When you need to process Excel files in batches at work, are you still processing them manually one by one? Learn the following automatic batch processing methods and bid farewell to the mechanical and inefficient work!
01
OS library introduction
OS (Operation System) refers to the operating system. In Python, the OS library mainly provides some functions to interact with the operating system, that is, the computer system. Many automation operations rely on the functions of the library.
02
Basic operations of OS Library
1 get current working path
In Chapter 2 of the book compare Excel and easily learn Python report automation, we introduced how to install Anaconda and how to write code using Jupyter Notebook.
But do you know where the code written in the Jupiter notebook is stored on the computer? Do many readers not know? It's easy to know. Just enter the following code in Jupyter Notebook and run it.
import os os.getcwd()
Running the above code will get the following results.
'C:\\Users\\zhangjunhong\\python library\\Python Report automation'
The above file path is the path where the Notebook code file is located. Under which file path your code is stored, you will get the corresponding results.
2 get all file names under a folder
We often import local computer files into Python for processing. We need to know the storage path and file name of the file before importing. If there are only one or two files, you can manually enter the file name and file path, but sometimes there are many files to import. Manual input efficiency will be relatively low, and code is needed to improve efficiency.
There are four Excel files in the folder shown in Figure 1.
Figure 1
We can use os.listdir(path) to get all the file names under the path. The specific implementation code is as follows.
import os
os.listdir('D:/Data-Science/share/data/test')Running the above code will get the following results.
['3 Monthly performance-Ming Ming Zhang.xlsx', 'Li Dan's performance in March.xlsx', 'Wang Yueyue-3 Monthly performance.xlsx', 'Chen Kai's performance in March.xlsx']
3 rename the file
Renaming files is a high-frequency requirement. We can use os.rename('old_name','new_name ') to rename files. old_ Name is the old file name, new_ Name is the new file name.
Let's first create a new folder called test under the test folder_ Old file, and then use the following code to put test_ Change the old file name to test_new.
os.rename('D:/Data-Science/share/data/test/test_old.xlsx'
,'D:/Data-Science/share/data/test/test_new.xlsx')After running the above code, go to the test folder to see test_ The old file no longer exists, only test_new.
4 create a folder
When we want to create a new folder under the specified path, we can choose to create a new folder manually or by using os.mkdir(path). We only need to specify the specific path.
When the following code is run, it means that a new folder named test11 is created under the D: / Data Science / share / data path. The effect is shown in Figure 2.
os.mkdir('D:/Data-Science/share/data/test11')
Figure 2
5 delete a folder
Deleting a folder corresponds to creating a folder. Of course, we can also choose to delete a folder manually, or use OS. Removediers (path) to delete, indicating the path to delete.
When the following code is run, it means that the test11 folder just created is deleted.
os.removedirs('D:/Data-Science/share/data/test11')6 delete a file
Deleting a file is to delete a specific file, while deleting a folder is to delete the entire folder, including all files in the folder. os.remove(path) is used to delete the file, indicating the path where the file is located.
When we run the following code, it means that we will test in the test folder_ The new file was deleted.
os.remove('D:/Data-Science/share/data/test/test_new.xlsx')03
Batch operation
1. Batch read multiple files under a folder
Sometimes a folder contains multiple similar files, such as the performance files of different people in a department. We need to read these files into Python in batch and then process them.
We learned earlier how to read a file with load_work(), or read_excel(), no matter which method is adopted, you only need to indicate the path of the file to be read.
How to batch read? First get all the file names under the folder, and then traverse and read each file.
The specific implementation code is as follows.
import pandas as pd
#Get all file names under the folder
name_list = os.listdir('D:/Data-Science/share/data/test')
#for loop traversal read
for i in name_list:
df = pd.read_excel(r'D:/Data-Science/share/data/test/' + i)
print('{}Read complete!'.format(i))If you want to operate on the data of the read file, you only need to place the specific operation implementation code after the read code. For example, we need to delete duplicate values for each read in file. The implementation code is as follows.
import pandas as pd
#Get all file names under the folder
name_list = os.listdir('D:/Data-Science/share/data/test')
#for loop traversal read
for i in name_list:
df = pd.read_excel(r'D:/Data-Science/share/data/test/' + i)
df = df.drop_duplicates() #Delete duplicate value processing
print('{}Read complete!'.format(i))2 create folders in batch
Sometimes we need to create specific folders according to specific topics, such as 12 folders according to months. We described how to create a single folder earlier. If you want to create multiple folders in batch, you only need to traverse and execute the statements of a single folder. The specific implementation code is as follows.
month_num = ['1 month','2 month','3 month','4 month','5 month','6 month','7 month','8 month','9 month','10 month','11
month','12 month']
for i in month_num:
os.mkdir('D:/Data-Science/share/data/' + i)
print('{}Creation completed!'.format(i))After running the above code, 12 folders will be created under the file path, as shown in Figure 3.
Figure 3
3 batch rename files
Sometimes we have many files with the same subject, but the file names of these files are confused. For example, the file shown in Figure 4 is the performance of each employee in March, but the naming format is different. We should unify it into the format of "name + performance in March". To achieve this effect, you can rename files through the operations you learned earlier. Previously, we only introduced the operations on a single file. How can you batch operate multiple files at the same time?

