
Preface
If you often read the Python crawler related public numbers, they will be displayed in the form of crawler + data analysis. This is very interesting and the charts are very good. Today, I will share with you one of the last works in training: cat eye movie crawler and analysis.
Through the crawler of the top 100 list of cat's eye movies, and then the visualization, let the students realize that the small data crawler can also play such a pattern.
Reptile
Crawler analysis
Here is the movie data of top100, which is crawled across pages. The fields obtained are: movie name, starring, release time, score, movie type and duration. Finally, it is saved in the csv file.
Crawler code
import requests from lxml import etree import csv headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } def get_url(url): res = requests.get(url,headers=headers) html = etree.HTML(res.text) infos = html.xpath('//dl[@class="board-wrapper"]/dd') for info in infos: name = info.xpath('div/div/div[1]/p[1]/a/text()')[0] info_url = 'http://maoyan.com' + info.xpath('div/div/div[1]/p[1]/a/@href')[0] star = info.xpath('div/div/div[1]/p[2]/text()')[0].strip() release_time = info.xpath('div/div/div[1]/p[3]/text()')[0].strip() score_1 = info.xpath('div/div/div[2]/p/i[1]/text()')[0] score_2 = info.xpath('div/div/div[2]/p/i[2]/text()')[0] score = score_1 + score_2 # print(name,star,release_time,score,info_url) get_info(info_url,name,star,release_time,score) def get_info(url,name,star,time,score): res = requests.get(url, headers=headers) html = etree.HTML(res.text) style = html.xpath('/html/body/div[3]/div/div[2]/div[1]/ul/li[1]/text()')[0] long_time = html.xpath('/html/body/div[3]/div/div[2]/div[1]/ul/li[2]/text()')[0].split('/')[1].strip() print(name,star,time,score,style,long_time) writer.writerow([name,star,time,score,style,long_time]) if __name__ == '__main__': fp = open('maoyan_2.csv','w',encoding='utf-8',newline='') writer = csv.writer(fp) writer.writerow(['name','star','time','score','style','long_time']) urls = ['http://maoyan.com/board/4?offset={}'.format(str(i)) for i in range(0, 100, 10)] for url in urls: get_url(url)
Data analysis
Data analysis I made PPT, you can see~
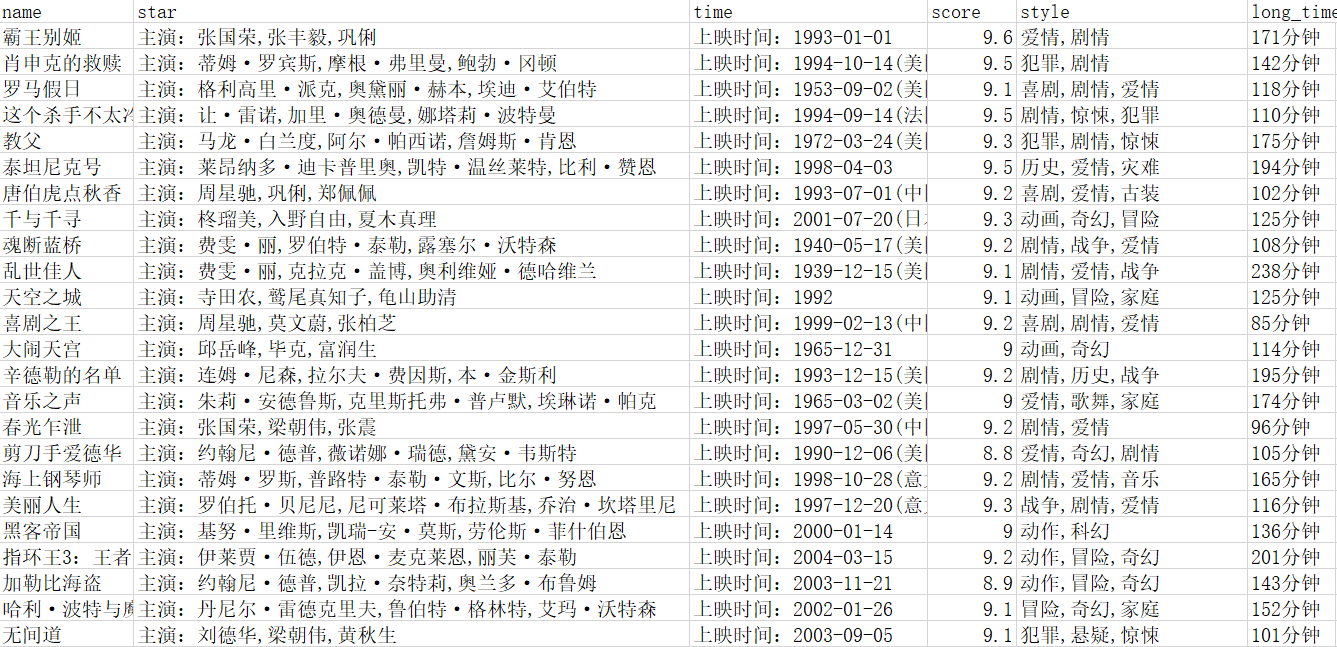
Overall situation
100 films, with an average score of 9.0 and an average film duration of 128.63.
