preface
Tip: Here you can add the general contents to be recorded in this article:
For example, with the continuous development of artificial intelligence, machine learning technology is becoming more and more important. Many people have started learning machine learning. This paper introduces the basic content of machine learning.
Tip: the following is the main content of this article. The following cases can be used for reference
step
1. Import library
import pandas as pd from sklearn.tree import DecisionTreeClassifier #Classification tree from sklearn.model_selection import train_test_split #Partition test set and training set from sklearn.model_selection import GridSearchCV #Do grid search to adjust parameters from sklearn.model_selection import cross_val_score #Do cross validation import numpy as np import matplotlib.pyplot as plt
2. Use pandas to read csv files
data = pd.read_csv('data.csv')
3. Explore the information of csv file
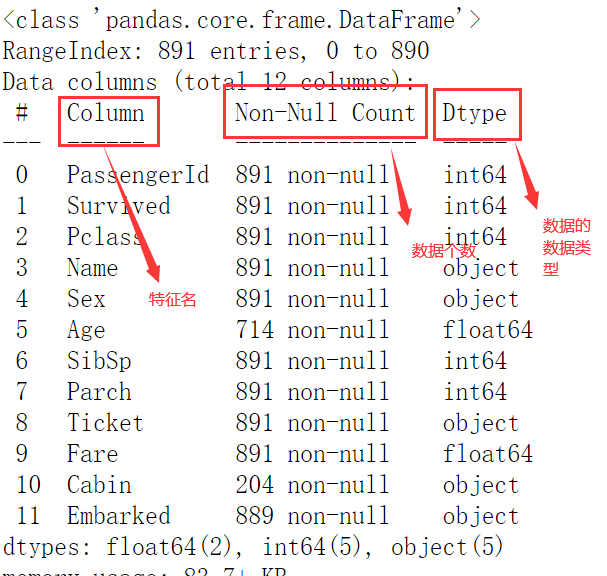
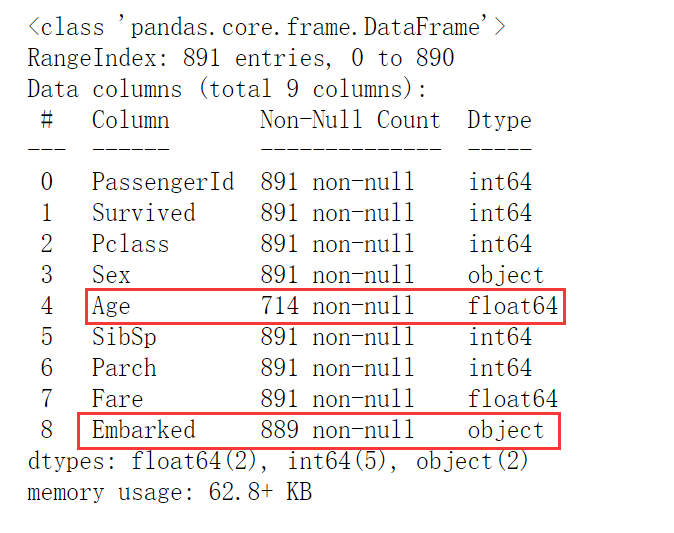
Basic information of data
data.info()
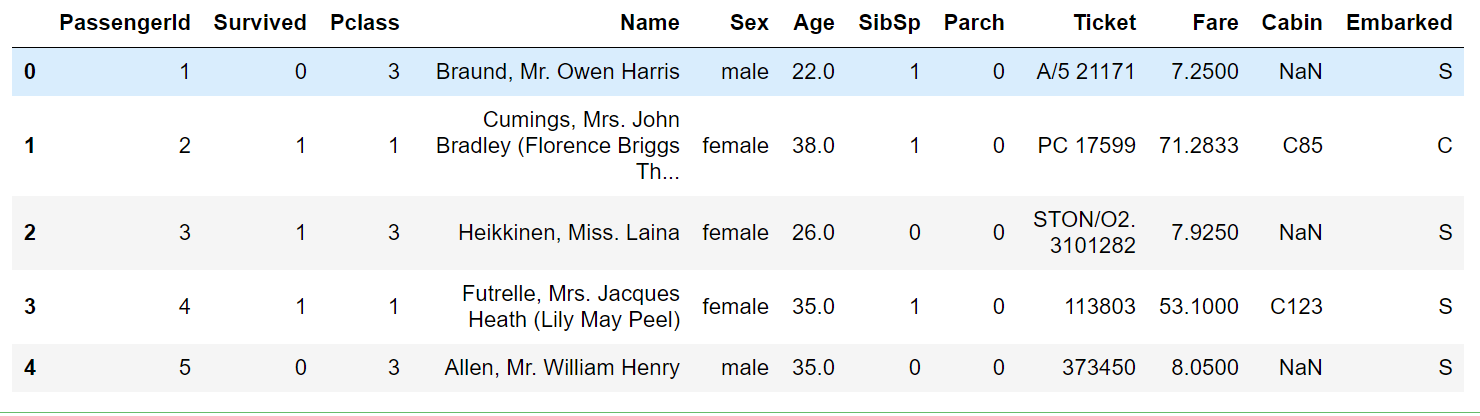
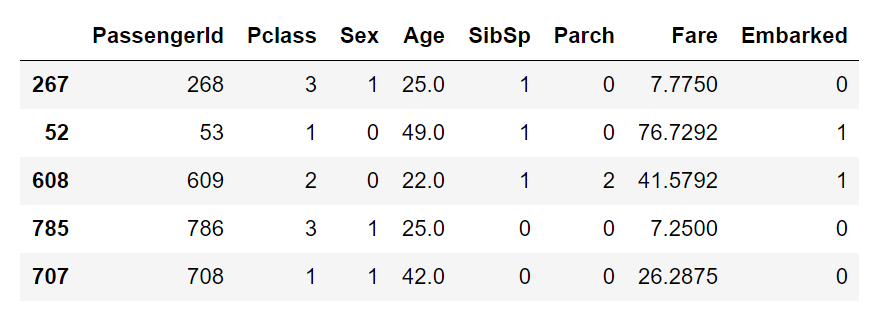
The first five lines of data to see what it looks like
data.head()
4. Data preprocessing
4.1 features irrelevant to the training model will be deleted
It can be seen from the example above that name, ticket and cabin are basically invalid for the training model, so unnecessary features are deleted
data.drop(['Name','Ticket','Cabin'],inplace=True,axis=1) ''' axis=1 : Indicates to delete this column inplace=True : Indicates that the original is overwritten data ''' data.head() data.info()
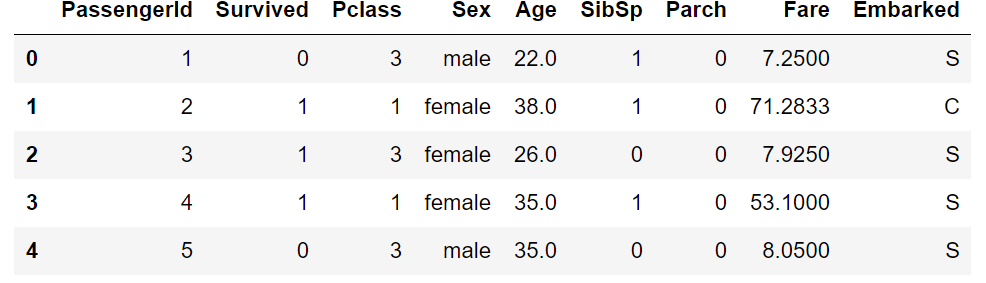

4.2 convert all non numeric features to numeric features
Note: the model can only process data of numeric type
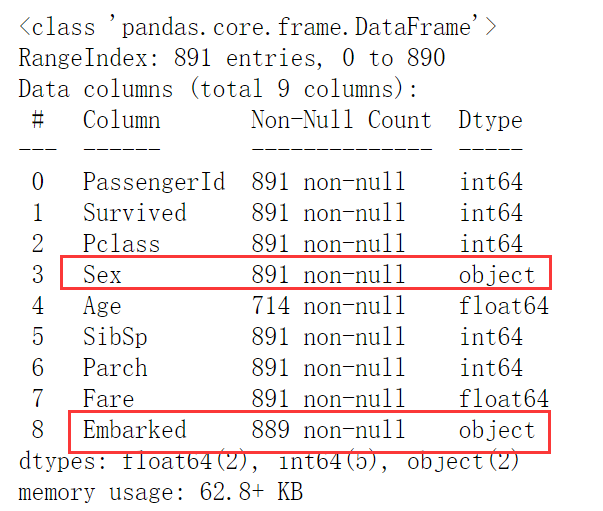
Conduct type conversion for Sex (gender is only male and female, so it is binary classification. For binary classification, there is a simple method)
