Job One
content
- Requirements: Specify a website to crawl all the pictures in this website, such as China Meteorological Network (China Meteorological Network). http://www.weather.com.cn ). Crawl using single-threaded and multithreaded methods, respectively. (Limit the number of crawled pictures to the last 3 digits of the school number)
- Output information: The downloaded Url information is output in the console, and the downloaded pictures are stored in the images subfile, and screenshots are given.
Code & Result
Analyzing the html information of China Meteorological Network, we found that the link of the picture is in the'src'attribute value of the img tag and the other link is in the'href' attribute of the a tag.
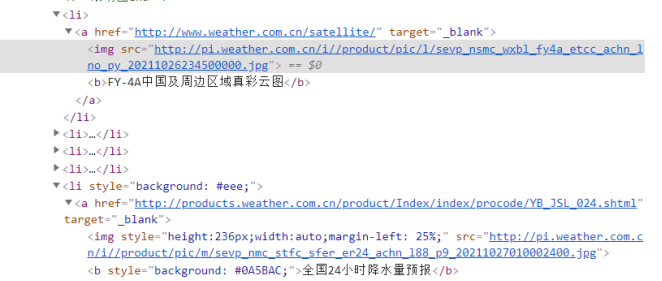
- Single Thread:
Use requests+re to match links to pictures and other links within the page. Traverse through other links and crawl pictures in them.
It is important to note that the link to some pictures you get is not a standard link like "https://...". Skip such a link.
def spider(url, headers):
global count
global urls
if count > 132: # If 132 copies have been downloaded, return
return
if url not in urls: # Determine if the link has been crawled or, if not, join the urls list and crawl it
urls.append(url)
try:
data = getHTMLText(url, headers) # Get page information
links = re.findall(r'a href="(.*?)"', data, re.S) # Regular matching to get page links on the page
photos = re.findall(r'img src="(.*?)"', data, re.S) # Regular matching to get links to pictures
for i in range(len(photos)):
if photos[i].startswith("http"): # Determine if picture links are up to standard
download(photos[i], headers) # Pass the link to the picture into the download function to download the picture
if count > 132: # Stop crawling if 132 pictures have been downloaded
break
if count <= 132: # If less than 132 pictures are downloaded, access the new link and crawl the pictures
for link in links:
spider(link, headers)
except Exception as err:
print(err)
Write a download function, download the corresponding linked pictures, and name them in the crawl order.
def download(url, count): # Download Pictures
if count > 132: # 132 downloaded returns
return
try:
data = getPhoto(url, headers) # Get picture information
with open('./images/%d%s' % (count, url[-4:]), 'wb') as f: # Rename pictures using count and their original extension
f.write(data) # Write to local file
print("{} {}".format(count, url)) # Print out picture names and links in the console
except Exception as err:
print(err)
As you can see, the pictures are downloaded in the order they were crawled.

- Multithreaded:
Requs+re is still used, but thread creation is added, pictures are crawled and downloaded concurrently, and the rest of the code is the same as a single thread.
try:
data = getHTMLText(url, headers) # Get page information
links = re.findall(r'a href="(.*?)"', data, re.S) # Match regularly to get additional links on the page
photos = re.findall(r'img src="(.*?)"', data, re.S) # Regular matching to get links to pictures
for i in range(len(photos)):
if photos[i].startswith("http"): # Determine if picture links are up to standard
# Create a thread T, execute the download function, with parameters for picture links and count values to name the pictures
T = threading.Thread(target=download, args=(photos[i], count))
T.setDaemon(False) # Non-daemon thread
T.start() # Start Thread
threads.append(T) # Load thread T into threads list
count += 1 # Crawl Pictures Plus 1
if count > 132: # Exit the loop if 132 have been downloaded
break
if count <= 132: # If you don't download 132 pictures, crawl other links on the web
for link in links:
spider(link, headers) # Crawl links
except Exception as err:
print(err)
Observe the downloaded picture information output from the console, and complete the download in sequence at first. Error-shooting found that the thread was not created with args as a parameter (statement below), which prevents the multithread from executing concurrently.
T = threading.Thread(target=download(photos[i], count))
After code adjustment, the pictures are downloaded concurrently by multiple threads, and the order of download completion is different from that of crawl.

Experience
- Through the exercises, I consolidated the traversal of the website, the search for links, and also experienced multithreaded concurrent download of pictures, which greatly accelerated the download speed.
