Today, I'd like to share with you my new skills of get recently. I use single thread, multi thread and collaborative process to crawl and download the small video of pear video. Without much talk, we begin to boom. Duck, duck!
target
Download and save the technology related video resources on the pear video to the local computer
tool
- Python3.9
- Pycharm2020
Third party libraries needed
1) requests # send requests 2) parsel # parses data (supports re, xpath, css) 3) fake_useragent # build request header 4) random # generates random numbers 5) os # operation path / build folder 6) json # processing json data 7) concurrent # processing thread pool 8) asyncio, aiohttp, aiofiles # processing procedures
Analyze and download videos using a single thread
We need to download the video resources on the pear video website to the local computer. The two essential elements must be the video name and the video resource url. After obtaining the url of the video resource, send a request for the url of the video resource, get the response, and then save the response content to the local computer in the name of the video name.
Start page: technology hot information short video_ Science and technology hot news - Pear Video official website - Pear Video URL address: https://www.pearvideo.com/category_ eight
1. Analysis start page
F12 refresh the start page to capture packets and get the data request interface
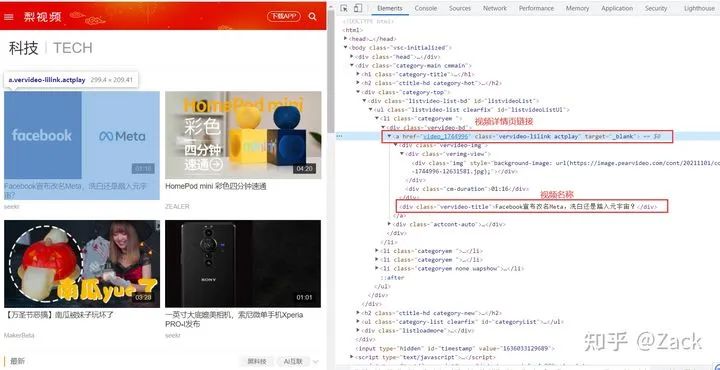
Pear video (Technology) home page
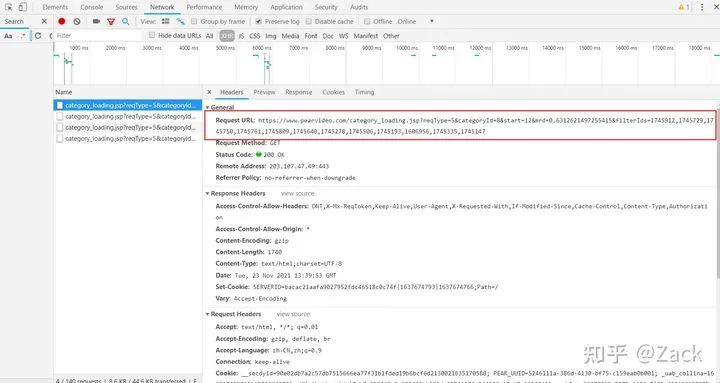
Compare and observe the url obtained from packet capturing:
- https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=12&mrd=0.6312621497255415&filterIds=1745912,1745729,1745750,1745761,1745809,1745640,1745278,1745506,1745193,1606956,1745335,1745147
- https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=24&mrd=0.9021185727219558&filterIds=1745912,1745729,1745750,1745254,1745034,1744996,1744970,1744646,1744743,1744838,1744567,1744308,1744225,1744727,1744649
- https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=36&mrd=0.6598737970838424&filterIds=1745912,1745729,1745750,1744642,1744353,1744377,1744291,1744127,1744055,1744106,1744126,1744040,1743939,1743997,1744012
Comparing the above three URLs, we can see that the rest are different except for start, mrd and filterIds https://www.pearvideo.com/category_ loading.jsp?reqType=5&categoryId=8&start=. The start is increased to 12 each time, that is, 12 videos are loaded each time; mrd is a random number, and filterIds is the cid number of video resources.
2. Send start page request
We can build the request and obtain the response content according to the information obtained from the packet capture. The full text will imitate the writing method of the sketch framework, encapsulate the code in a class, and then define different functions to realize the functions of each stage.