data.loc[:,'Sex'] = (data.loc[:,'Sex'] == 'male').astype('int')
'''
loc[:,'Sex']: Representative take out data All the lines inside, Sex column
(data.loc[:,'Sex'] == 'male')Judge whether it is True,Returned is bool Type, will bool Type to int Type, at this time True Is 1, False Is 0
'''
Type change Embarked
label = data.loc[:,'Embarked'].unique().tolist() #The array obtained by converting the original embanked type to label is shown in the following table (int) data.loc[:,'Embarked'] = data.loc[:,'Embarked'].apply(lambda x: label.index(x)) >label: ['S', 'C', 'Q'] ''' unique: take Embaeked Take out all the data in and merge them repeatedly tolist: Convert the resulting array to a list type apply: Use functions in parentheses '''
4.3 quantity of unified data
For Age, fill in fillna, and fill in those without Age with average Age
data.loc[:,'Age'] = data.loc[:,'Age'].fillna(data.loc[:,'Age'].mean())
For embanked, only two values are missing. Delete these two lines for all features without much impact on the whole
data = data.dropna(axis=0) ''' dropna: Filter missing data data.dropna(how = 'all') # When this parameter is passed in, only those rows with all missing values will be discarded data.dropna(axis = 1) # Discard columns with missing values (this is not usually done, which will delete a feature) data.dropna(axis=1,how="all") # Discard those columns that are all missing values data.dropna(axis=0,subset = ["Age", "Sex"]) # Discard rows with missing values in the 'Age' and 'Sex' columns '''

5. Split the data set and separate the data features and labels (separate the survived results from the rest of the data)
x = data.loc[:,data.columns != 'Survived'] y = data.loc[:,data.columns == 'Survived']
6. Divide the data set into training set and test set
Xtrain, Xtest, Ytrain, Ytest = train_test_split(x,y,test_size=0.3)
7. Sort the divided test sets and training sets (form a habit)
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
8. Train the model
The training of the model is to try more and find the best
