Summary
Popular hot data refers to data used in high frequency, such as some hot events, because of the fermentation effect of the network, the concurrency can reach hundreds of thousands or even millions in a short time. For such scenarios, we need to analyze the bottlenecks of the system, as well as the technical implementation of the response.
Programme Explanation
-
Evolution of Large Concurrency Architecture
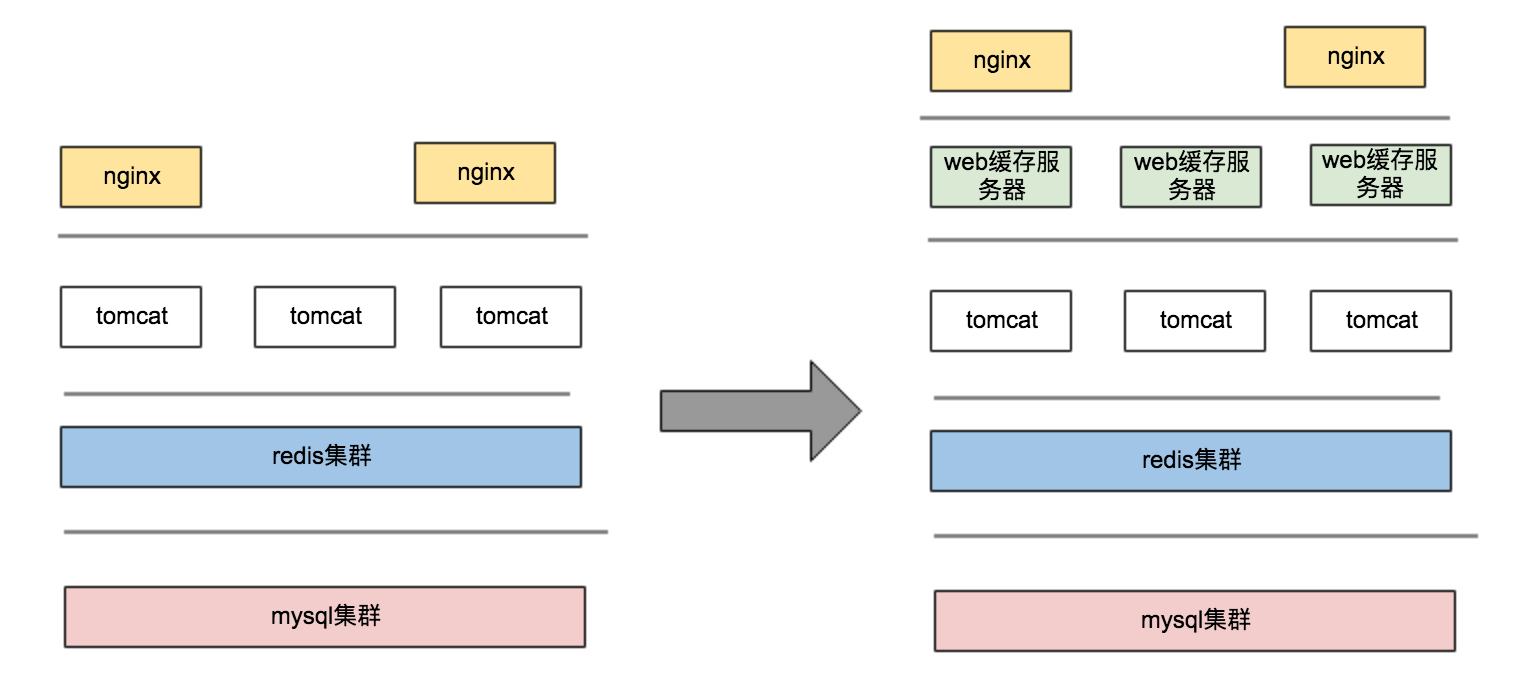
1. The difference between Figure 1 and Figure 2 is that there will be a layer of web caching server in the middle. This service can be designed by nginx+lua+redis. The hot data of the cache layer is scattered, which will be introduced in the subsequent section "High concurrency".
2. Hot data can certainly be intercepted in the web layer cache server to prevent a large number of requests from hitting the application server. But for non-hot data, it will be requested to DB after passing through the cache. This part of data is thousands of QPS per second, which also causes great pressure on DB. At this time, we need a certain solution to ensure that. The timeliness of requests is how to reduce the number of IO s at the DB level -
Scene classification
Hot data concurrency can be divided into read and write scenarios. Most of the high concurrency scenarios are read scenarios. Whatever architecture is adopted, hot data need to be dispersed at the cache level and DB level. This chapter focuses on the latter. -
Principle analysis
Everyone knows that the performance of the system will be significantly improved after the hot data is dispersed. What's the reason? Next, we will discuss some key knowledge of db storage. The two above are two mysql storage engines that are often used by everyone, especially the latter. Basically, most of the tables I encounter in my work. Both are defined as innodb engines. What's the difference between them? What's the difference between using scenarios?
1. Reading Data
myisam: Like innodb, it is implemented by BTREE. myisam is a non-aggregated index, and the index file and data file are separated. It is very efficient to read. Why is it because its storage structure determines that the leaf nodes of the tree point to the physical address of the file, so it is more efficient to query.
