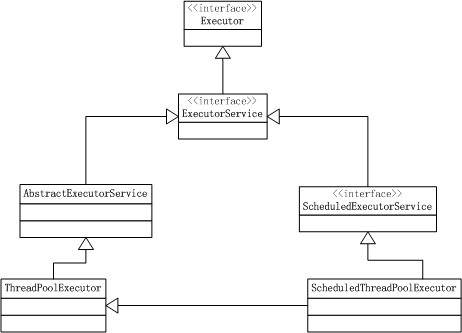
The diagram of the main classes of the Executor interface in the concurrent package is as follows:
Executor
Executor interface is very simple, that is, to execute a Runnable command.
public interface Executor {
void execute(Runnable command);
}ExecutorService
The ExecutorService interface extends the Executor interface, adds state control, and performs multiple tasks back to Future.
On the method of state control:
// Send a shutdown signal, and do not wait until the existing task is completed, but the existing task will continue to execute, you can call awaitTermination to wait for all tasks to execute. No longer accept new tasks.
void shutdown();
// Close immediately, try to cancel the task being executed (there is no guarantee that it will be cancelled successfully), and return to the task that has not been executed.
List<Runnable> shutdownNow();
// Whether to send off signal
boolean isShutdown();
// Whether all tasks are completed after shutdown, that is, shutdown cannot return true without calling shutdownNow or shutdown
boolean isTerminated();
// Wait until all tasks are completed or timed out
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;Submit a single task and immediately return the real-time status of the execution of a Future storage task
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);There are two ways to perform multiple tasks, one is to wait until all tasks are completed before returning:
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException; <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit) throws InterruptedException;
Another is to wait until one task is completed, cancel other unfinished tasks, and return to the results of execution of completed tasks:
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;From the above code, you can see that ExecutorService can perform two types of tasks: Runnable and Callable, and Callable uses more. The difference between the two is simple: the former does not return an execution result, while the latter returns an execution result:
public interface Callable<V> {
V call() throws Exception;
}Next comes Future, which is the return type of the task. Future can be seen as an invoice. For example, if you send a laundry to the laundry, they will issue you an invoice, you can take the invoice to get back your laundry or go to the laundry to ask if the laundry is ready, and so on.
public interface Future<V> {
//Cancel the task. When the parameter mayInterruptIfRunning is true, if the cancelled task is executing, the thread executing the task will be set to interrupt. When false, the task being executed will be allowed to complete.
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
//Gets the execution result, and if the task is executing, it will wait until the task is completed before returning.
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}ScheduledExecutorService
Scheduled ExecutorService, which is a sub-interface of ExecutorService, adds the function of executing tasks on time:
public interface ScheduledExecutorService extends ExecutorService {
public ScheduledFuture<?> schedule(Runnable command,
long delay, TimeUnit unit);
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay, TimeUnit unit);
// Wait for a certain amount of time and then start executing a task, every time the period parameter is set
// Repeat (multithreaded execution)
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
// Wait for a certain amount of time and then start a task. When it's done, wait for the time when the delay parameter is set.
// Then perform a task. (Single thread execution)
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit);
}AbstractExecutorService
AbstractExecutorService provides a default implementation of ExecutorService's method of executing task types. These methods include submit, invokeAny and InvokeAll.
Note that the execute method from the Executor interface is not implemented. The execute method is the core of the whole system. All tasks are really executed in this method, so different implementations of this method will bring different execution strategies. This can be seen in a later analysis of ThreadPool Executor and Scheduled ThreadPool Executor.
First, let's look at the submit method, whose basic logic is as follows:
Generate an object of the wrapper interface RunnableFuture for the task type and the Future interface
Perform tasks
Return to future.
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}Because submit supports two types of tasks, Callable and Runnable, the newTaskFor method has two overloading methods:
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}It has been said that the difference between Callable and Runnable is that the former carries a return value, that is to say, Callable=Runnable + return value. Therefore, an adapter is provided in java to convert the Runnable + return value into the Callable type. This can be seen in the code of the FutureTask type constructor in the new Task For:
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
sync = new Sync(callable);
}
public FutureTask(Runnable runnable, V result) {
sync = new Sync(Executors.callable(runnable, result));
}The following is the code for the Executors.callable method:
public static <T> Callable<T> callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter<T>(task, result);
}The code of Runnable Adapter is well understood. It is an implementation of Callable. The implementation of call method is to execute Runnable's run method and return that value.
