1, TiDB Binlog
In the previous article, we introduced the use of TiDB Binlog to synchronize data to downstream Mysql. In this article, we learn to use TiDB Binlog tool to synchronize data to custom business logic in Kafka. For example, TIDB can synchronize data with ES, MongoDB or Redis. This function is not different from the binlog function of Canal for parsing Mysql. If you don't know the of TiDB Binlog tool, you can also refer to my last blog:
https://blog.csdn.net/qq_43692950/article/details/121597230
Note: please ensure that the Kafka environment has been configured before doing the experiment: for those who do not understand, please refer to the following my blog:
Establishment and use of message oriented middleware KafKa cluster: https://blog.csdn.net/qq_43692950/article/details/110648852
2, TiDB Binlog configuration
In the previous article, we used tiup to expand a pump and a drainer. Let's take a look at the current cluster architecture:
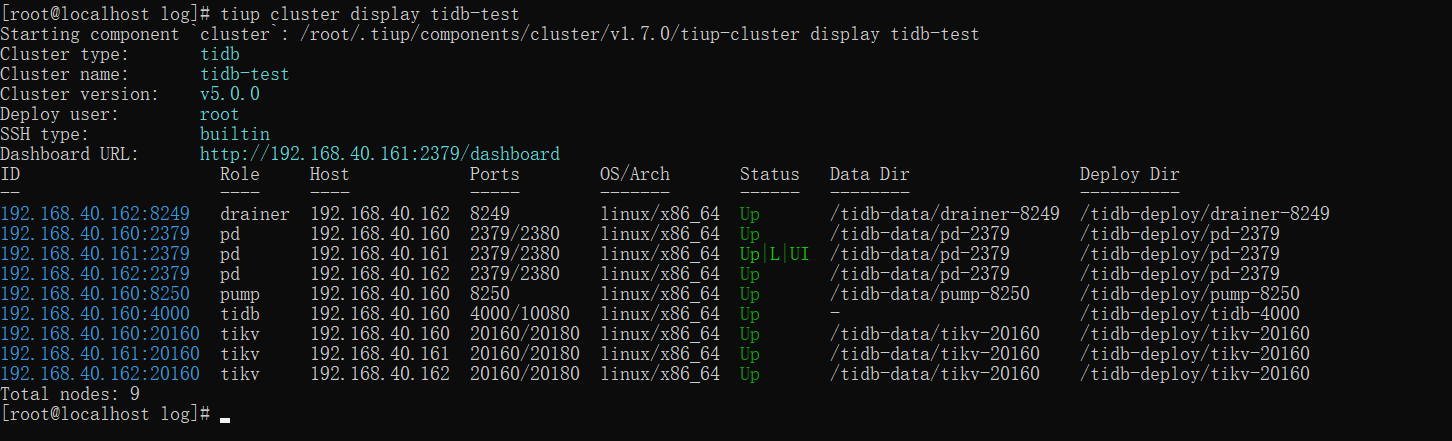
However, in the previous article, we explained the synchronization between TIDB and Mysql. If you change to Kafka, you only need to modify the configuration file. However, considering that some small partners may not have seen our previous series of tutorials, here we still expand the capacity of pump and drainer through capacity expansion. If pump and drainer have been installed, you can directly modify the configuration:
tiup cluster edit-config tidb-test
drainer_servers:
- host: 192.168.40.162
ssh_port: 22
port: 8249
deploy_dir: /tidb-deploy/drainer-8249
data_dir: /tidb-data/drainer-8249
log_dir: /tidb-deploy/drainer-8249/log
config:
syncer.db-type: kafka
syncer.to.kafka-addrs: 192.168.40.1:9092
syncer.to.kafka-version: 2.6.0
syncer.to.topic-name: tidb-test
arch: amd64
os: linux
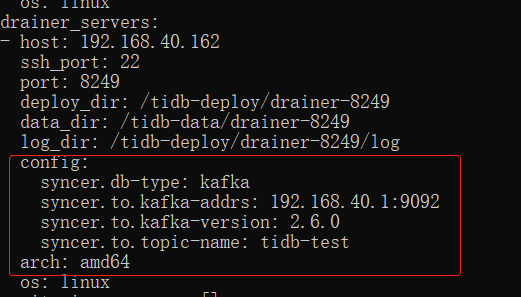
Modify the direction of the above kafka. If it is a kafka cluster, separate it with an English comma.