Innodb: It is achieved by clustering index, clustering according to the primary key, so InnoDB engine must have a unique identifier to identify this column of data. For clustering index, its leaf node stores data, and for innodb's auxiliary index, its leaf node is the value of the primary key, so the second check is added when querying. Find, to avoid this situation, you can use aggregated indexes directly, but the reality is that in most business scenarios we still need to resort to auxiliary indexes.
2. Writing Data
myisam: does not support things, and write priority is higher than read priority, multithreaded read concurrent, read and insert can be concurrent by optimizing parameters, read and update can not be concurrent, lock level is table level lock
innodb: support things, can achieve read-write concurrency, row-level lock, write performance better than myisam engine
3. Data Pages
It is a basic unit of InnoDB data storage. It can be modified by optimizing the innodb_page_size parameter. The default is 16K. According to the principle of clustering index mentioned above, the size of index and single data determines the number of records that the data page can contain. The more data records it contains, the more pages it needs to be turned. The smaller the probability is, the smaller the number of IO sessions will be.
Ways of realization
-
Vertical Subtable
Vertical sub-tables are columns that can be disassembled according to business functions or hot or cold. For example, the user table can be disassembled according to the use of hot and cold scenarios as follows: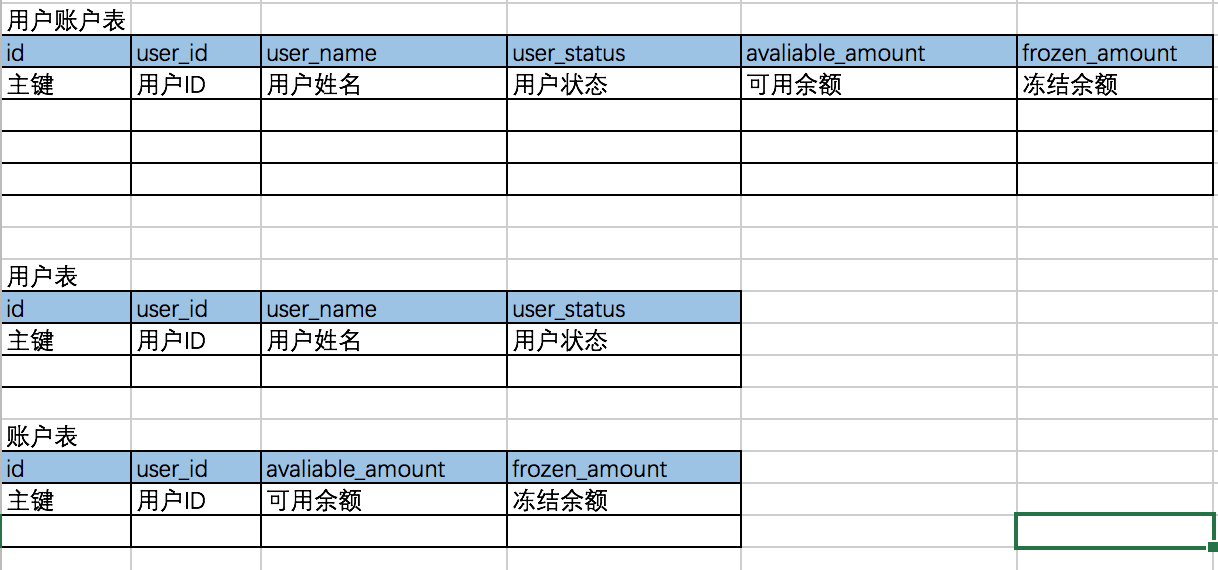
The significance of vertical table splitting lies in further splitting the hot table to reduce the IO problem caused by the multi-page query caused by the long single row of the data table. -
Horizontal sub-table
Horizontal table is to disassemble rows, after disassembly, the amount of data of single table will be smaller.
For example, for 50 million data volume, do horizontal table, the original single table 50 million data records, divided into 10 tables, each table is 5 million records.
The size of each index page is fixed by default of 16K, so when the size of a single page is fixed, the more records in a single table, the more pages in an index page, the more paging probability and frequency will increase during query.
Horizontal sub-table is to solve this problem, the implementation of sub-table: partition, sub-table/sub-library, specific reference to the following introduction. -
Best Practices
1. Separation of hot and cold data
Take the article content system as an example: title, author, classification, creation time, point approval, reply number, latest reply time
1.1. Cold data: It can be understood as static data, which will be read frequently, but almost or rarely changed. This kind of data has high performance requirements for reading. Data storage can use myisam engine.
1.2. Hot data: Data content is frequently changed. This kind of data requires high concurrent reading and writing. We can use innodb engine to store it.
According to the specific usage scenario, different storage engines are used to achieve the relative optimal performance. The table structure of the article content system is divided into hot and cold parts. The table structure after splitting is as follows:
1.3. Performance comparison before and after splitting
The trend of performance comparison is as follows: 50 concurrent requests are simulated, a total of 2500 requests are made, 50 requests per thread are randomly selected by ID. This approach is closer to the real query scenario, and the effect of split is obviously better than that of others.