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}Let's start with the simpler invokeAll:
Call the newTaskFor method for each task to generate a List of wrapper class objects that are both Task and Future
Loop call execute to perform each task
Call the get method of each Future again and wait for each task to complete
Finally, return to Future's list.
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit) throws InterruptedException {
if (tasks == null || unit == null)
throw new NullPointerException();
long nanos = unit.toNanos(timeout);
List<Future<T>> futures = new ArrayList<Future<T>>(tasks.size());
boolean done = false;
try {
// Generate wrapper objects for each task
for (Callable<T> t : tasks)
futures.add(newTaskFor(t));
long lastTime = System.nanoTime();
// Loop call execute to execute each method
// Here, because the timeout time is set, after each execution is completed
// Check whether the timeout occurs, and the timeout returns directly to the future collection
Iterator<Future<T>> it = futures.iterator();
while (it.hasNext()) {
execute((Runnable)(it.next()));
long now = System.nanoTime();
nanos -= now - lastTime;
lastTime = now;
if (nanos <= 0)
return futures;
}
// Waiting for each task to complete
for (Future<T> f : futures) {
if (!f.isDone()) {
if (nanos <= 0)
return futures;
try {
f.get(nanos, TimeUnit.NANOSECONDS);
} catch (CancellationException ignore) {
} catch (ExecutionException ignore) {
} catch (TimeoutException toe) {
return futures;
}
long now = System.nanoTime();
nanos -= now - lastTime;
lastTime = now;
}
}
done = true;
return futures;
} finally {
if (!done)
for (Future<T> f : futures)
f.cancel(true);
}
}The difficulty of invokeAny is that it returns whenever a task succeeds and cancels other tasks, that is to say, it focuses on finding the first successful task.
Here I think of BlockingQueue. When all tasks are submitted, the Future s returned from task execution are added to a BlockingQueue in turn. Then I find that the first way to perform a successful task is to extract the first element from BlockingQueue, which is the basic principle of ExecutorCompletion Service used by the doInvokeAny method.
Because both invokeAny methods call the doInvokeAny method, the following is the code analysis of doInvokeAny:
private <T> T doInvokeAny(Collection<? extends Callable<T>> tasks,
boolean timed, long nanos)
throws InterruptedException, ExecutionException, TimeoutException {
if (tasks == null)
throw new NullPointerException();
int ntasks = tasks.size();
if (ntasks == 0)
throw new IllegalArgumentException();
List<Future<T>> futures= new ArrayList<Future<T>>(ntasks);
// Executor Completion Service is responsible for executing tasks, and later calls return the first execution result with poll
ExecutorCompletionService<T> ecs =
new ExecutorCompletionService<T>(this);
// For efficiency reasons, after each submission of a task, check to see if it has been completed.
try {
ExecutionException ee = null;
long lastTime = timed ? System.nanoTime() : 0;
Iterator<? extends Callable<T>> it = tasks.iterator();
// Submit a task first
futures.add(ecs.submit(it.next()));
--ntasks;
int active = 1;
for (;;) {
// Try to get an execution result (which returns immediately)
Future<T> f = ecs.poll();
// No execution results
if (f == null) {
// If there are still tasks that have not been submitted for execution, submit another task
if (ntasks > 0) {
--ntasks;
futures.add(ecs.submit(it.next()));
++active;
}
// No tasks were performed and no successful results were achieved.
else if (active == 0)
break;
// If timeout is set
else if (timed) {
// Wait for the execution result until there is a result or a timeout
f = ecs.poll(nanos, TimeUnit.NANOSECONDS);
if (f == null)
throw new TimeoutException();
// The update here is essential, because this Future may fail to execute, so you need to wait for the next result again, the timeout settings still need to be used.
long now = System.nanoTime();
nanos -= now - lastTime;
lastTime = now;
}
// No timeouts are set, and all tasks are submitted until the first execution results come out.
