introduction
Children's shoes familiar with concurrency know that concurrent programming has three characteristics: visibility, orderliness and atomicity. Today, we analyze visibility from a demo and how to ensure visibility.
JMM model
Before we analyze visibility, we need to understand the concept of JMM model, which is often referred to as java memory model .
The JAVA memory model is defined in the Java virtual machine specification, which is used to shield the memory access differences of various hardware and operating systems, so as to achieve the consistent concurrent effect of programs on various platforms. JMM specifies how the Java virtual machine and computer memory work together. It specifies how and when a thread can see the value of the shared variable modified by other threads, and how to access the shared variable synchronously when necessary. JMM describes an abstract concept, a set of rules, which controls the access mode of each variable in the program in the shared data area and private data area.

Upper code
package com.tuling.juc.service;
import com.tuling.concurrent.lock.UnsafeInstance;
import com.tuling.juc.Factory.UnsafeFactory;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.LockSupport;
/**
* @Description
* @Author zhenghao
* @Date 2021/10/28 18:26
**/
public class VisibilityTest {
//volatile realizes visibility through memory barrier. The assembly level will add the lock keyword in front of the executed instructions
//The lock keyword can act as a memory barrier, but not a memory barrier
//The lock prefix instruction will wait for all instructions before it to complete, and all buffered writes will be written to memory
private volatile boolean flag = true;
private int count = 0;
public void refresh() {
flag = false;
System.out.println(Thread.currentThread().getName() + "modify flag");
}
public void load() {
System.out.println(Thread.currentThread().getName() + "Start execution.....");
int i = 0;
while (flag) {
i++;
count++;
//TODO business logic
//When waiting long enough, the variable value in local memory will be actively refreshed to main memory
//Without this code, the program will not be interrupted because when true is the computer task flag
//Variables are used at any time, so they are not flushed to main memory
//shortWait(1000000);
//How to solve the problem of visibility in the following way? Thread context switch load context
// Thread.yield();// Make the current thread change from running state to thread state, giving up CPU occupation time
//Visibility through memory barriers
// UnsafeFactory.getUnsafe().storeFence();
// The bottom layer uses the synchronized keyword, and finally calls the storeFence method
//Visibility through memory barriers
// System.out.println(count);
// LockSupport.unpark( Thread.currentThread());
//
// try {
// Thread.sleep(1000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
//There are two ways to ensure visibility in java
// 1. Memory barrier the storeLoad memory barrier on the jvm level = = = > x86 lock replaces mfence
// 2. Thread context switch Thread.yield();
}
System.out.println(Thread.currentThread().getName() + "Jump out of loop: i=" + i);
}
public static void shortWait(long interval) {
long start = System.nanoTime();
long end;
do {
end = System.nanoTime();
} while (start + interval >= end);
}
public static void main(String[] args) throws Exception {
VisibilityTest visibilityTest = new VisibilityTest();
Thread threadA = new Thread(() -> visibilityTest.load(), "ThreadA");
threadA.start();
Thread.sleep(1000);
Thread threadB = new Thread(() -> visibilityTest.refresh(), "ThreadB");
threadB.start();
}
}
1, What is the result of running the above code?
The result from the writing of the code is that after running for A period of time, the program will end while Loop, and print out: jump out of loop. But when we actually run the above As A result, the program will directly enter the dead cycle and will not end. This is what we often call the visibility of shared variables. Thread A cannot perceive the modification of flag by thread B. If such code appears in the actual business, it will lead to serious bug s.
In the JMM model, we know that this is because when the thread is running, the flag variables are loaded into the local memory of their respective threads, and the communication between the two threads is through the main memory. Therefore, if we want thread B to modify the value of the variable and let thread A perceive it in time, we need thread B to refresh the modification of the variable to the main memory in time, And the cache of this variable in the local memory of other threads is invalid.
