These two days, I looked at three common parsing libraries used by python, wrote an essay and tidied up my thoughts. It's very delicious. If there are any mistakes, you are welcome to correct them at any time. (conme on....)
Crawling web data usually goes through three steps: obtaining information - > extracting information - > saving information. The use of parsing libraries can help us quickly extract the part of information we need and avoid the trouble of writing complex regular expressions. When using parsing libraries, personal understanding also has three steps: building a document tree - > searching a document tree - > obtaining attributes and text.
Establishment of document tree: that is to use parsing library to parse the source code of web pages we get. Only in this way can we use the parsing library method later.
Search Document Tree: In the established document tree, we use the attribute of the tag to search out the information we need, such as a div tag containing part of the content of the web page, an ul tag, etc.
Getting properties and text: On the basis of the previous step, we can further get the text or attributes of a specific tag, such as href attribute of a tag, title attribute, or its text.
First, define an html string to simulate the source code of the web page that has been acquired
html = ''' <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> '''
0x01: XPath parsing library: XPath, full name XML Path Language, that is, XML Path Language, it is a language to find information in XML documents. It was originally used to search for XML documents, but it is also suitable for HTML documents.
1. Establishing a document tree: After obtaining the source code of a web page, you can build a complex HTML into a document tree by using the HTML method of etree.
from lxml import etree xpath_tree = etree.HTML(html)
First import the etree module of the lxml library, then declare a piece of HTML text, call the HTML class to initialize, so we successfully construct an XPath parsing object. You can use type to see the type of xpath_tree, which is < class'lxml. etree. _Element'>.
2. Searching the Document Tree: First look at some common rules of xpath
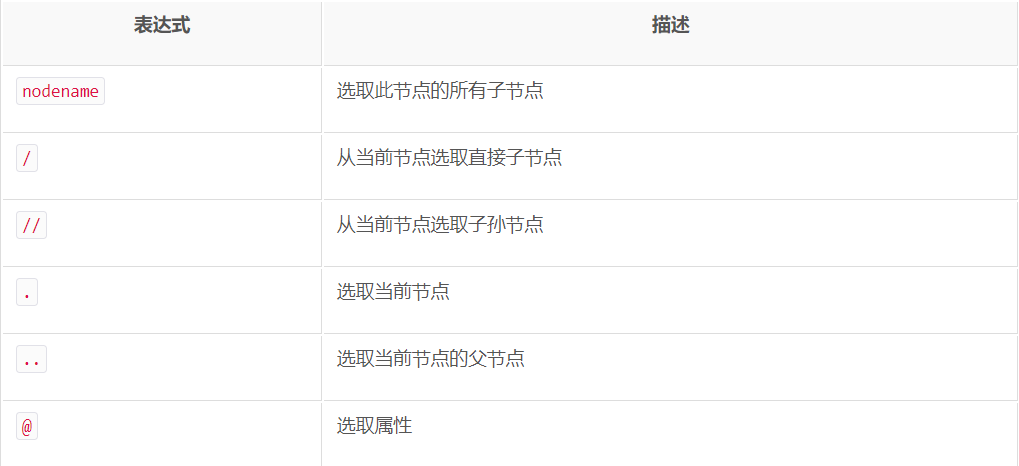
(1) Search tags from the entire document tree: Generally, all eligible nodes are selected with the // beginning XPath rule. Here's an example of the HTML text above. For example, search ul Tags
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('ul') 3 print(result) 4 print(type(result)) 5 print(type(result[0]))
The output results are as follows:
[<Element ul at 0x2322b7e8608>, <Element ul at 0x2322b7e8648>]
<class 'list'>
<class 'lxml.etree._Element'>
The second line above shows that all ul tags are searched out from the entire document tree. You can see that the result is a list with each element of the lxml.etree._Element type. Of course, you can also traverse the list and then operate on each lxml.etree._Element object.
(2) Search for the child nodes of the current node: for example, find the li tag in each ul tag:
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('//ul') 3 for r in result: 4 li_list = r.xpath('./li') 5 print(li_list)
The output results are as follows:
[<Element li at 0x23433127748>, <Element li at 0x23433127788>, <Element li at 0x23433127a88>, <Element li at 0x23433127988>, <Element li at 0x23433127ac8>]
[<Element li at 0x23433127cc8>, <Element li at 0x23433127d08>, <Element li at 0x23433127d48>, <Element li at 0x23433127d88>, <Element li at 0x23433127dc8>]
The fourth line of code indicates that the current ul tag is selected and all li tags in it are retrieved.
(3) filtering by attributes: If you need to filter by attributes of tags, you can do so.
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('//ul') 3 for r in result: 4 li_list = r.xpath('./li[@class="item-0"]') 5 print(li_list)
The output results are as follows:
[<Element li at 0x15c436695c8>, <Element li at 0x15c436698c8>]
[<Element li at 0x15c43669988>, <Element li at 0x15c436699c8>]
Compared with the previous code, the purpose is to add [@class="item-0"] after the fourth line, which means to find all the li tags with the class attribute value of item-0 under the current ul tag. Of course, when searching for a tag in the whole document tree, it can also add an attribute after the tag to filter, which is useful in the following example.
(4) Getting Text: Getting Text Content of a Specific Label
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('//ul[@class="list"]') 3 for r in result: 4 li_list = r.xpath('./li[@class="item-0"]') 5 for li in li_list: 6 print(li.xpath('./text()'))
The output results are as follows:
['first item']
[]
['first item']
[]
First, attribute filtering is added after the ul tag in the second line, but because the class attribute values of both ul tags are list, the results are the same as before. Then a for loop is added to get the text of each element in the list, because the second li tag has no text content, so it is empty.
(5) Getting attributes: Getting the content of an attribute for a specific tag
1 xpath_tree = etree.HTML(html) 2 result = xpath_tree.xpath('//ul[@class="list"]') 3 for r in result: 4 li_list = r.xpath('./li[@class="item-0"]') 5 for li in li_list: 6 print(li.xpath('./@class'))
The output results are as follows:
['item-0']
['item-0']
['item-0']
['item-0']
Replace the text() method of the sixth line with the @ symbol, and add the desired attribute after it, and get the attribute value of the attribute.
This is the basic use of xpath parsing library, but there are also some things that have not been mentioned, you can see the quiet big man's article.
https://cuiqingcai.com/5545.html
*********************************** does not accumulate any steps, not even thousands of miles. *******************************************************