else
f = ecs.take();
}
// If the result is returned, try to get the result from the future. If it fails, you need to wait for the next execution result.
if (f != null) {
--active;
try {
return f.get();
} catch (ExecutionException eex) {
ee = eex;
} catch (RuntimeException rex) {
ee = new ExecutionException(rex);
}
}
}
// An error occurred while Executor Completion Service was executing and returned the future of all null s.
if (ee == null)
ee = new ExecutionException();
throw ee;
} finally {
// Attempt to cancel all tasks (without affecting completed tasks)
for (Future<T> f : futures)
f.cancel(true);
}
}ThreadPoolExecutor
ThreadPoolExecutor's execute method, which reflects what happens when a Task is added to the thread pool:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/* If the number of worker threads running is less than the set number of permanent threads, increase the worker threads and assign task to the new worker threads */
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// If a task can be added to the task queue, the number of tasks waiting is within the allowable range.
// Check again if the thread pool is closed, if it is closed, remove the task and reject it
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// If the number of tasks exceeds the capacity of existing worker threads, try creating a new worker thread
// If a new worker thread cannot be added, the task is rejected
else if (!addWorker(command, false))
reject(command);
}When performing tasks, the state of the thread pool needs to be checked frequently. Next, we will talk about how the thread pool controls the state. The above code has a member variable called ctl, which is used to mark the state of the thread pool and the number of worker threads, and is an AutomaticInteger object.
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));ctl is a 32-bit integer with the highest 3-bit representation of state:
111 is running.
000 is shutdown.
001 is stop.
010 is tidying.
011 is ternimated.
So the state value is these three plus 29 zeros, so the running value is a negative integer (the highest bit is 1), and the other states are positive integers, which will be used later when judging the size of the state comparison values.
The remaining 29 bits represent the number of worker threads (so the maximum number of threads allowed is 2, 29, minus 1).
Here is the meaning of these states. The order in which these states occur is exactly the order listed above.
running indicates normal operation
The shutdown status means a shutdown signal, similar to the shutdown button you clicked on windows.
stop means that the shutdown signal is received, which means that windows responds to the signal and sends out the message that the shutdown is on.
tidying happens after stop, indicating that some resources are being cleaned up at this time.
ternimated occurs after tidying is completed, indicating that the closure is complete.
Next, let's look at what happens when you add a worker thread:
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Back to false:
// 1. RS > shutdown, i.e. states other than shutdown and running
// 2. shutdown status
// 1) First Task is not null, that is, task allocation
// 2) No task, but workQueue (waiting task queue) is empty
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
// 1. If there is no limit on the number of threads, the number of worker threads should not be greater than the maximum (29-1 of 2)
// 2. If it is a fixed size thread pool, it should not be larger than the fixed size.
// 3. If it is an extensible thread pool, it should not exceed the upper limit of the specified number of threads.
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// Increase the number of threads with CAS operations, and if it fails, recycle
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
loop
}
}
// New worker thread
Worker w = new Worker(firstTask);
Thread t = w.thread;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int c = ctl.get();
int rs = runStateOf(c);
// Check whether any of the following states occur:
// 1. Failure to create threads
// 2. RS > shutdown, i.e. states other than shutdown and running
// 3. rs==shutdown, with task assignment
if (t == null ||
(rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null))) {
decrementWorkerCount();
tryTerminate();
return false;
}
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
} finally {
mainLock.unlock();
}
t.start();
// Consider a rare case where the worker thread calls start without completing it.
// Thread pool enters Stop state, at which time Thread#interrupt is called to interrupt each
// worker threads, but interrupt s don't necessarily work for threads that don't have a start, so
// The interrupt to this thread is omitted, so after the worker thread start
// Check below, if stop, and the thread is not interrupt, fill in this omission
// interrupt.
if (runStateOf(ctl.get()) == STOP && ! t.isInterrupted())
t.interrupt();
return true;
}ThreadPoolExecutor
ThreadPoolExecutor has a member class called Worker, which acts as a thread pool worker thread.
private final class Worker extends AbstractQueuedSynchronizer implements RunnableHere AbstractQueued Synchronizer's function is to make the Worker have the function of locking, when performing tasks, the Worker will be locked, at this time can not interrupt the Worker. When the Worker is idle, the thread pool can change some state of the Worker by acquiring locks. During this period, because locks are occupied, the Worker will not perform tasks.