2, Solution
two point one wait for
We speculate from common sense that if our program does not use this flag variable in a short time, theoretically, the computer will remove the variable from the cache regularly. After all, the local memory space of each thread is not very large, and it is probably the same principle to analyze from some common memory cleaning middleware, so we add it in the whil loop Wait for 1ms and run the result: the program jumps out of while Loop to achieve the purpose of visibility, which also indicates that the computer will clear the recently unused variables from the local memory. How long it will take to achieve this effect depends on the specific hardware. There is no specific and accurate time.
two point two Thread context switching
The typical usage of this clock method is Thread.yield(), which changes the current thread from running state to ready state and gives up CPU usage rights. The basic thread switching time is about 5ms-10ms. The thread context switching will cause the local memory of the current thread to fail. When the thread obtains the CPU usage right again, it obtains the next executed instruction from the program counter and loads the variable value from the main memory. This method is also solved Visibility issues.
2.3 volatile keyword
This method is our most common solution, so why can volatile keyword solve this problem? Because this is a keyword in the jdk, we need to check the jdk source code for a better understanding
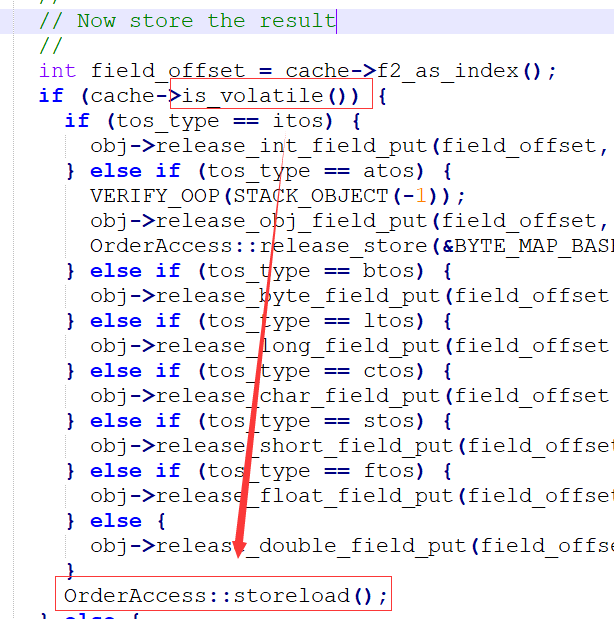
From the source code, we can find that this keyword calls the storeload() method. From this method, we can know that the implementation of the memory barrier is called here.
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::fence() {
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}The above code is implemented on x86 processor. In this process, lock is used to achieve the effect similar to memory barrier, which is more efficient.
Function of lock prefix instruction
1. Ensure the atomicity of subsequent instruction execution. In Pentium and previous processors, instructions with lock prefix will lock the bus during execution, so that other processors cannot access memory through the bus temporarily. Obviously, this overhead is very large. In the new processor, Intel uses cache locking to ensure the atomicity of instruction execution. Cache locking will greatly reduce the execution overhead of lock prefix instructions.
2. The lock prefix instruction has a function similar to the memory barrier, which prevents the instruction from reordering with the previous and subsequent read-write instructions.
3. The lock prefix instruction will wait until all instructions before it are completed and all buffered writes are written back to memory (that is, the contents of the store buffer are written to memory). According to the cache consistency protocol, refreshing the store buffer will cause the copies in other caches to become invalid.
lock implementation at assembly level
We can observe this by adding jvm parameters
-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp

It is verified that the visibility is used for the lock instruction
Other ways System.out.println(count); The bottom layer uses the synchronized keyword, and the source code finally calls the storeFence method, which also uses the memory barrier to achieve visibility. Including Thead.sleep()
two point four count Type from int Replace with integer
This method actually uses the final keyword, if we have seen intege If the source code is defined, we actually get the value in the end, and in integer, the value It is defined through the final keyword, so the final keyword can also solve the visibility problem.
summary
So we will summarize the above solutions,
How to ensure visibility
- adopt volatile keyword ensures visibility.
- adopt Memory barriers ensure visibility.
- adopt The synchronized keyword guarantees visibility.
- adopt Lock ensures visibility.
- adopt The final keyword guarantees visibility
In fact, the above methods can be divided into two major schemes from the bottom;
1) Thread context switching
2) Memory barrier The storeLoad memory barrier at the jvm level = = = > x86 lock replaces mfence