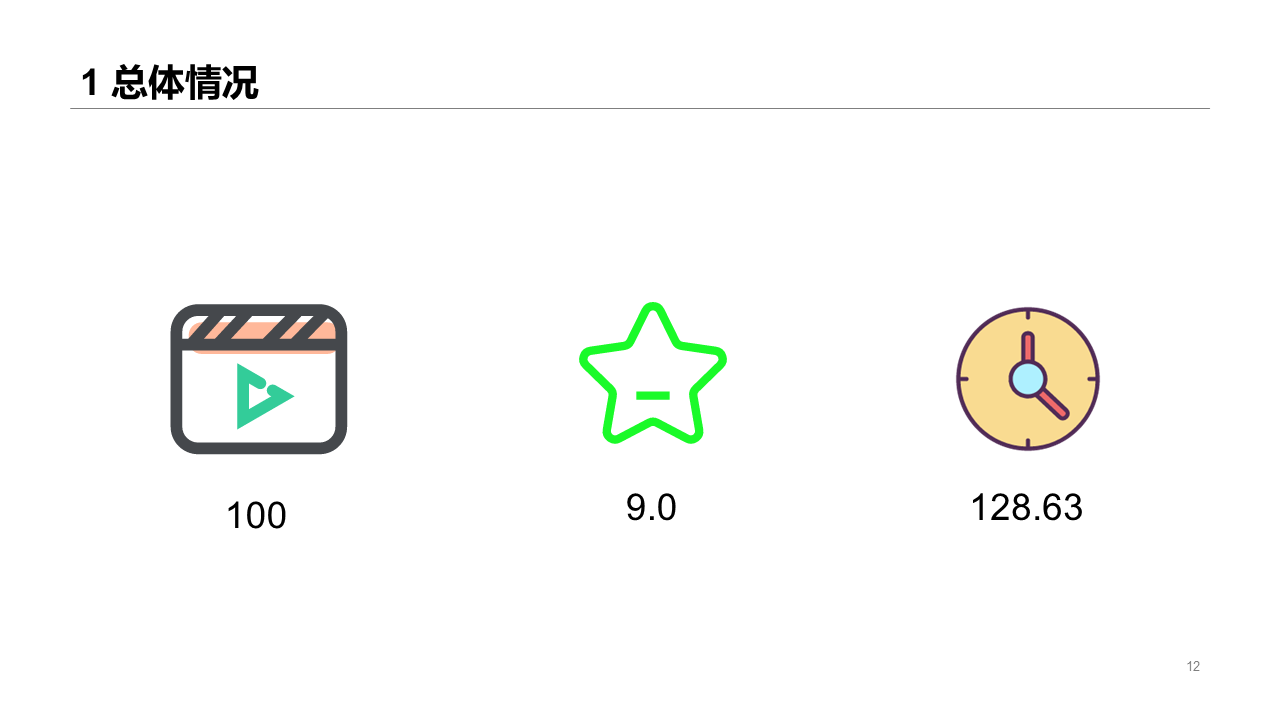
Movie year trend
The trend of movie year is not obvious.