Train the model directly normally
clf = DecisionTreeClassifier(random_state=20) clf = clf.fit(Xtrain,Ytrain) score_ = clf.score(Xtest,Ytest)
Use cross validation to train
score = cross_val_score(clf,x,y,cv=10).mean()
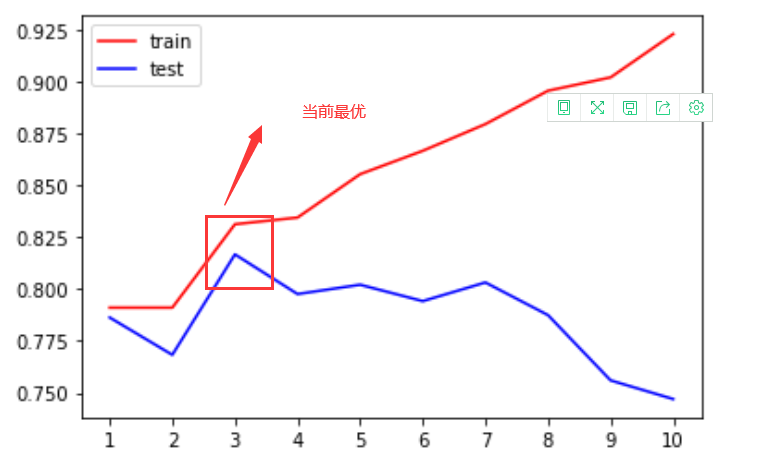
For cross validation to plot, look at the score values at different depths
tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=20
,max_depth = i+1
,criterion = 'entropy'
)
clf = clf.fit(Xtrain,Ytrain)
score_tr = clf.score(Xtrain,Ytrain)
score_te = cross_val_score(clf,x,y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
plt.figure()
plt.plot(range(1,11),tr,color='red',label='train')
plt.plot(range(1,11),te,color='blue',label='test')
plt.xticks(range(1,11))
plt.legend()
plt.show()
9. Adjust the optimal parameters through grid search
The parameters in paramters are combined according to the requirements. If there are too many computers, it is best to combine them in pairs
paramters = {'splitter': ('best','random')
,'criterion': ('gini','entropy')
,'max_depth': [*range(1,10)] #A 1-10 list [* range()]
,'min_samples_leaf': [*range(1,50,5)]
,'min_impurity_decrease': [*np.linspace(0,0.5,20)]
}
clf = DecisionTreeClassifier(random_state=20)
GS = GridSearchCV(clf,paramters,cv=10) #Grid search integrates all steps such as cross validation
GS.fit(Xtrain,Ytrain)
Optimal parameters
GS.best_params_

Evaluation value under current optimal parameters
GS.best_score_
be careful
For the above grid search, the optimal parameter is the optimal value in the content that must contain the above added parameters, that is to say, the grid search does not
To delete the parameters added to the search, it is possible that after deleting some parameters, the evaluation value will become higher, so we need to constantly debug ourselves. No
Break the test to find the optimal evaluation value
For the learning of decision tree, see the following link:
Introduction to decision tree, there are links to learning related to decision tree below