The logic of Worker's work in the ThreadPoolExecutor runWorker method
public void run() {
runWorker(this);
}So go to the runWorker method:
final void runWorker(Worker w) {
Runnable task = w.firstTask;
w.firstTask = null;
boolean completedAbruptly = true;
try {
// Execute assigned tasks or wait for tasks from BlockingQueue
while (task != null || (task = getTask()) != null) {
w.lock();
clearInterruptsForTaskRun();
try {
// Pre-mission work
beforeExecute(w.thread, task);
Throwable thrown = null;
// Execute the task. If an exception occurs, the Worker will not continue to execute the task.
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// Work done
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// Worker no longer performs task processing, completedAbruptly false
// Represents a normal end, or an error in the execution of the task.
processWorkerExit(w, completedAbruptly);
}
}Take a look at processWorkerExit, focusing on how to handle exceptions to tasks
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// If an exception occurs, first update the number of Worker s
if (completedAbruptly)
decrementWorkerCount();
// Remove this Worker
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
// Attempt to stop the thread pool, the normal thread pool calls this method without any action
tryTerminate();
int c = ctl.get();
// If the thread pool is not closed,
if (runStateLessThan(c, STOP)) {
// Worker is not an exception exit. Check if the number of worker threads is less than the minimum?
// This minimum is divided into several cases:
// 1. allowCoreThreadTimeOut (JDK6 added) indicates whether thread pools are allowed to exceed
// In this case, the minimum value is 0, because if the task is not received for a certain period of time, the minimum value is 0.
// If there has been no task, the number of worker threads is 0
// 2. The minimum value is corePoolSize, because corePoolSize may be zero, so this is the case.
// Next, if there is a task, there must be a Worker, so the minimum value is 1
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return;
}
// If the number of Worker threads is less than the minimum, create a new Worker thread
addWorker(null, false);
}
}This section describes how thread pools perform state control, i. e. the opening and closing of thread pools.
Let's start with the opening of the thread pool. In this section, we look at the ThreadPool Executor construction method:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}As you can see, although the number of corePoolSize, or Worker threads, is set, ThreadPoolExecutor does not create these Worker threads by default when the thread pool is opened, but ThreadPoolExecutor provides a prestartAllCoreThreads method to open all prestart Worker threads, and prestartCoreThread attempts to open a prestart Worker thread.
Here we focus on handler, which is Rejected Execution Handler. ThreadPool Executor provides four strategies for rejecting tasks.
- CallerRunsPolicy
This strategy will still run tasks if ThreadPool Executor is not closed
- AbortPolicy
This policy throws a Rejected Execution Exception
- DiscardPolicy
This strategy ignores the task directly without any action.
- DiscardOldestPolicy
This strategy will drop the next task to be performed and join the execution queue when ThreadPool Executor is not closed.
Next to turn off, ThreadPool Executor offers shutdown and shutdown Now, which literally distinguishes the two ways, the latter trying to end the running task.
Let's start with shutdown:
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(SHUTDOWN);
interruptIdleWorkers();
onShutdown(); // Callback Method of Scheduled ThreadPool Executor
} finally {
mainLock.unlock();
}
tryTerminate();
}Look at shutdownNow:
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(STOP);
interruptWorkers();
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}The code of the two methods is very similar, but the difference is that:
The state of shutdown Now is set to STOP, and the state of shutdown is SHUTDOWN.
shutdownNow interrupts all threads, that is, all tasks, while shutdown Now interrupts only idle threads without affecting the tasks being performed.
shutdownNow exports unexecuted tasks.
The checkShutdownAccess method used by both methods is mainly to check whether the method caller has permission to interrupt the Worker thread.
The advanced RunState method is used to set the state of a thread and returns if the state value is greater than or equal to that value. Worker threads have the function of locking, so we can judge whether the Worker threads are idle by tryLock, which is the difference between the two methods.
