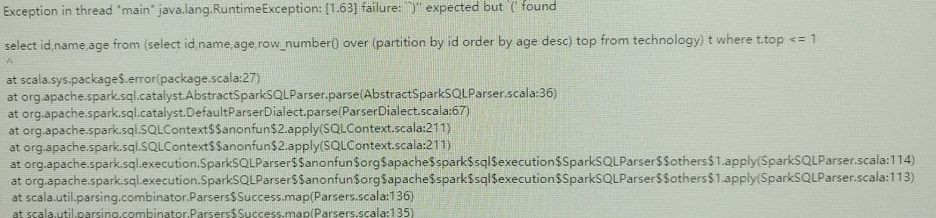
I. Introduction
The window function row ou number() is a function that groups one field and then takes the first values sorted by another field, which is equivalent to grouping topN. If a windowing function is used in the SQL statement, the SQL statement must be executed with HiveContext.
II. Code practice [use HiveContext]
package big.data.analyse.sparksql import org.apache.log4j.{Level, Logger} import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{Row, SparkSession} /** * Created by zhen on 2019/7/6. */ object RowNumber { /** * Set log level */ Logger.getLogger("org").setLevel(Level.WARN) def main(args: Array[String]) { /** * Create spark portal, support Hive */ val spark = SparkSession.builder().appName("RowNumber") .master("local[2]").enableHiveSupport().getOrCreate() /** * Create test data */ val array = Array("1,Hadoop,12","5,Spark,6","3,Solr,15","3,HBase,8","6,Hive,16","6,TensorFlow,26") val rdd = spark.sparkContext.parallelize(array).map{ row => val Array(id, name, age) = row.split(",") Row(id, name, age.toInt) } val structType = new StructType(Array( StructField("id", StringType, true), StructField("name", StringType, true), StructField("age", IntegerType, true) )) /** * Converted to df */ val df = spark.createDataFrame(rdd, structType) df.show() df.createOrReplaceTempView("technology") /** * Apply window function row Ou number * Note: windowing function can only be used under hiveContext */ val result_1 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top <= 1") result_1.show() val result_2 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top <= 2") result_2.show() val result_3 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top <= 3") result_3.show() val result_4 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top > 3") result_4.show() } }
Results [use HiveContext]
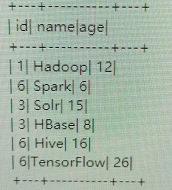
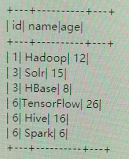
1. Initial data
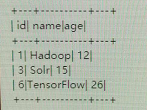
2. When top < = 1
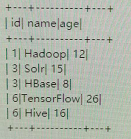
3. When top < = 2
4. When top < = 3
5. When top > 3, the maximum number of groups is 3.
IV. code implementation [do not use HiveContext]
package big.data.analyse.sparksql import org.apache.log4j.{Level, Logger} import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{Row, SparkSession} /** * Created by zhen on 2019/7/6. */ object RowNumber { /** * Set log level */ Logger.getLogger("org").setLevel(Level.WARN) def main(args: Array[String]) { /** * Create spark entry, Hive not supported */ val spark = SparkSession.builder().appName("RowNumber") .master("local[2]").getOrCreate() /** * Create test data */ val array = Array("1,Hadoop,12","5,Spark,6","3,Solr,15","3,HBase,8","6,Hive,16","6,TensorFlow,26") val rdd = spark.sparkContext.parallelize(array).map{ row => val Array(id, name, age) = row.split(",") Row(id, name, age.toInt) } val structType = new StructType(Array( StructField("id", StringType, true), StructField("name", StringType, true), StructField("age", IntegerType, true) )) /** * Converted to df */ val df = spark.createDataFrame(rdd, structType) df.show() df.createOrReplaceTempView("technology") /** * Apply window function row Ou number * Note: windowing function can only be used under hiveContext */ val result_1 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top <= 1") result_1.show() val result_2 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top <= 2") result_2.show() val result_3 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top <= 3") result_3.show() val result_4 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top > 3") result_4.show() } }
V. results [do not use HiveContext]