# Import required modules import requests from parsel import Selector from fake_useragent import UserAgent import random import json import os
Create classes and define related functions and properties
class PearVideo:
def __init__(self, page):
self.headers = {
"User-Agent": UserAgent().chrome, # Build Google request header
}
self.page = page # Sets the number of pages to crawl
self.base_url = "https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start="
def start_request(self):
for page in range(self.page):
start_url = self.base_url + str(page * 12) # Splice start page url
res = requests.get(start_url, headers=self.headers)
if res.status_code == 200:
# Convert the obtained request into a parsel.selector.Selector object, and then it is convenient to parse the text;
# Similar to the response object in the scratch framework, you can directly call the re(), xpath() and css() methods.
selector = Selector(res.text)
self.parse(selector)
After obtaining the response, we can parse the response text. In the response text, we can extract the url of the video details page and the video name. The code is as follows:
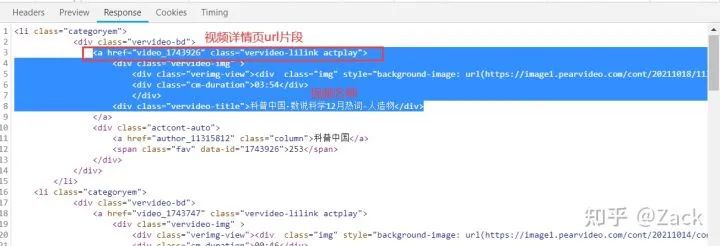
3. Parse the start page response to obtain the video name and video details page url
def parse(self, response):
videos = response.xpath("//div[@class='vervideo-bd']")
for video in videos:
# Splicing video details page url
detail_url = "https://www.pearvideo.com/" + video.xpath("./a/@href").get()
# Extract video name
video_name = video.xpath(".//div[@class='vervideo-title']/text()").get()
# Pass the video details page url and video name to parse_ The detail method sends a request to the detail page to get a response.
self.parse_detail(detail_url, video_name)
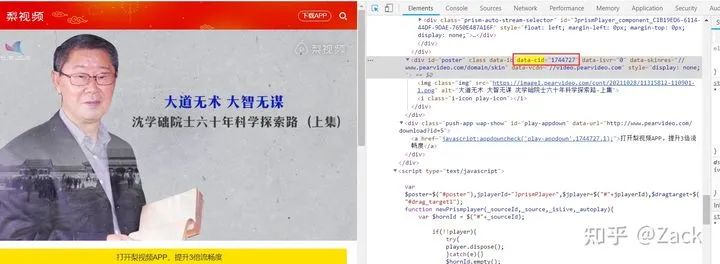
Open the video details page in the browser and press F12 to observe the url of the visible video resource of the code rendered by the browser, as shown in the following figure:
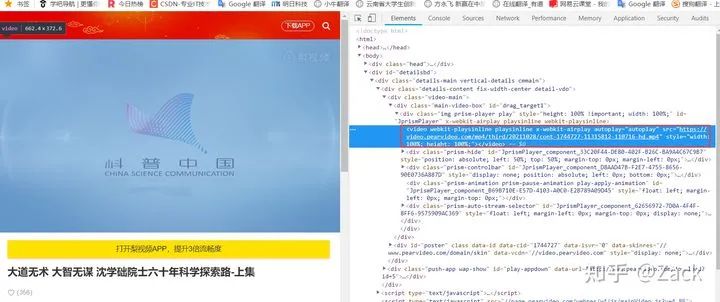
The video resource url here is: https://video.pearvideo.com/mp4/third/20211028/cont-1744727-11315812-110716-hd.mp4
However, after actually obtaining the response of the video details page, the url of the video resource is not found, and only the url of a video picture preview can be found, as shown in the following figure (you can obtain it by right clicking the web page source code on the browser video details page):

Therefore, we capture the video details page again and find the relevant request and response contents of the video resource url, as shown in the following figure:
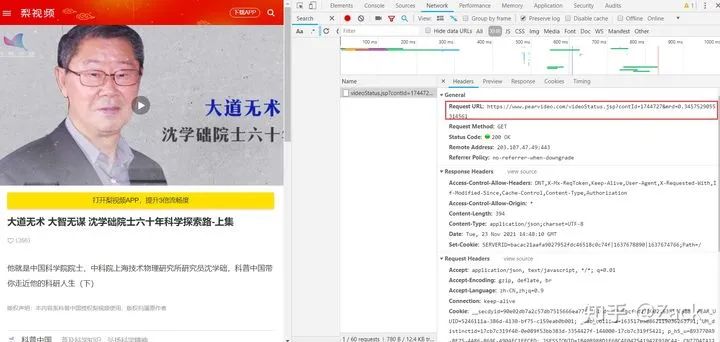
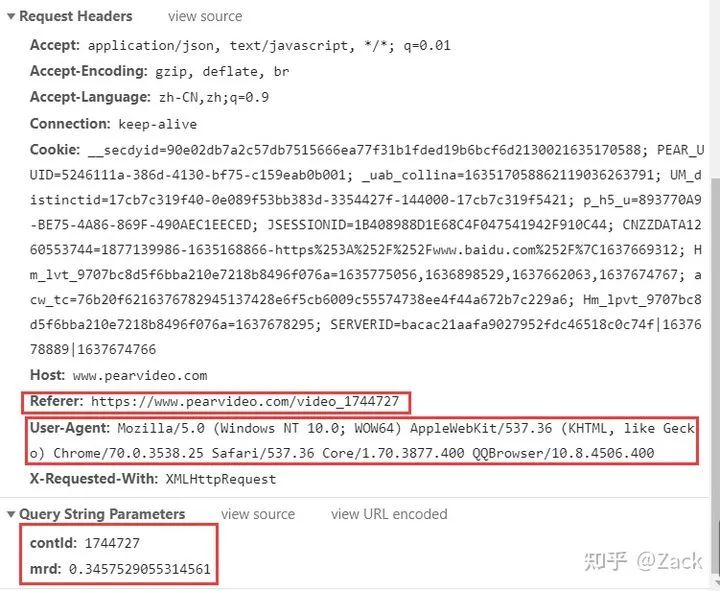
The contId is the data CID attribute value of the detail page response (see below), while mrd is a random value, which can be generated through random.random(). Referer s are essential when sending requests, otherwise correct response contents will not be obtained.
Click preview to view the response result of the request, as shown in the following figure:
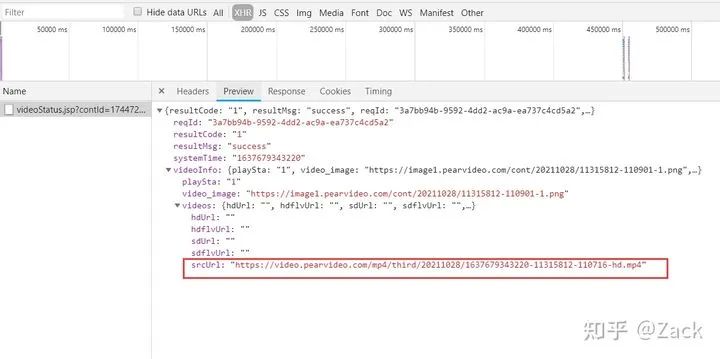
In the figure, we can get an srcUrl link with the suffix mp4, which looks like the video resource url we need. However, if we directly use this link to send the request, the following error will be prompted:
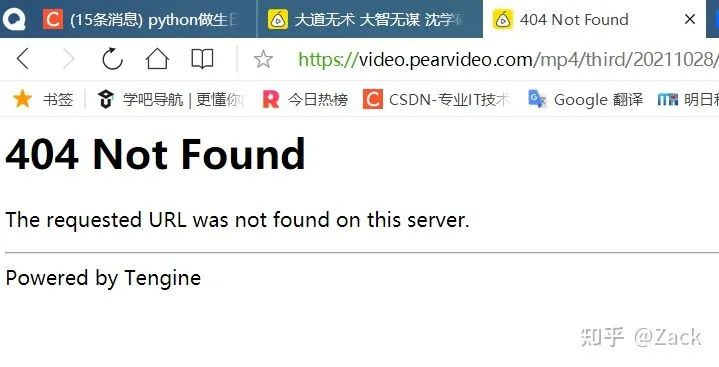
Compare and observe the video resource url after browser rendering and the video resource url obtained by packet capturing:
Browser rendering: https://video.pearvideo.com/mp4/third/20211028/cont-1744727-11315812-110716-hd.mp4 Packet capture: https://video.pearvideo.com/mp4/third/20211028/1637679343220-11315812-110716-hd.mp4
It can be seen from the observation that the other parts are the same except the parts marked with black and thick above; 1744727 is the data CID attribute value of the video resource.