Full code link
https://gitee.com/cxqi/crawl_project/tree/master/experiment 3/job 1
Job 2
content
- Requirements: Reproduce job one using the scrapy framework.
- Output information: same as job one.
Code & Result
Write code directly for the web page html information analysis as Job 1.
- items.py
Write a data item class PhotoItem to save picture information
class PhotoItem(scrapy.Item):
data = scrapy.Field() # Picture Binary Information
name = scrapy.Field() # Picture Name
link = scrapy.Field() # pictures linking
- pipelines.py
Write a data processing class, PhotoPipeline, to download data.
class PhotoPipeline(object):
count = 0
imdir = "E:/example/exe3/images/" # Picture Save File
print("Download:")
def process_item(self, item, spider):
try:
impath = self.imdir + item["name"] # Picture Save Path, name Pictures by item name
with open(impath, 'wb') as f:
f.write(item["data"]) # Download pictures to local files
print("{} {}".format(item["name"], item["link"])) # Print picture name and corresponding link in console
except Exception as err:
print(err)
return item
- settings.py
Write configuration file to set non-compliance with crawler protocol
ROBOTSTXT_OBEY = False #Non-compliance with crawler protocol to prevent backcrawling
Push data into the PhotoPipeline class
ITEM_PIPELINES = { # Open Pipe
'exe3.pipelines.PhotoPipeline': 300,
}
- myspider.py
Web Crawl Entry Function:
def start_requests(self): # Crawl Entry Function, crawl the page to execute the callback function parse yield scrapy.Request(url=self.url, callback=self.parse, headers=self.headers)
Specific picture links and other web page links are extracted, and two kinds of web page requests are generated, one is to link pictures, and to execute the callback function imParse; One is links to other pages, parse the callback function, and continue crawling pictures and links to other pages.
def parse(self, response):
try:
data = response.body.decode()
selector = scrapy.Selector(text=data)
photos = selector.xpath("//Img/@src'.extract() #Extract Picture Link
links = selector.xpath("//a/@href").extract()#Extract other links from the page to page through
for photo in photos: # Processing pictures
if photo.startswith("http") and self.count <= 132:
# Determine if the picture link is standard, and if the picture link is accessible, execute the callback function imParse for picture data; Also determine the number of downloaded pictures, less than 132 continue to download pictures
yield scrapy.Request(url=photo, callback=self.imParse, headers=self.headers)
if self.count <= 132: # If the number of downloaded pictures is less than 132, then crawl the links in the web page
for link in links:
if link not in self.urls: # Determine if the link has been crawled
# If it is not crawled, add it to the visited list urls and then crawl the page
self.urls.append(link)
yield scrapy.Request(url=link, callback=self.parse, headers=self.headers)
except Exception as err:
print(err)
Write another function to complete the access download of the picture link, generate a data item class PhotoItem, and push it to PhotoPipeline.
def imParse(self, response):
if self.count > 132: # 132 downloaded returns
return
try:
item = PhotoItem() # Create a PhotoItem object
item["data"] = response.body # Picture data is the page information corresponding to the picture link
item["name"] = str(self.count) + response.url[-4:] # Rename pictures, including counting counts and suffix names for the pictures themselves
item["link"] = response.url # pictures linking
yield item
self.count += 1
except Exception as err:
print(err)
Run the program and the console output is as follows:
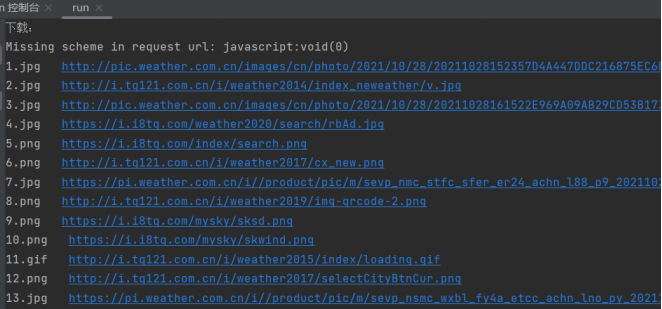
Download pictures:

Experience
Through the exercises, I consolidated the scrapy framework's practice of crawling web page information, and learned to process information for different needs, which can be achieved by writing multiple callback functions.