Next, let's talk about the capacity expansion method. If pump and drainer are not installed, use the following method:
Write expansion configuration
vi scale-out-binlog.yaml
Write the following:
pump_servers:
- host: 192.168.40.160
ssh_port: 22
port: 8250
deploy_dir: /tidb-deploy/pump-8250
data_dir: /tidb-data/pump-8250
log_dir: /tidb-deploy/pump-8250/log
config:
gc: 7
storage.stop-write-at-available-space: 200MB
arch: amd64
os: linux
drainer_servers:
- host: 192.168.40.162
ssh_port: 22
port: 8249
deploy_dir: /tidb-deploy/drainer-8249
data_dir: /tidb-data/drainer-8249
log_dir: /tidb-deploy/drainer-8249/log
config:
syncer.db-type: kafka
syncer.to.kafka-addrs: 192.168.40.1:9092
syncer.to.kafka-version: 2.6.0
syncer.to.topic-name: tidb-test
arch: amd64
os: linux
Note that the storage.stop-write-at-available-space parameter means that binlog write requests will not be received when the storage space is lower than the specified value. The default is 10G. If the hard disk is not so large, turn it down a little.
Start capacity expansion:
tiup cluster scale-out tidb-test scale-out-binlog.yaml -u root -p
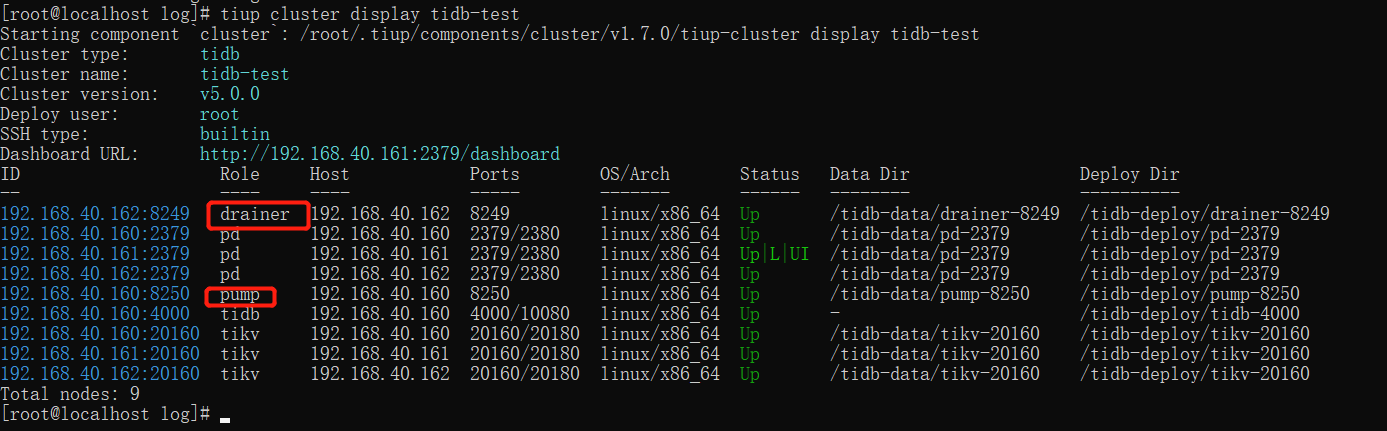
After a while, you can see that there are pump s and drainer in the cluster:
The next step is to enable the bindog configuration of TIDB:
tiup cluster edit-config tidb-test
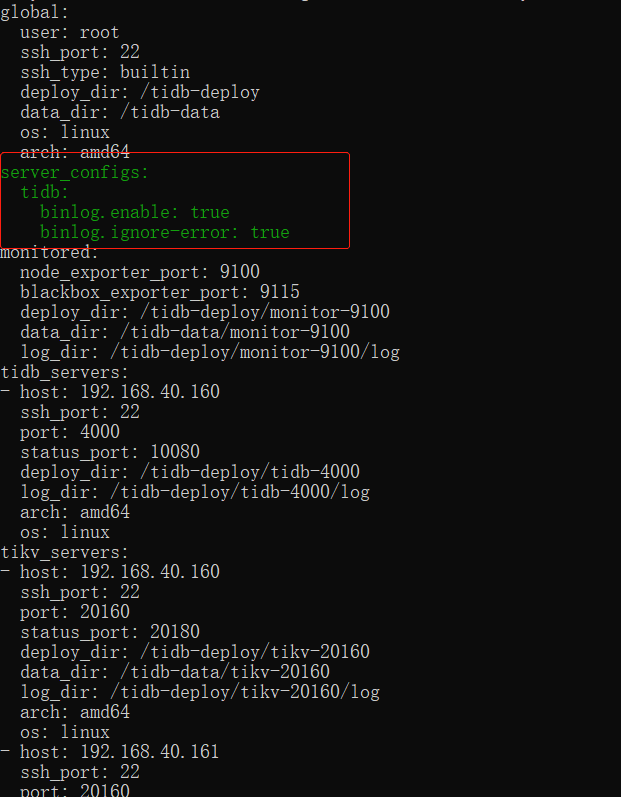
Modify server_ Configuration of configs:
server_configs:
tidb:
binlog.enable: true
binlog.ignore-error: true
Reload cluster:
tiup cluster reload tidb-test
Use the mysql client to connect to tidb and check whether bnlog is enabled:
show variables like "log_bin";
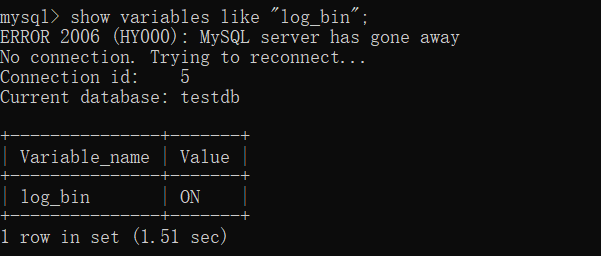
ON is the ON state.
Check the status of pump and drainer:
show pump status;

show drainer status;

The status is online.
3, SpringBoot message listening client
Download the official demo
https://github.com/pingcap/tidb-tools/tree/master/tidb-binlog/driver/example/kafkaReader
The official demo is the Java Kafka Api directly used. In this article, we use spring Kafka of SpringBoot.
After downloading, you need to copy three files to your SpringBoot project:
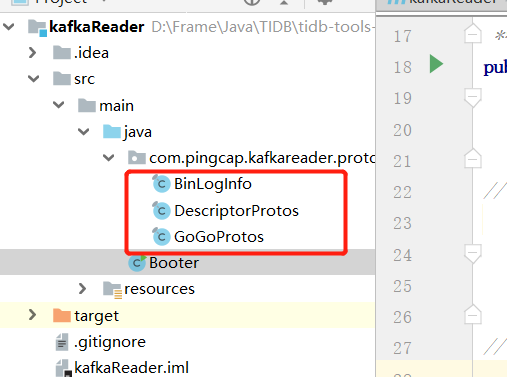