ScheduledThreadPoolExecutor
Scheduled ThreadPoolExecutor is a subclass of ThreadPoolExecutor and implements the Scheduled ExecutorService interface.
public class ScheduledThreadPoolExecutor
extends ThreadPoolExecutor
implements ScheduledExecutorServiceScheduled ThreadPool Executor has two main functions: execution at a fixed point in time (also known as delayed execution) and repeated execution.
As with ThreadPool Executor, let's first look at the core method execute:
public void execute(Runnable command) {
schedule(command, 0, TimeUnit.NANOSECONDS);
}The execute method calls another method schedule, and we find that the three submit methods also call the schedule method, because there are two types of tasks: Callable and Runnable, so there are two overloaded schedules.
public ScheduledFuture<?> schedule(Runnable command,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<?> t = decorateTask(command,
new ScheduledFutureTask<Void>(command, null,
triggerTime(delay, unit)));
delayedExecute(t);
return t;
}
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay,
TimeUnit unit) {
if (callable == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<V> t = decorateTask(callable,
new ScheduledFutureTask<V>(callable,
triggerTime(delay, unit)));
delayedExecute(t);
return t;
}The logic of the two methods is basically the same, both wrapping tasks into Runnable Scheduled Future objects and calling delayed Execute to achieve delayed execution. Task wrapper class inherits from ThreadPoolExecutor's wrapper class RunnableFuture, and implements the Scheduled Future interface to enable wrapper classes to have delayed execution and repeated execution functions to match Scheduled ThreadPoolExecutor.
So first, let's look at Scheduled FutureTask. Here are some variables specific to Scheduled FutureTask:
private class ScheduledFutureTask<V>
extends FutureTask<V> implements RunnableScheduledFuture<V> {
/** Sequence numbers for all tasks in the thread pool */
private final long sequenceNumber;
/** The time from the start of a task, in nanoseconds */
private long time;
/**
* The interval between repeated tasks, i.e. how often to perform tasks
*/
private final long period;
/** This type of object is used for repeating tasks and queuing. */
RunnableScheduledFuture<V> outerTask = this;
/**
* Delay the index of the queue, so using the index when canceling the task will speed up the search
*/
int heapIndex;Let's look at the core method run:
public void run() {
boolean periodic = isPeriodic();
// Detecting whether a task can be run involves two other variables: continueExistingPeriodicTasks AfterShutdown
// And execute Existing Delayed Tasks AfterShutdown
// The former allows repetitive tasks to continue after shutdown
// The latter allows delayed tasks to continue after shutdown.
// So here we decide which option to use depending on whether the task is periodic, and then
// If the thread pool is running, it can certainly be executed
// If shutdown is in progress, it depends on whether the value of the option is true to determine whether tasks are allowed to execute.
// If not allowed, the task will be cancelled.
if (!canRunInCurrentRunState(periodic))
cancel(false);
// If a task can be executed, it can be executed directly for tasks that do not need to be repeated.
else if (!periodic)
ScheduledFutureTask.super.run();
// For tasks that need to be repeated, execute once, and then reset
// Update the next execution time and call reExecutePeriodic to update the task in the execution queue
// Location (actually added to the end of the queue)
else if (ScheduledFutureTask.super.runAndReset()) {
setNextRunTime();
reExecutePeriodic(outerTask);
}
}So here's the implementation of repetitive execution: task execution once, Reset status, re-joining the task queue.
Back to delayed Execute, it can ensure that tasks are executed at the exact time point. Let's see if delayed Execute is implemented if delayed execution:
private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
reject(task);
else {
super.getQueue().add(task);
if (isShutdown() &&
!canRunInCurrentRunState(task.isPeriodic()) &&
remove(task))
task.cancel(false);
else
ensurePrestart();
}
}At first glance, it is found that adding tasks to task queues is the secret of how the delayed execution function is realized.
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, TimeUnit.NANOSECONDS,
new DelayedWorkQueue());
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}Scheduled ThreadPool Executor's task queue is not an ordinary Blocking Queue, but a special implementation of Delayed WorkQueue.
In Scheduled ThreadPool Executor, Delayed WorkQueue is used to store tasks to be executed, because these tasks are delayed, and each execution takes the first task to execute, so tasks in Delayed WorkQueue must be sorted from short to long delays.
Delayed WorkQueue is implemented using heap.
