Catalog:
1. Simulation data and drawing
5, Advantages and disadvantages of KNN
I. Introduction
K nearest neighbor (KNN) algorithm is a supervised ML algorithm, which can be used in classification and regression prediction problems. However, it is mainly used for classification prediction in the industry. The following two attributes define KNN well:
- Lazy learning algorithm: because it has no special training stage, and uses all data for training during classification.
- Nonparametric learning algorithm: because it does not assume any information about the underlying data.
2, Workflow
K nearest neighbor (KNN) algorithm uses "feature similarity" to predict the value of new data point, which means that a value will be assigned to the new data point according to the matching degree between the new data point and the point in the training set. We can learn how it works by following these steps:
Step 1: load the training and test data.
Step 2: select the value of K, the nearest data point (K can be any integer).
Step 3: for each point in the test data, do the following:
-
Use any of the following methods to calculate the distance between each row of test data and training data: Euclidean distance, Manhattan distance or Hamming distance. The most commonly used distance calculation method is Euclid.
-
Sort them in ascending order based on the distance value.
-
It then selects the first K rows from the sorted array.
-
Now, it will assign this class to the test point based on the most frequent category in these rows.
Step 4: end.
Three, example
The following is an example of understanding the concept of K and the work of KNN algorithm.
Suppose we have a dataset that we can plot as follows. As follows:
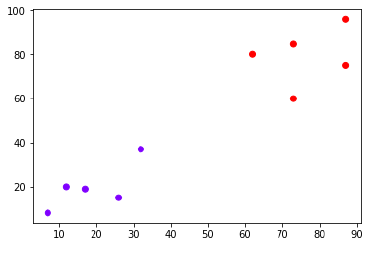
Now, we need to classify new data points with black dots (at points 60 and 60) into blue or red categories. Let's say K = 3, that is, it will find three closest data points. As shown in the figure:
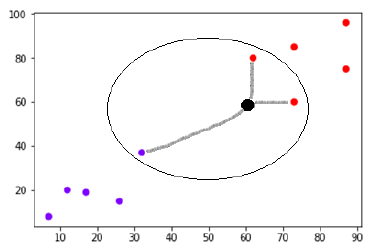
We can see the three nearest neighbors of data points with black dots in the figure above. Of these three, two belong to the red level, so the black dot will also be assigned to the red level.
4, Implementation in Python
1. Simulation data and drawing
# Import the corresponding package
import numpy as np
import matplotlib.pyplot as plt
# Analog data
raw_data_X = [[3.39, 2.33],
[3.11, 1.78],
[1.34, 3.36],
[3.58, 4.67],
[2.28, 2.86],
[7.42, 4.69],
[5.74, 3.53],
[9.17, 2.51],
[7.79, 3.42],
[7.93, 0.79]]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_Y)
# Draw a scatter diagram
plt.scatter(X_train[y_train==0, 0], X_train[y_train==0, 1], color='g')
plt.scatter(X_train[y_train==1, 0], X_train[y_train==1, 1], color='r')
plt.show()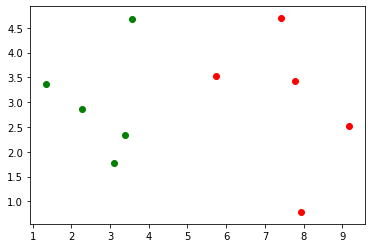
# Add a new data point X = np.array([8.09, 3.36])
# Draw a scatter diagram of adding new data points plt.scatter(X_train[y_train==0, 0], X_train[y_train==0, 1], color='g') plt.scatter(X_train[y_train==1, 0], X_train[y_train==1, 1], color='r') plt.scatter(X[0], X[1], color='b') plt.show()
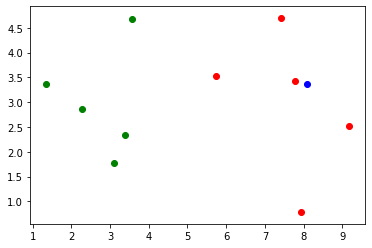
2.KNN process
① Calculate distance
# Distance between other data and new data points
from math import sqrt
# Method 1
distance = []
for x_train in X_train:
d = sqrt(np.sum((x_train - X)**2))
distance.append(d)
distance
# Method two
distance = [sqrt(np.sum((x_train - X)**2)) for x_train in X_train][4.811538215581374,
5.224633958470201,
6.75,
4.696402878799901,
5.831474942070831,
1.489227987918573,
2.356140912594151,
1.3743725841270265,
0.30594117081556693,
2.574975728040946]
② Sort them in ascending order based on distance values
# Sort ascending (sort by subscript) nearest = np.argsort(distance) nearest
array([8, 7, 5, 6, 9, 3, 0, 1, 4, 2], dtype=int64)
③ The first K rows will be selected from the sorted array
# Set k to 6. k = 6 # Display the type of the first k rows from the sorted array topK_y = [y_train[i] for i in nearest[:k]] topK_y
[1, 1, 1, 1, 1, 0]
④ Assign this class to the test point based on the most frequent category in these lines
# Import Statistics Package from collections import Counter # Display the corresponding quantity of each category votes = Counter(topK_y) votes
Counter({1: 5, 0: 1})
It can be seen that the number of occurrences of 1 is 5 at most. , the type of the new data point is 1, red.
votes.most_common(2) # Display as [(1, 5), (0, 1]] votes.most_common(1) # Display as [(1, 5]] votes.most_common(1)[0][0] # Display is 1 # Forecast data predict_y = votes.most_common(1)[0][0] predict_y
1
3. Use KNN in scikit learn
# Guide bag
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
# Set k to 6.
kNN_classifier = KNeighborsClassifier(n_neighbors = 6)
# train
raw_data_X = [[3.39, 2.33],
[3.11, 1.78],
[1.34, 3.36],
[3.58, 4.67],
[2.28, 2.86],
[7.42, 4.69],
[5.74, 3.53],
[9.17, 2.51],
[7.79, 3.42],
[7.93, 0.79]]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_y)
kNN_classifier.fit(X_train, y_train)
# New data
X = np.array([8.09, 3.36])
X_predict = X.reshape(1, -1)
# Forecast data
y_predict = kNN_classifier.predict(X_predict)
y_predict[0]
1
5, Advantages and disadvantages of KNN
1. advantages
-
A very simple algorithm, easy to understand and explain.
-
It is very useful for non-linear data, because there is no hypothesis about data in this algorithm.
-
A general algorithm, because we can use it for classification and regression.
-
It has relatively high accuracy, but it has a better supervised learning model than KNN.
2. disadvantages
-
This is a computationally expensive algorithm because it stores all the training data.
-
Compared with other supervised learning algorithms, it needs high storage capacity.
-
The prediction is very slow at large N.
-
It's very sensitive to the size of the data and its unrelated functions.
6, Application of KNN
Here are some areas where KNN can be successfully applied:
1. Banking system
Can KNN be used in the banking system to predict the weather that an individual is suitable for loan approval? Does the individual have similar characteristics to the defaulter?
2. Calculate credit rating
By comparing with people with similar characteristics, KNN algorithm can be used to find personal credit rating.
3. politics
With KNN algorithm, we can divide potential voters into several categories, such as "will vote", "will not vote", "will vote for the party's Congress", "will vote for the party's Representatives".
4. Other fields
Speech recognition, handwriting detection, image recognition and video recognition.