Figure 4
The specific implementation code is as follows.
import os
#Gets all file names under the specified folder
old_name = os.listdir('D:/Data-Science/share/data/test')
name = ["Ming Ming Zhang","Li Dan","
Yue
Wang Yue
","Kai Chen"]
#Traverse each name
for n in name:
#Traverse each old file name
for o in old_name:
#Determine whether the old file name contains a specific name
#Rename if included
if n in o:
os.rename('D:/Data-Science/share/data/test/' + o, 'D:/Data-Science/
share/data/test/' + n +"3 Monthly performance.xlsx")After running the above code, you can see that all the original file names under the folder have been renamed, as shown in Figure 5.

Figure 5
04
Other batch operations
1 batch merge multiple files
Under the folder shown in Figure 6, there are monthly sales daily reports from January to June. It is known that the structure of these daily reports is the same, with only two columns of "date" and "sales volume". Now we want to combine these daily reports of different months into one.

Figure 6
The specific implementation code of merging monthly sales daily reports into one document is as follows.
import os
import pandas as pd
#Gets all file names under the specified file
name_list = os.listdir('D:/Data-Science/share/data/sale_data')
#Create an empty DataFrame with the same structure
df_o = pd.DataFrame({'date':[],'sales volume':[]})
#Traverse and read each file
for i in name_list:
df = pd.read_excel(r'D:/Data-Science/share/data/sale_data/' + i)
#Longitudinal splicing
df_v = pd.concat([df_o,df])
#Assign the spliced result to df_o
df_o = df_v
df_oRun the above code and you will get the merged file df_o. As shown in Figure 7.
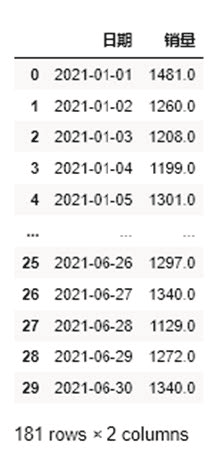
Figure 7
2 split a document into multiple documents according to the specified column
The above describes how to merge multiple files in batch. We also have the inverse requirement of merging multiple files, that is, splitting a file into multiple files according to the specified column.
As for the above data set, let's assume that we have obtained a document from January to June. In addition to the columns of "date" and "sales volume", this document also has a column of "month". What you need to do now is to split this file into multiple files according to the "month" column, and store each month as a separate file.
The specific implementation code is as follows.
#Generate a new month column df_o['month'] = df_o['date'].apply(lambda x:x.month) #Traverse each month value for m in df_o['month'].unique(): #Filter the data of specific month values df_month = df_o[df_o['month'] == m] #Save the filtered data df_month.to_csv(r'D:/Data-Science/share/data/split_data/' + str (m) + 'Monthly sales daily_After splitting.csv')
By running the above code, you can see multiple split files in the target path, as shown in Figure 8.
Figure 8
*This article is excerpted from the book "compare Excel and easily learn Python report automation". For more information about report automation using python, welcome to read this book!