These three tools need to be used to parse the data, otherwise the parsed code is garbled. You can go to Tidb's community to see this:
The main dependencies introduced by POM files are:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/com.google.protobuf/protobuf-java -->
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.9.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.google.protobuf/protobuf-java-util -->
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java-util</artifactId>
<version>3.9.1</version>
</dependency>
application configuration information:
server:
port: 8080
spring:
kafka:
# kafka server address (multiple)
# bootstrap-servers: 192.168.159.128:9092,192.168.159.129:9092,192.168.159.130:9092
bootstrap-servers: 192.168.40.1:9092
consumer:
# Specify a default group name
group-id: kafkaGroup
# Earlist: when there are submitted offsets under each partition, consumption starts from the submitted offset; When there is no committed offset, consumption starts from scratch
# latest: when there are submitted offsets under each partition, consumption starts from the submitted offset; When there is no committed offset, the newly generated data under the partition is consumed
# none:topic when there are committed offsets in each partition, consumption starts after offset; As long as there is no committed offset in one partition, an exception is thrown
auto-offset-reset: earliest
# Deserialization of key/value
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.ByteArrayDeserializer
producer:
# Serialization of key/value
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# Batch fetching
batch-size: 65536
# Cache capacity
buffer-memory: 524288
#Failed retries
retries: 3
# server address
# bootstrap-servers: 192.168.159.128:9092,192.168.159.129:9092,192.168.159.130:9092
Note that ByteArrayDeserializer is used for consumer.value-deserializer. The main sender is byte []. We can only cooperate with:
Log listening:
@KafkaListener(topics = "tidb-test")
public void receive3(ConsumerRecord<String, byte[]> consumer) throws Exception {
System.out.println("tidb bing-log Listener >> ");
//binglog object
BinLogInfo.Binlog binlog = BinLogInfo.Binlog.parseFrom(consumer.value());
//Operation type 0 DML 1 DDL
BinLogInfo.BinlogType type = binlog.getType();
