Why do I need a consistent hash
Hash, generally translated as hash, or transliterated as hash, is to transform an input of any length (also known as pre mapping pre image) into a fixed length output through hash algorithm, and the output is the hash value. This transformation is a compression mapping, that is, the hash value space is usually much smaller than the input space, and different inputs may be hashed into the same output, so it is impossible to determine the unique input value from the hash value. In short, it is a function that compresses a message of any length to a message digest of a fixed length.
In the distributed cache service, we often need to add and delete nodes. We hope that the node addition and deletion operations can minimize the update of the mapping relationship between data nodes.
If we use the hash(key)%nodes algorithm as the routing strategy:
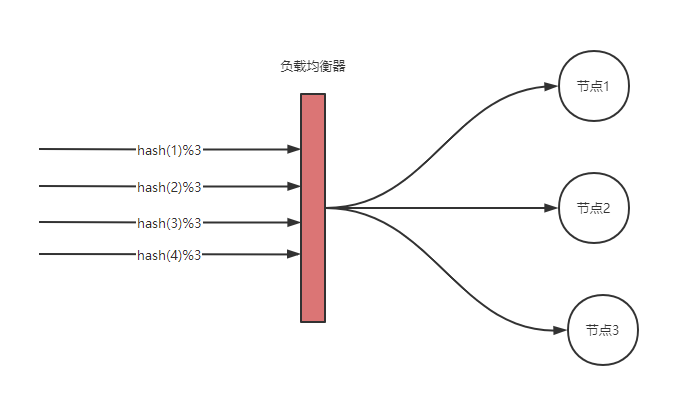
The disadvantage of hash modulus is that if nodes are deleted or added, the impact on hash(key)%nodes results is too large, resulting in a large number of requests that cannot be hit, resulting in the reload of cached data.
Based on the above shortcomings, a new algorithm: consistent hash is proposed. Consistent hash can realize node deletion and addition, which will only affect the mapping relationship of a small part of data. Because of this characteristic, hash algorithm is often used in various equalizers to realize the smooth migration of system traffic.
How consistent hashing works
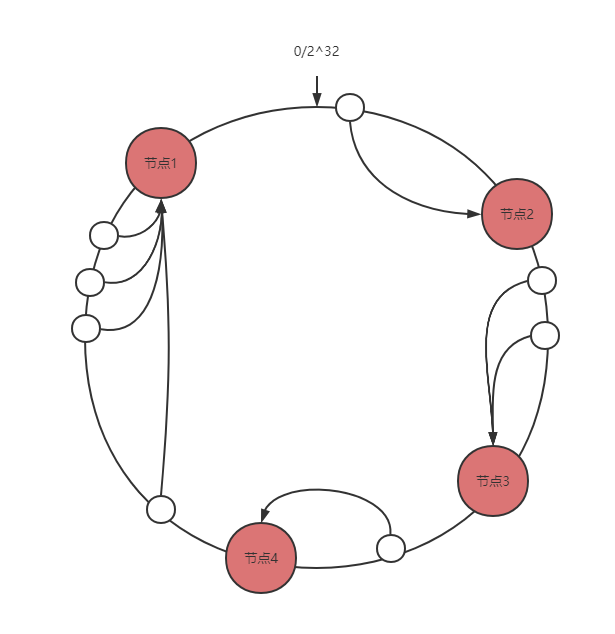
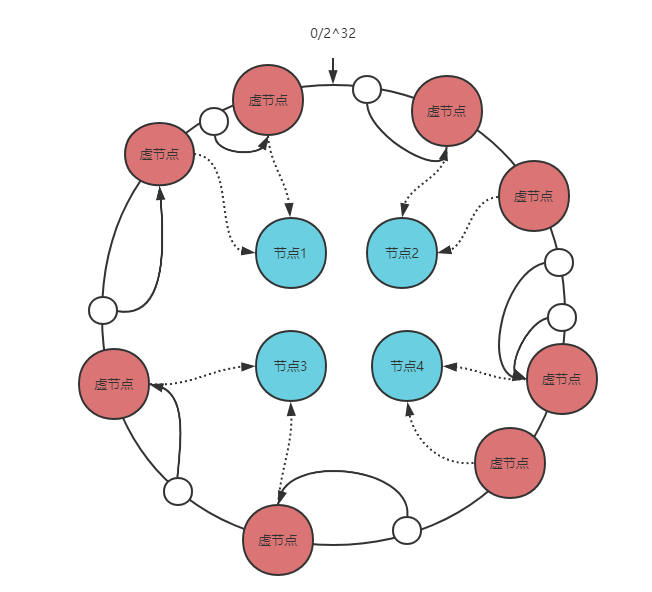
First, hash the node. The hash value is usually in the range of 2 ^ 32-1. Then, the head and tail connections of the interval 2 ^ 32-1 are abstracted into a ring, and the hash value of the node is mapped to the ring. When we want to query the target node of the key, we also hash the key, and then the first node found clockwise is the target node.