Full code link
https://gitee.com/cxqi/crawl_project/tree/master/experiment 3/job 2
Job Three
content
- Requirements: Crawl Douban movie data using scrapy and xpath, and store the content in the database, while storing the pictures in the imgs path.
- Candidate sites: https://movie.douban.com/top250
- Output information:
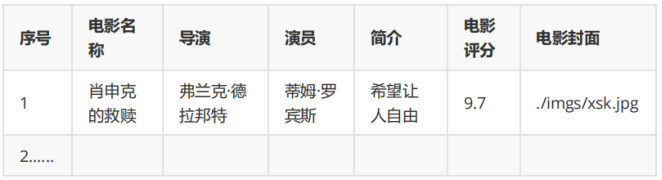
Code & Result
- items.py
From the output information we get information about a movie we want to extract:
class MovieItem(scrapy.Item):
rank = scrapy.Field() # Movie Ranking
name = scrapy.Field() # Movie Name
director = scrapy.Field() # director
actor = scrapy.Field() # performer
summary = scrapy.Field() # Sketch
score = scrapy.Field() # Movie Scoring
photo = scrapy.Field() # Movie Cover
link = scrapy.Field() # Movie Cover Picture Link
- myspider.py
Find the location of the required information in the html information of the web page and extract the information.
Note here that in the resulting list of movies, xpath positioning for each movie needs to be written in the form of'. //', you cannot ignore'.', otherwise extract_ Only the first movie on each page can be crawled after first.
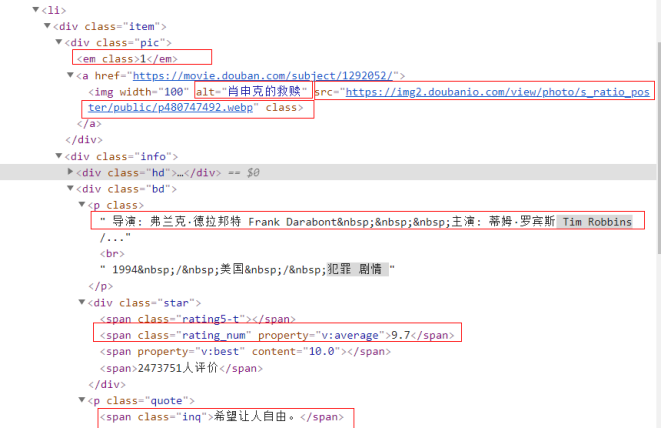
movies = selector.xpath("//li/div[@class='item'] #All movies in a web page
for movie in movies:
rank = movie.xpath(".//Div[@class='pic']/em/text()').extract_ First() #Movie Ranking
name = movie.xpath(".//Div[@class='pic']//img/@alt').extract_first()#movie name
p = movie.xpath(".//Div[@class='bd']/p/text()').extract_ First() #Movie director and director information
summary = movie.xpath(".//P[@class='quote']/span/text()'.extract_first()#Introduction to Movies
score = movie.xpath(".//Span[@class='rating_num']/text()'.extract_ First() #Movie Score
link = movie.xpath(".//Div[@class='pic']//img/@src').extract_first()#Link to picture of movie cover
Discovering that some information is not directly available, the movie director and actor information are matched in a tag by rematching the extracted string.

director = re.findall(r'director: (.*?)\xa0', p) # re matches the director of the movie actor = re.findall(r'To star: (.*)', p) # re matches the director of the movie
To generate a data project class MovieItem, be aware to handle certain information that cannot be crawled, such as setting it to ".
item = MovieItem() # Create a MovieItem object # Processing the data and converting None to "" if the extracted information does not exist item["rank"] = rank if rank else "" item["name"] = name if name else "" item["director"] = director[0] if director else "" item["actor"] = actor[0] if actor else "" item["summary"] = summary if summary else "" item["score"] = score if score else "" # Set item's photo to the local file directory where the movie cover picture is saved item["photo"] = "./imgs/" + name + ".jpg" if name else "" item["link"] = link if link else "" yield item # Push item to data pipeline under pipelines.py
For multi-page crawling, we also need to explore the law of page turning, we can see that the law is relatively simple.