Browser video details page
Therefore, we can replace 16379343220 in the fake video resource url obtained by packet capture with cont-1744727 (i.e. video data CID attribute value), so as to obtain the real video resource url and download the video resource!
After a long analysis, you can finally write the code by hand!
4. Send a request for the url of the video details page to get a response
def parse_detail(self, detail_url, video_name):
detail_res = requests.get(detail_url, headers=self.headers)
detail_selector = Selector(detail_res.text)
init_cid = detail_selector.xpath("//Div [@ id ='poster '] / @ data CID "). Get() # extract the attribute value of data CID in the web page (initial cid)
mrd = random.random() # Generate random numbers and build mrd
ajax_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={init_cid}&mrd={mrd}"
global ajax_header # Set ajax_header to global variable so that it can be invoked in subsequent functions.
ajax_header = {"Referer": f"https://www.pearvideo.com/video_{init_cid}"}
self.parse_ajax(ajax_url, init_cid, video_name)
5. Capture the video details page and obtain the fake video resource url
def parse_ajax(self, ajax_url, init_cid, video_name):
ajax_res = requests.get(ajax_url, headers=ajax_header)
fake_video_url = json.loads(ajax_res.text)["videoInfo"]["videos"]["srcUrl"] # Get fake video resource url
fake_cid = fake_video_url.split("/")[-1].split("-")[0] # Extract fake cid from fake video resource url
real_cid = "cont-" + init_cid # The true cid is equal to cont plus the initial cid
# Replace the fake cid(fake_cid) in the fake video resource url with the real cid(real_cid) to get the real video resource url!!!
# This code, your product, your fine product
real_video_url = fake_video_url.replace(fake_cid, real_cid)
self.download_video(video_name, real_video_url)
6. Send a request to the video resource url and get a response
With the video name and video resource url, you can download the video!!!
def download_video(self, video_name, video_url):
video_res = requests.get(video_url, headers=ajax_header)
video_path = os.path.join(os.getcwd(), "Single threaded video download")
# If it does not exist, create a video folder to store videos
if not os.path.exists(video_path):
os.mkdir(video_path)
with open(f"{video_path}/{video_name}.mp4", "wb") as video_file:
video_file.write(video_res.content)
print(f"{video_name}Download complete")
Finally, define a run() method as the entry of the whole class, and call the first start_request() function! (dolls, one function sets another function)
def run(self):
self.start_request()
if __name__ == '__main__':
pear_video = PearVideo(3) # First get its three page video resources
pear_video.run()
Download video using thread pool
The overall code of thread pool is similar to that of single thread, except that the video name and video resource url are extracted separately as global variables. The part of obtaining video name and video resource url is still single thread. Thread pool processing is only used in the part of downloading video resources. You can send requests and obtain responses for multiple video resource URLs at the same time.