Like previous analysis of BlockingQueue implementation classes, first look at the offer method, which is basically a logic for adding elements to the heap.
public boolean offer(Runnable x) {
if (x == null)
throw new NullPointerException();
RunnableScheduledFuture e = (RunnableScheduledFuture)x;
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = size;
// Because elements are stored in an array, as the heap grows, when the array is not stored enough, it needs to be expanded.
if (i >= queue.length)
grow();
size = i + 1;
// If the original queue is empty
if (i == 0) {
queue[0] = e;
// This is the heapIndex used by Runnable Scheduled Future
setIndex(e, 0);
} else {
// Adding elements to the heap
siftUp(i, e);
}
// If the queue was previously empty, then there might be threads waiting for elements, since meta-elements have been added.
// So, you need to notify these threads through Condition s
if (queue[0] == e) {
// Because the element is newly added, the first waiting thread can end the waiting, so here
// Delete the first waiting thread
leader = null;
available.signal();
}
} finally {
lock.unlock();
}
return true;
}siftUp, by the way, should be easy for anyone familiar with heap implementation to understand that this is an algorithm for adding elements to an existing heap.
private void siftUp(int k, RunnableScheduledFuture key) {
while (k > 0) {
int parent = (k - 1) >>> 1;
RunnableScheduledFuture e = queue[parent];
if (key.compareTo(e) >= 0)
break;
queue[k] = e;
setIndex(e, k);
k = parent;
}
queue[k] = key;
setIndex(key, k);
}Then look at poll:
public RunnableScheduledFuture poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// Because even if you get the task, the thread still needs to wait, and the waiting process is done with the help of the queue.
// So the poll method can only return tasks that have reached the execution point.
RunnableScheduledFuture first = queue[0];
if (first == null || first.getDelay(TimeUnit.NANOSECONDS) > 0)
return null;
else
return finishPoll(first);
} finally {
lock.unlock();
}
}Because poll methods can only return tasks that have reached the execution time point, it is not meaningful for us to understand how queues achieve delayed execution, so we should focus on take methods:
public RunnableScheduledFuture take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
// Trying to get the first element, if the queue is empty, enter and wait
RunnableScheduledFuture first = queue[0];
if (first == null)
available.await();
else {
// Get the latency of task execution
long delay = first.getDelay(TimeUnit.NANOSECONDS);
// If the task does not have to wait, it immediately returns to the thread.
if (delay <= 0)
// Take the task from the heap
return finishPoll(first);
// If the task needs to wait, and there is a thread ahead that has already waited for the task to execute (leader thread)
// We've got the task, but the execution time has not arrived, and the delay time must be the shortest.
// So the thread that executes take must continue to wait.
else if (leader != null)
available.await();
// If the current thread has the shortest latency, update the leader thread
// Wait with Condition s until the time is up, awakened or interrupted
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
// Reset the leader thread for the next loop
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
// It's easy to understand that queues don't emit signal s for empty. There are no leader threads attached here.
// The condition is that when the leader thread exists, it indicates that the leader thread is waiting for the execution time point.
// If a signal is sent at this time, awaitNanos will be triggered to return early
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
}The key point of the take method is the leader thread, because there is a delay time, even if the task is received, the thread still needs to wait, and the leader thread is the thread that executes the task first.
Because threads still need to wait for a delayed execution time after they get the task, the poll ing method of timeout waiting is interesting:
public RunnableScheduledFuture<?> poll(long timeout, TimeUnit unit)
throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
RunnableScheduledFuture<?> first = queue[0];
if (first == null) {
if (nanos <= 0)
return null;
else
nanos = available.awaitNanos(nanos);
} else {
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
return finishPoll(first);
if (nanos <= 0)
return null;
first = null; // don't retain ref while waiting
if (nanos < delay || leader != null)
nanos = available.awaitNanos(nanos);
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
long timeLeft = available.awaitNanos(delay);
nanos -= delay - timeLeft;
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
}By analyzing the above code, the principle of Delayed WorkQueue's implementation of delayed execution has been clarified.
Store tasks in heap in order of execution delay from short to long.
Through the leader thread, the thread that gets the task waits until the specified time point to execute the task.