self.page += 25 if self.page <= 225: # Page flipping process, crawling 10 pages url = self.start_url + "?start=" + str(self.page) + "&filter=" yield scrapy.Request(url=url, callback=self.parse, headers=self.headers)
- pipelines.py
MoviePipeline creates database tables and inserts information.
def process_item(self, item, spider):
try:
if self.opened:
# Store the crawled movie information in the database
self.cursor.execute("insert into movies (Sequence Number, Movie Name, director, performer, brief introduction, Movie Scoring, Movie Cover)"
"values (?,?,?,?,?,?,?)", (item["rank"], item["name"], item["director"],
item["actor"], item["summary"], item["score"], item["photo"]))
self.count += 1
except Exception as err:
print(err)
return item
PhotoPipeline inherits ImagesPipeline to download pictures.
class PhotoPipeline(ImagesPipeline): # Introducing the ImagePipeline channel
def get_media_requests(self, item, info): # Override get_media_requests function, which generates a request request request from the url of the picture
yield scrapy.Request(url=item['link'], meta={'item': item}) # Transmit item using meta parameter to read movie name in item when renaming
def file_path(self, request, response=None, info=None):
item = request.meta['item'] # The meta above is passed to the item
# Picture rename, request.url.split ('/') [-1].split ('.)') [-1] get picture suffix jpg,png
image_name = item['name'] + '.' + request.url.split('/')[-1].split('.')[-1]
# Picture Download Directory
filename = u'imgs/{0}'.format(image_name)
return filename
def item_completed(self, results, item, info):
# Judge that if a path exists, save the picture to it
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths: # If there are no pictures in it, drop it
raise DropItem("Item contains no images")
return item
- settings.py
IMAGES_STORE = r'.' # Set Picture Save Address
ROBOTSTXT_OBEY = False # Non-compliance with crawler protocol to prevent backcrawling
ITEM_PIPELINES = { # Open the pipe, assign the integer value to each pipe, determine the order in which they run, lower the number, higher the priority value
'exe3_2.pipelines.MoviePipeline': 100,
'exe3_2.pipelines.PhotoPipeline': 200,
}
- Result
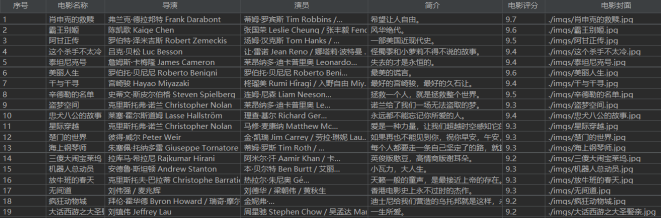
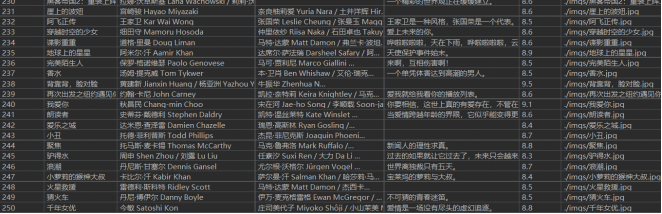
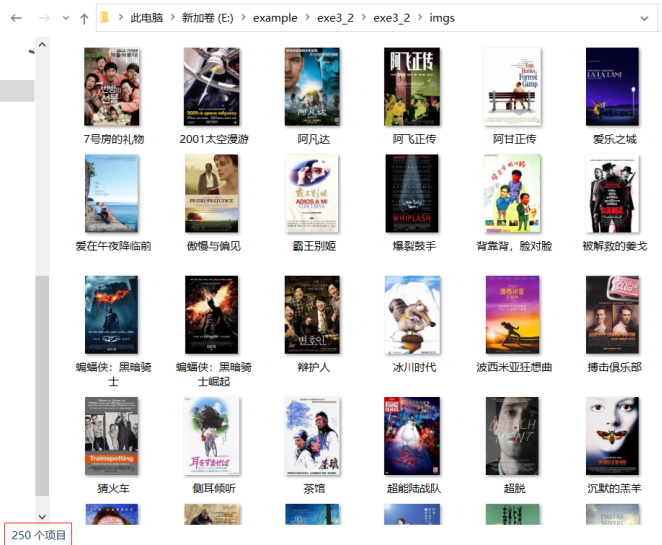
Experience
Through practice, I learned another way to download pictures in the scarpy framework in addition to the Job 2 method. At the same time, I have mastered the method of meta-parameterization, because the special requirement is to rename pictures, which need to be parameterized in scrapy.Request in order to get the movie name corresponding to the pictures when renaming.
Full code link
https://gitee.com/cxqi/crawl_project/tree/master/experiment 3/job 3