According to the principle, let's analyze the impact of node addition and deletion on the data range.
Node addition
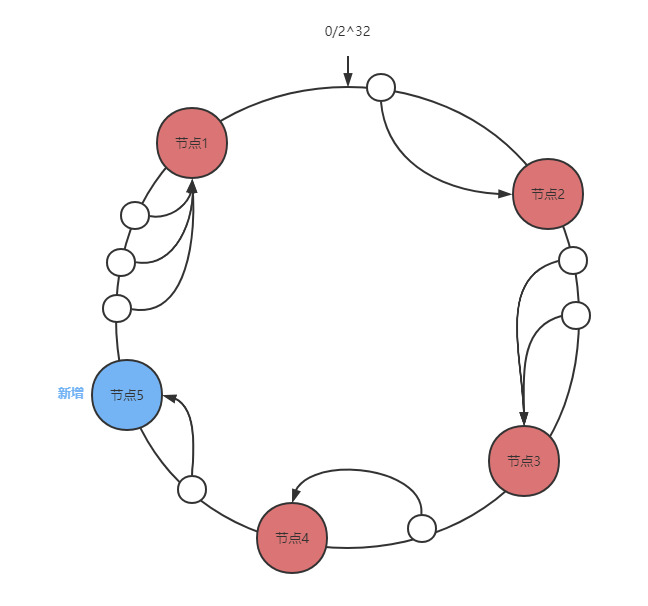
Only the data between the new node and the previous node (the first node found by the new node counterclockwise) will be affected.
Node deletion
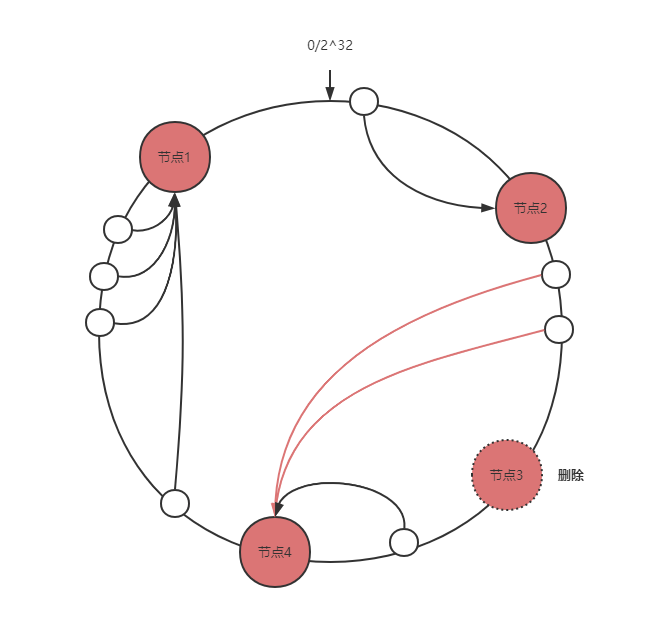
It only affects the data between the deleted node and the previous node (the first node found by the deleted node counterclockwise).
Is that all? Not yet. Imagine that if the number of nodes on the ring is very small, it is very likely to cause unbalanced data distribution. In essence, the interval distribution granularity on the ring is too coarse.
How to solve it? Isn't the particle size too coarse? Then add more nodes, which leads to the concept of virtual node of consistent hash. The function of virtual node is to reduce the granularity of node interval distribution on the ring.