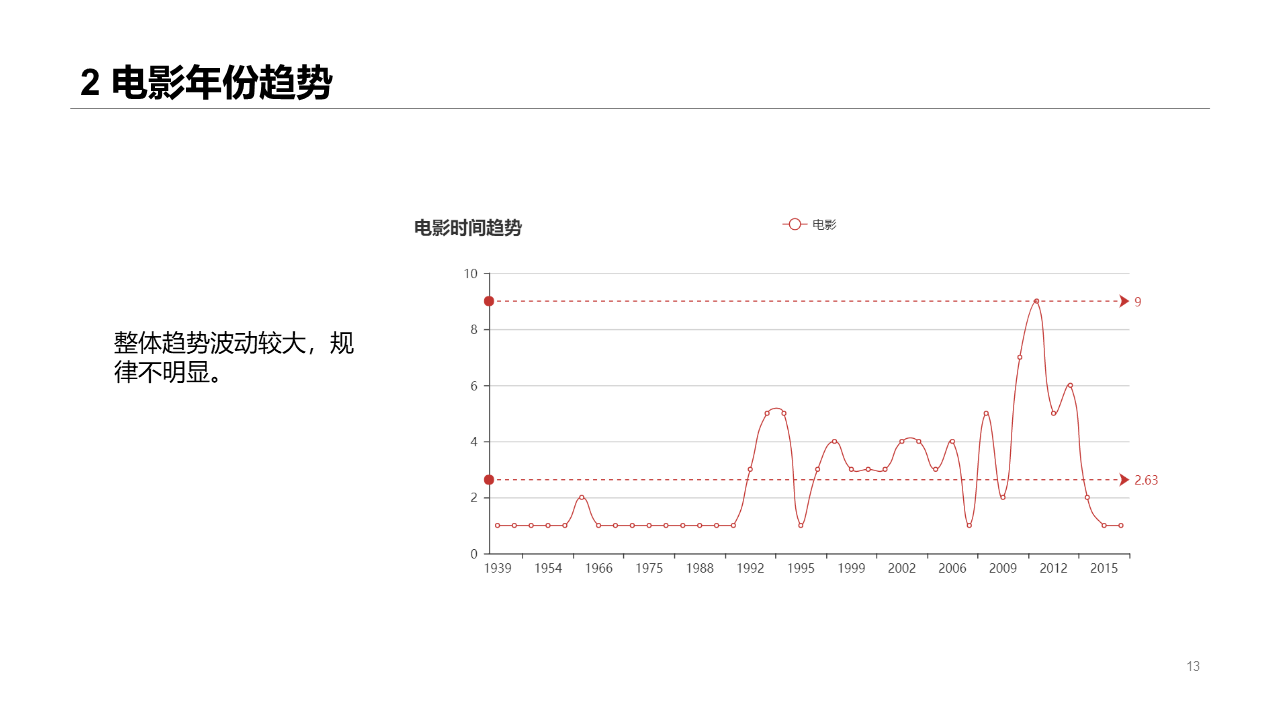
Movie month
As you all know, movies are more popular in the holidays. According to statistics, movies in the second half of the year are much better than those in the first half~