log.info(binlog.toString());
log.info("Operation type:{} ", type);
//Parsing content
if (BinLogInfo.BinlogType.DML == type) {
BinLogInfo.DMLData dmlData = binlog.getDmlData();
if (dmlData.getTablesCount() == 0) {
return;
}
dmlData.getTablesList().forEach(table -> {
String db = table.getSchemaName();
log.info("Update database:{}", db);
String tableName = table.getTableName();
log.info("Update data table:{}", tableName);
List<BinLogInfo.ColumnInfo> columnInfoList = table.getColumnInfoList();
List<BinLogInfo.TableMutation> MutationsList = table.getMutationsList();
MutationsList.forEach(mutation -> {
BinLogInfo.MutationType mutationType = mutation.getType();
log.info("Operation type:{}", mutationType);
List<BinLogInfo.Column> columnsList = mutation.getRow().getColumnsList();
//Parse updated data
for (int i = 0; i < columnInfoList.size(); i++) {
String stringValue = columnsList.get(i).getStringValue();
if (!StringUtils.isEmpty(stringValue)){
String filedName = columnInfoList.get(i).getName();
log.info("Update fields:{} ,Updated value:{} ", filedName, stringValue);
}
}
});
});
} else if (BinLogInfo.BinlogType.DDL == type) {
} else {
throw new Exception("analysis binglog err!");
}
}
4, Testing
Test table structure:
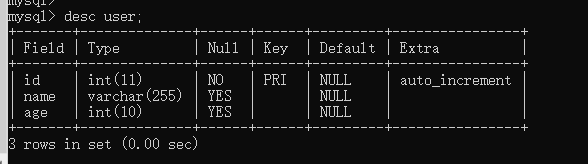
Add data:
insert into user(name,age) values('bxc',10);
toString information:
type: DML
commit_ts: 429572910085570562
dml_data {
tables {
schema_name: "testdb"
table_name: "user"
column_info {
name: "id"
mysql_type: "int"
is_primary_key: true
}
column_info {
name: "name"
mysql_type: "varchar"
is_primary_key: false
}
column_info {
name: "age"
mysql_type: "int"
is_primary_key: false
}
mutations {
type: Insert
row {
columns {
int64_value: 212247
}
columns {
string_value: "bxc"
}
columns {
int64_value: 10
}
}
}
5: {
1: "PRIMARY"
2: "id"
}
}
}
Parse print information:

Update data:
update user set age = 20 where name = 'bxc';

Delete data:
delete from user where name = 'bxc';

Create a new table:
CREATE TABLE `user2` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `age` int(10) DEFAULT NULL, PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */ ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin AUTO_INCREMENT=242214;