A real node corresponds to multiple virtual nodes. Map the hash value of the virtual node to the ring and query the target node of the key. We can query the virtual node first and then find the real node.
code implementation
Based on the above consistent hash principle, we can extract the core functions of consistent hash:
- Add node
- Delete node
- Query node
Let's define the interface:
ConsistentHash interface {
Add(node Node)
Get(key Node) Node
Remove(node Node)
}In reality, the service capabilities of different nodes may be different due to hardware differences, so we hope to specify the weight when adding nodes. Reflected in the consistency hash, the so-called weight means that we want the hit probability ratio of the target node of the key. A large number of virtual nodes of a real node means a high hit probability.
In the interface definition, we can add two methods: adding nodes by specifying the number of virtual nodes and adding nodes by weight. In essence, it will eventually reflect that the number of virtual nodes is different, resulting in the difference of probability distribution.
When specifying weight: actual number of virtual nodes = configured virtual nodes * weight/100
ConsistentHash interface {
Add(node Node)
AddWithReplicas(node Node, replicas int)
AddWithWeight(node Node, weight int)
Get(key Node) Node
Remove(node Node)
}Next, consider several engineering implementation problems:
How are virtual nodes stored?
It's very simple. You can store it with a list (slice).
Virtual node real node relational storage
Just map.
Query clockwise how the first virtual node is implemented
Keep the list of virtual nodes in order. Binary search for the first index larger than hash(key), list[index].
There is a small probability of conflict when hashing virtual nodes. How to deal with it?
In case of conflict, it means that this virtual node will correspond to multiple real nodes. The value in the map stores the array of real nodes. When querying the target node of the key, take the module of nodes.
How to generate virtual nodes
Configure replicas based on the number of virtual nodes, and add i bytes in turn for hash calculation.
Go zero source code analysis
core/hash/consistenthash.go
Detailed notes can be viewed: https://github.com/Ouyangan/g...
It took a day to read the consistency hash source code of go zero source code. It's well written. All kinds of details have been taken into account.
The hash function used by go zero is MurmurHash3, GitHub: https://github.com/spaolacci/...
Go zero does not define the interface. It doesn't matter. Look directly at the structure ConsistentHash:
// Func defines the hash method.
// hash function
Func func(data []byte) uint64
// A ConsistentHash is a ring hash implementation.
// Consistent Hashing
ConsistentHash struct {
// hash function
hashFunc Func
// Determine the number of virtual nodes for node
replicas int
// Virtual node list
keys []uint64
// Virtual node to physical node mapping
ring map[uint64][]interface{}
// Physical node mapping to quickly determine whether there is a node
nodes map[string]lang.PlaceholderType
// Read write lock
lock sync.RWMutex
}Hash calculation of key and virtual node
The key must be converted into a string before hashing
// It can be understood as a serialization method to determine the node string value
// In case of hash conflict, the key needs to be hashed again
// In order to reduce the probability of conflict, a prime number is added in front to reduce the probability of conflict
func innerRepr(v interface{}) string {
return fmt.Sprintf("%d:%v", prime, v)
}
// It can be understood as a serialization method to determine the node string value
// Would it be better if node were forced to implement String()?
func repr(node interface{}) string {
return mapping.Repr(node)
}Here, the fmt.Stringer interface will be judged in mapping.Repr. If it matches, its String method will be called. The go zero code is as follows:
// Repr returns the string representation of v.