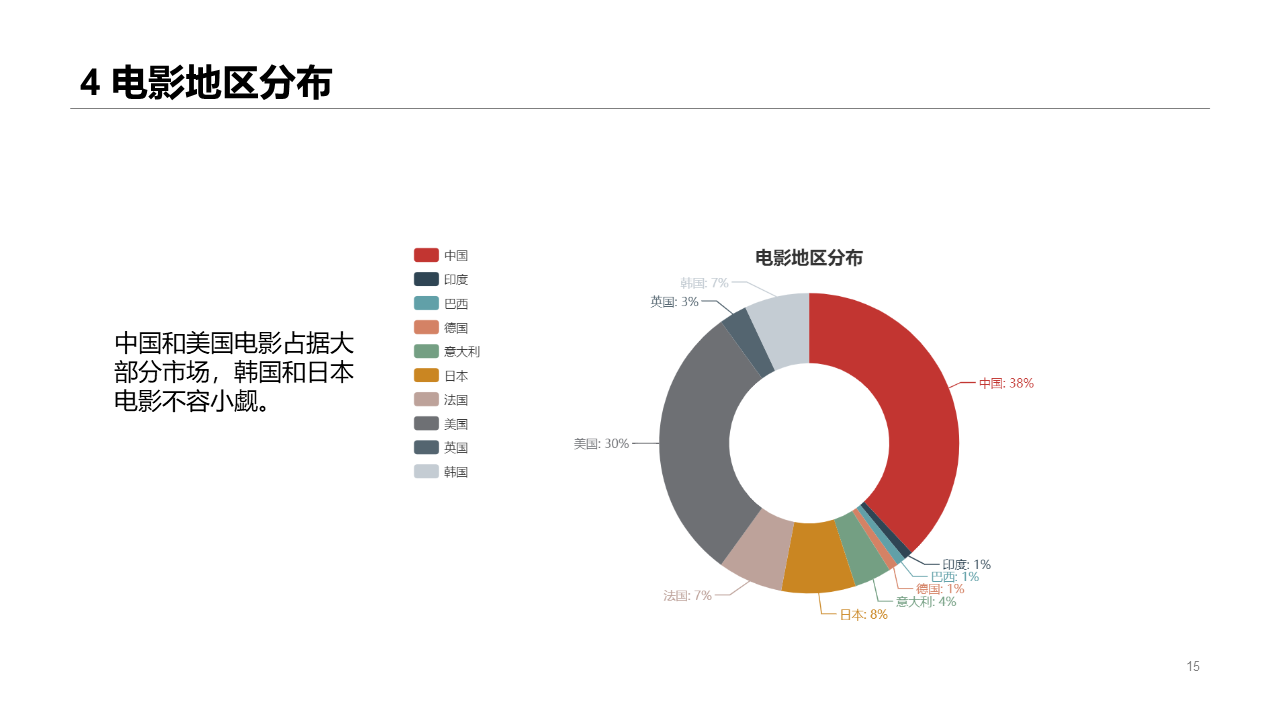
region
China and the United States still account for a lot, and Korean and Japanese films are also very good~
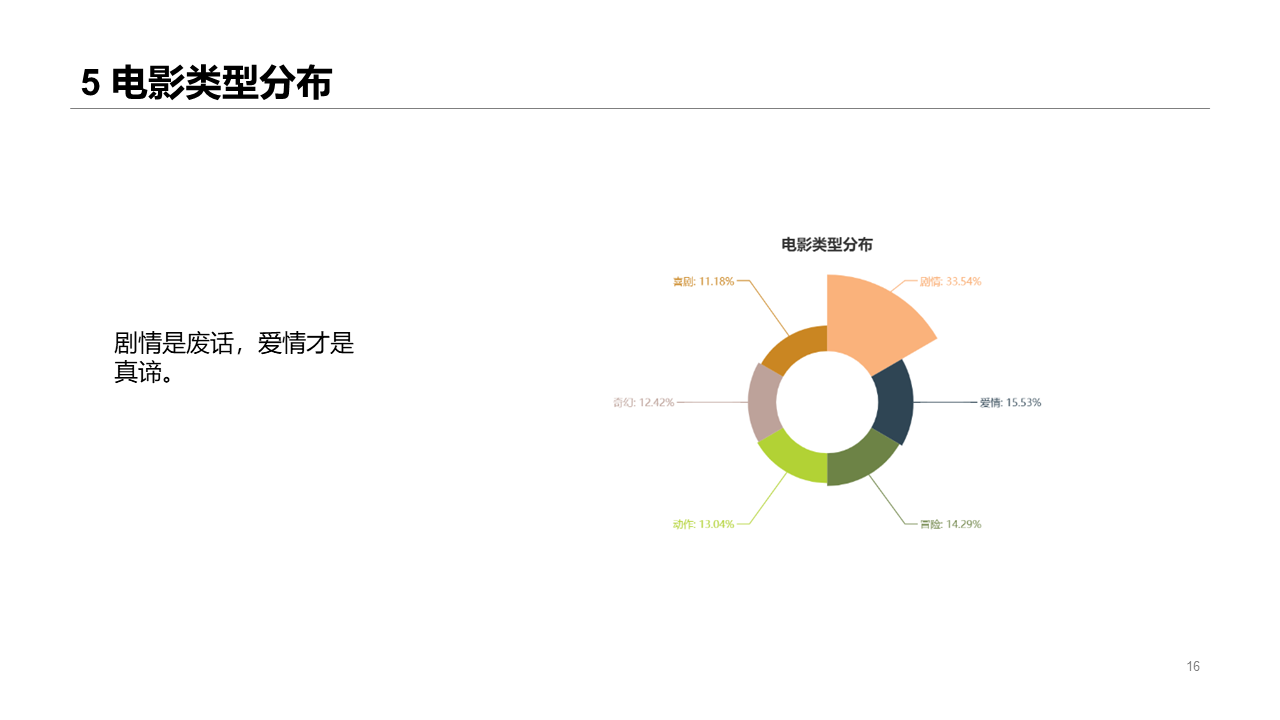
Movie genre
Most of the movie is plot, love is the essence.