The main codes are as follows:
class PearVideo:
def __init__(self, page):
self.headers = {
"User-Agent": UserAgent().chrome,
}
self.page = page
self.base_url = "https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start="
self.video_list = [] # video_list is added as a global variable to save the video name and video resource url
1. Get the real video resource url code
def parse_ajax(self, ajax_url, init_cid, video_name):
ajax_res = requests.get(ajax_url, headers=ajax_header)
fake_video_url = json.loads(ajax_res.text)["videoInfo"]["videos"]["srcUrl"]
fake_cid = fake_video_url.split("/")[-1].split("-")[0]
real_cid = "cont-" + init_cid
real_video_url = fake_video_url.replace(fake_cid, real_cid)
# video_dict is refreshed every time it is requested and finally saved in the video_list
video_dict = {
"video_url": real_video_url,
"video_name": video_name
}
self.video_list.append(video_dict)
2. Multi thread download video resource code
def download_video(self, video_dict): # What is passed here is a dictionary, not a video_list
video_res = requests.get(video_dict["video_url"], headers=ajax_header)
video_path = os.path.join(os.getcwd(), "Thread pool video download")
if not os.path.exists(video_path):
os.mkdir(video_path)
with open(f"{video_path}/{video_dict['video_name']}.mp4", "wb") as video_file:
video_file.write(video_res.content)
print(f"{video_dict['video_name']}Download complete")
3. Start multithreading
if __name__ == '__main__':
pear_video = PearVideo(2)
pear_video.run()
pool = ThreadPoolExecutor(4) # 4 here means that only 4 threads are started to download video resources at a time
# The map method here has a similar meaning to Python's own map(x,y), that is, each element in the iteratable object y executes the function X.
pool.map(pear_video.download_video, pear_video.video_list)
Download video using coprocess
The three most important libraries for downloading video resources using collaboration are asyncio (creating collaboration objects), aiohttp (sending asynchronous requests), and aiofiles (saving files asynchronously).
a key:
1) Add the async keyword before the function, and the function is created as a coroutine object; 2) All parts of the collaboration object that need io time-consuming operations need to use await to suspend the task; 3) The collaboration object cannot be run directly. You need to create an event loop (similar to an infinite loop) and then run the collaboration object.
be careful:
1) You cannot use requests to send asynchronous requests. You need to use AIO HTTP or httpx; 2) You can't directly use open() to save files. You need to use aiofiles to save files asynchronously.
The main codes are as follows
# Take the video resource url and video name as global variables
self.video_urls = []
self.video_names = []
1. Define the collaboration object and download the video
# Download video information
async def download_videos(self, session, video_url, video_name, video_path):
# Send asynchronous request
async with session.get(video_url, headers=ajax_header) as res:
# To obtain an asynchronous response, await must be preceded to indicate suspension
content = await res.content.read()
# Asynchronously save video resources to local computer
async with aiofiles.open(f"{video_path}/{video_name}.mp4", "wb") as file:
print(video_name + " Download complete...")
await file.write(content)
2. Create the main() running collaboration object
async def main(self):
video_path = os.path.join(os.getcwd(), "Collaborative video download")
if not os.path.exists(video_path):
os.mkdir(video_path)
async with aiohttp.ClientSession() as session: # Create a session and maintain the session
# Create a collaboration task, and each video resource url is a collaboration task
tasks = [
asyncio.create_task(self.download_videos(session, url, name, video_path))
for url, name in zip(self.video_urls, self.video_names)
]
# Wait for all tasks to complete
done, pending = await asyncio.wait(tasks)
3. Call the whole class and run the coroutine object
if __name__ == '__main__':
pear_video = PearVideo(3)
pear_video.run()
loop = asyncio.get_event_loop() # Create event loop
loop.run_until_complete(pear_video.main()) # Run collaboration objectsupplement
When saving a video, if the video name contains illegal characters such as "\", "/", "*", "?", "<", ">", "|", the video will not be saved, and the program will report an error. You can filter the video name with the following code:
def rename(self, name):
stop = ["\\", "/", "*", "?", "<", ">", "|"]
new_name = ""
for i in name:
if i not in stop:
new_name += i
return new_name
In the code of downloading video resources using multithreading and collaboration, the combination of single thread and thread pool / collaboration is used. After obtaining the video name and video resource url, the request is sent for the video resource and the response is obtained. This part of the code still needs to be optimized. For example, the Producer / consumer mode is used to produce the video resource url and download the video according to the url; The collaborative part can also modify other parts that need to send network requests to the collaborative mode, so as to improve the download speed.
summary
The difficulty of downloading pear video video resources is to crack the real video resource url. You need to send a request to the video start page (home page), then send a request to the video detail page, then grab the packet on the video detail page to obtain the real video resource url, and finally send a request to the video resource url to download the video resources. The part of thread pool and co process still needs to be optimized in order to better improve the download efficiency.