','Brazil',
'Australia','Canada','Denmark','South Africa','Ireland','Czech Republic','Korea',
'Sweden','France','Zealand','United States','England','Germany','Italy']
value=[1, 1, 1, 4, 1, 1, 1, 4, 47, 4, 1, 1, 2, 33, 2, 5, 7, 1, 2, 1, 1, 8, 2, 19, 3, 131, 31, 18, 9]
print(attr1)
print(value1)
map0 = Map("World map", width=1200, height=600)
map0.add("World map", attr, value, maptype="world",is_visualmap=True, visual_text_color='#000')#
map0.render('World map.html')
The results are as follows: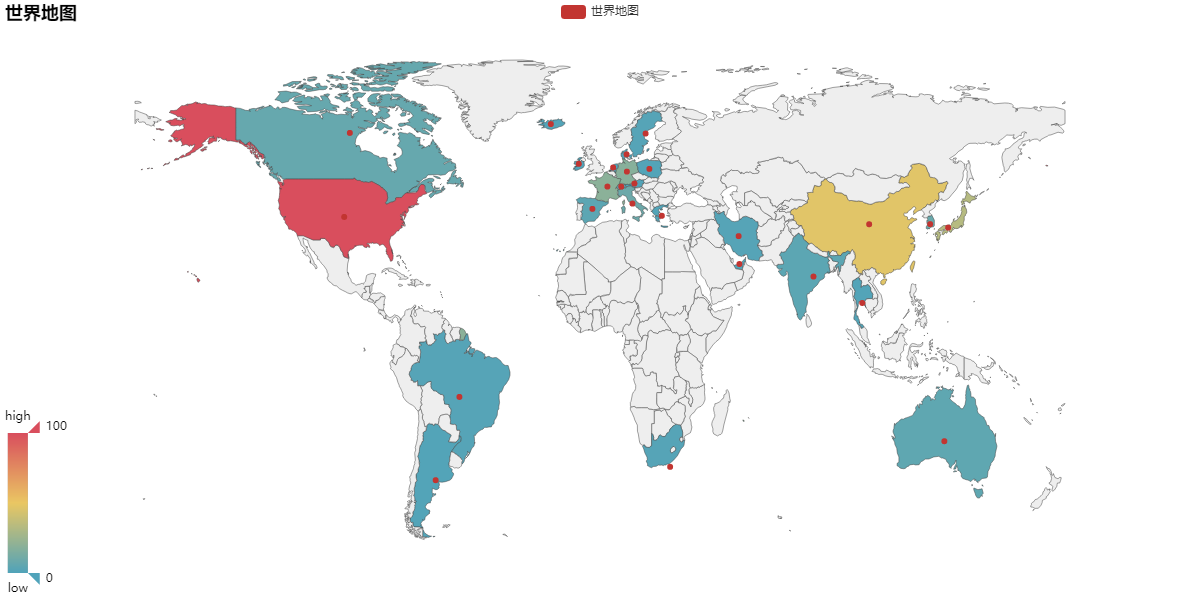
’’"3. Find 4 movies with the highest ratings"
# The operation of connecting to the database is the same
import sqlite3
import pandas as pd
conn=sqlite3.connect(r'D:\BaiduNetdiskDownload\navicat12\navicat\database\spider.db')
sql="""select * from douban_movies"""
movie=pd.read_sql(sql,conn)
# print(movie.columns)
#Select the last four scores according to the score grouping statistics
rating_dict=movie.loc[:,['movie_name','rating_num']].groupby('rating_num').size().tail(4).to_dict()
rating_list=list(rating_dict.keys())
rating_list.sort(reverse=True)#Reverse sorting
print(rating_list)
#Loop to find movies that match ratings
for rating in rating_list:
print(movie[movie['rating_num']==rating]['movie_name'])
print(type(rating))
The results are as follows:
’’"4. Count the number of movie types"
# The operation of connecting to the database is the same
import sqlite3
import pandas as pd
from pyecharts import Bar
conn=sqlite3.connect(r'D:\BaiduNetdiskDownload\navicat12\navicat\database\spider.db')
sql="""select * from douban_movies"""
movie=pd.read_sql(sql,conn)
# print(movie.columns)
dt2={}#Empty dictionary is used to store type and corresponding quantity
type_list=movie['type_name'].to_list()#Type to list
print(type_list)
#Loop traversal counts each type. Since a movie can belong to different types, loop list for the first time and loop content for each type for the second time
for i in type_list:
i_list=i.split(',')
for j in i_list:
if j not in dt2:
dt2[j]=1#Type is not in dictionary, number of types is 1
else:
dt2[j]+=1#Add 1 to the dictionary
print(dt2)
type_name=list(dt2.keys())
type_num=list(dt2.values())
bar=Bar('Movie genre')
bar.add('Bean paste',type_name,type_num,mark_point=['average'])#,is_stack=True
bar.render('Movie genre.html')
The results are as follows: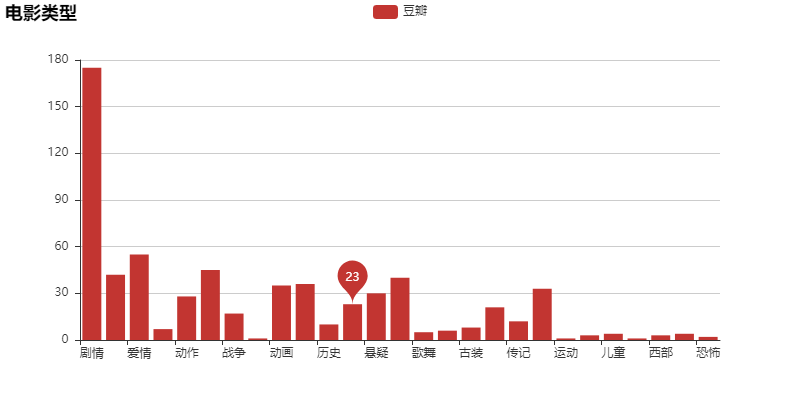
This is the basic analysis.