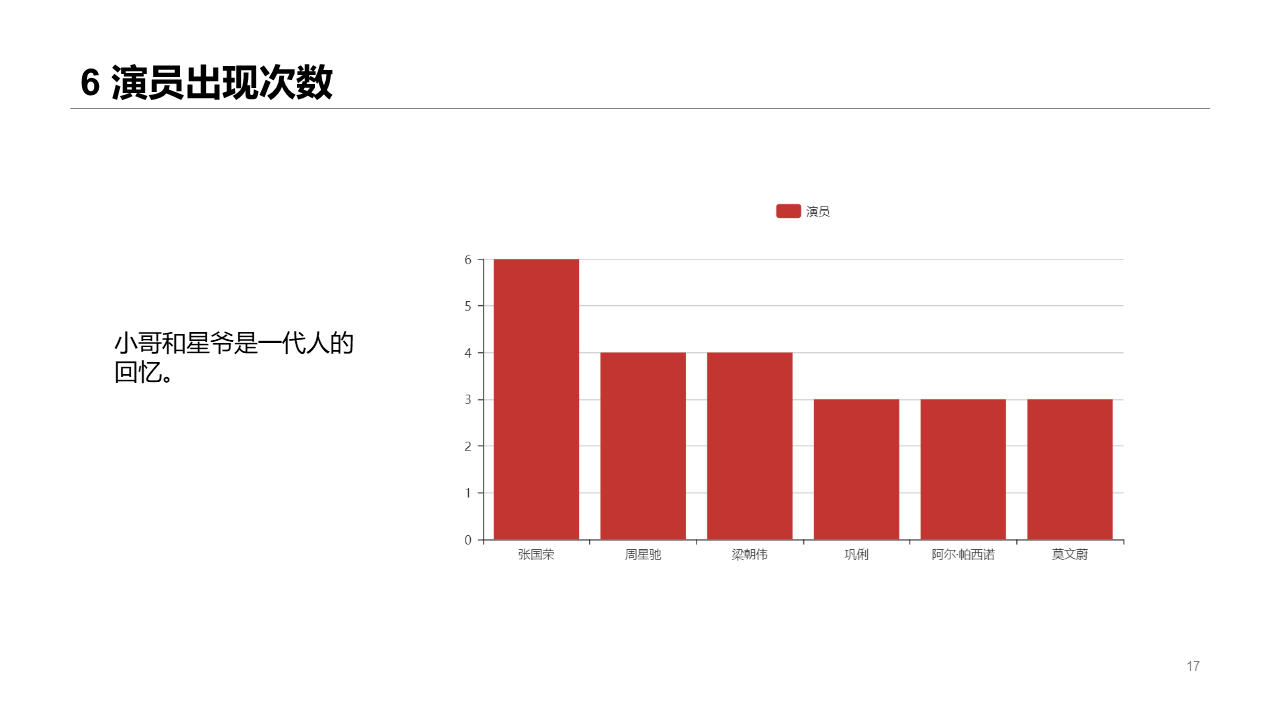
performer
Little brother and Xingye bear our understanding~
summary
Don't look at this small 100 pieces of data, it can also play a different pattern. Pay attention to the public number: Luo Luo pan, reply (cat eye movie), you can get crawler + data analysis code.