func Repr(v interface{}) string {
if v == nil {
return ""
}
// if func (v *Type) String() string, we can't use Elem()
switch vt := v.(type) {
case fmt.Stringer:
return vt.String()
}
val := reflect.ValueOf(v)
if val.Kind() == reflect.Ptr && !val.IsNil() {
val = val.Elem()
}
return reprOfValue(val)
}Add node
The final call is to specify the virtual node add node method
// Capacity expansion operation, adding physical nodes
func (h *ConsistentHash) Add(node interface{}) {
h.AddWithReplicas(node, h.replicas)
}Add node - assign weights
The final call is also to specify the virtual node add node method
// Add nodes by weight
// The method factor is calculated by weight, and the number of virtual nodes is finally controlled
// The higher the weight, the more virtual nodes
func (h *ConsistentHash) AddWithWeight(node interface{}, weight int) {
replicas := h.replicas * weight / TopWeight
h.AddWithReplicas(node, replicas)
}Add node - specifies the number of virtual nodes
// Capacity expansion operation, adding physical nodes
func (h *ConsistentHash) AddWithReplicas(node interface{}, replicas int) {
// Support repeatable addition
// Delete first
h.Remove(node)
// The upper limit of magnification factor cannot be exceeded
if replicas > h.replicas {
replicas = h.replicas
}
// node key
nodeRepr := repr(node)
h.lock.Lock()
defer h.lock.Unlock()
// Add node map mapping
h.addNode(nodeRepr)
for i := 0; i < replicas; i++ {
// Create virtual node
hash := h.hashFunc([]byte(nodeRepr + strconv.Itoa(i)))
// Add virtual node
h.keys = append(h.keys, hash)
// Mapping virtual nodes - real nodes
// Note that hashFunc may have hash conflicts, so append is used
// The mapping between virtual node and real node is actually an array
// A virtual node may correspond to multiple real nodes. Of course, the probability is very small
h.ring[hash] = append(h.ring[hash], node)
}
// sort
// You will use binary to find virtual nodes later
sort.Slice(h.keys, func(i, j int) bool {
return h.keys[i] < h.keys[j]
})
}Delete node
// Delete physical node
func (h *ConsistentHash) Remove(node interface{}) {
// string of node
nodeRepr := repr(node)
// Concurrent security
h.lock.Lock()
defer h.lock.Unlock()
// Node does not exist
if !h.containsNode(nodeRepr) {
return
}
// Remove virtual node mapping
for i := 0; i < h.replicas; i++ {
// DP Hash
hash := h.hashFunc([]byte(nodeRepr + strconv.Itoa(i)))
// Binary query finds the first virtual node
index := sort.Search(len(h.keys), func(i int) bool {
return h.keys[i] >= hash
})
// The slice deletes the corresponding element
if index < len(h.keys) && h.keys[index] == hash {
// Navigate to the element before the slice index
// Move the element after index (index+1) forward to overwrite index
h.keys = append(h.keys[:index], h.keys[index+1:]...)
}
// Virtual node delete mapping
h.removeRingNode(hash, nodeRepr)
}
// Delete Real node
h.removeNode(nodeRepr)
}
// Delete virtual real node mapping relationship
// hash - virtual node
// nodeRepr - real node
func (h *ConsistentHash) removeRingNode(hash uint64, nodeRepr string) {
// The map should be checked when it is used
if nodes, ok := h.ring[hash]; ok {
// Create an empty slice with the same capacity as nodes
newNodes := nodes[:0]
// Traverse nodes
for _, x := range nodes {
// If the serialization values are different, x is the other node
// Cannot delete
if repr(x) != nodeRepr {
newNodes = append(newNodes, x)
}
}
// If the remaining nodes are not empty, rebind the mapping relationship
if len(newNodes) > 0 {
h.ring[hash] = newNodes
} else {
// Otherwise, it can be deleted
delete(h.ring, hash)
}
}
}Query node
// Find the nearest virtual node according to v clockwise
// Then find the real node through the virtual node mapping
func (h *ConsistentHash) Get(v interface{}) (interface{}, bool) {
h.lock.RLock()
defer h.lock.RUnlock()
// There are currently no physical nodes
if len(h.ring) == 0 {
return nil, false
}
// DP Hash
hash := h.hashFunc([]byte(repr(v)))
// Binary search
// Because the virtual nodes are reordered every time they are added
// Therefore, the first node queried is our target node
// The remainder can achieve the ring list effect and find nodes clockwise
index := sort.Search(len(h.keys), func(i int) bool {
return h.keys[i] >= hash
}) % len(h.keys)
// Virtual node - > physical node mapping
nodes := h.ring[h.keys[index]]
switch len(nodes) {
// There is no real node
case 0:
return nil, false
// There is only one real node, which is returned directly
case 1:
return nodes[0], true
// The presence of multiple real nodes means that there is a hash conflict
default:
// At this point, we re hash v
// A new index is obtained by taking the remainder of the length of nodes
innerIndex := h.hashFunc([]byte(innerRepr(v)))
pos := int(innerIndex % uint64(len(nodes)))
return nodes[pos], true
}
}Project address
https://github.com/zeromicro/go-zero
Welcome to go zero and star support us!
Wechat communication group
Focus on the "micro service practice" official account and click on the exchange group to get the community community's two-dimensional code.