Split form test:mysqlslap -h127.0.0.1 -uroot -P3306 -p --concurrency=50 --iterations=1 --engine=myisam --number-of-queries=2500 --query='select * from cms_blog_static where id=RAND()*1000000' --create-schema=test
Unsplit test:mysqlslap -h127.0.0.1 -uroot -P3306 -p --concurrency=50 --iterations=1 --engine=innodb --number-of-queries=2500 --query='select * from cms_blog where id=RAND()*1000000' --create-schema=test
2. Reducing the Size of Single Line Data
For split tables, can we further reduce the size of single-row data? To sum up, the commonly used methods are as follows:
2.1. Setting Reasonable Field Length
Everyone knows that different field types occupy different storage space, as shown in the following figure:
In practical use, we need to choose a reasonable type according to the actual needs, which can effectively reduce the size of single-line data. For example, user_status, we can generally define it as tinyint(1). It is not necessary to define it as int. White takes up more than 3 bytes.type Length (bytes) Fixed/Unfixed Length TINYINT 1 Fixed length SMALLINT 2 Fixed length MEDIUMINT 3 Fixed length INT 4 Fixed length BIGINT 8 Fixed length FLOAT(m) 4 bytes (m<=24), 8 bytes (m >=24 and m<=53) Non-constant length FLOAT 4 Fixed length DOUBLE 8 Fixed length DOUBLE PRECISION 8 Fixed length DECIMAL(m,d) M bytes (m > d), d+2 bytes (m < d) Non-constant length NUMBER(m,d) M bytes (m > d), d+2 bytes (m < d) Non-constant length DATE 3 Fixed length DATETIME 8 Fixed length TIMESTAMP 4 Fixed length TIME 3 Fixed length YEAR 1 Fixed length CHAR(m) m Non-constant length VARCHAR(m) L byte, L is the actual storage byte (l<=m) Non-constant length BLOB, TEXT l+2 bytes, l is the actual storage byte Non-constant length LONGBLOB, LONGTEXT l+4 bytes, l is the actual storage byte Non-constant length
2.2. Setting Reasonable Index Length
2.2.1. For the fields that need to be indexed, if the space occupied by the fields is larger, the longer the indexing length is, the fewer data bars and the more frequent the queries need to do IO when the index page size remains unchanged.
2.2.2 For some index fields, if we can achieve a good distinction through prefix fields, we can control the length of index creation. The purpose is to increase the number of data rows in index pages and reduce IO in the following ways:
2.2.3. Index Selectivity//As follows, we specify the length of the composite index based on field 1 and field 2 alter table table_name add index index_name (field1(length1),field2(length2))
Index itself is overhead. First, it stores resources, then inserts and updates the maintenance of B+Tree tree. The performance of data updates is degraded. So the principle for us is: whether index should be built or not, and what fields should be used to build it.
Less data volume - no construction, low discrimination or selectivity - no construction, less data volume is easy to understand, less than 1W data full table scanning can also receive, selectivity or discrimination refers to the degree of data dispersion, such as a user table, with a gender field, the larger the amount of data, the worse its index selectivity. The calculation formula is as follows:
Similarly, for fields that need to control the length of the index, the computational selectivity is as follows://Return value range (0,1). The larger the value, the higher the index selectivity. select distinct(col)/count(*) from table_name
2.2.4. Performance comparisonselect distinct(left(col,n))/count(*) from table_name
By optimizing the size of data rows based on 100w data, the performance comparison results are as follows:
The table structure before and after optimization is defined as follows:
The pressure test script is as follows:--Before optimization CREATE TABLE `cms_blog` ( `id` bigint(20) NOT NULL auto_increment, `title` varchar(60) NOT NULL, `creator` varchar(20) NOT NULL, `blog_type` tinyint(1) not NULL, `reply_praise` int(10) UNSIGNED, `reply_count` int(10) UNSIGNED, `create_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', `update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=innodb DEFAULT CHARSET=utf8; --Create an index alter table cms_blog add index idx_reply_count (reply_count); --After optimization reply_praise and reply_count CREATE TABLE `cms_blog_v2` ( `id` bigint(20) NOT NULL auto_increment, `title` varchar(60) NOT NULL, `creator` varchar(20) NOT NULL, `blog_type` tinyint(1) not NULL, `reply_praise` MEDIUMINT(10) UNSIGNED, `reply_count` MEDIUMINT(10) UNSIGNED, `create_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', `update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=innodb DEFAULT CHARSET=utf8; --Create an index alter table cms_blog_v2 add index idx_reply_count (reply_count);
The performance of the old and new gauges is as follows:--Pressure test scripts, old tables mysqlslap -h127.0.0.1 -uroot -P3306 -p --concurrency=50 --iterations=1 --engine=innodb --number-of-queries=2500 --query='select * from cms_blog where reply_count>999990' --create-schema=test --Pressure test script, new table mysqlslap -h127.0.0.1 -uroot -P3306 -p --concurrency=50 --iterations=1 --engine=innodb --number-of-queries=2500 --query='select * from cms_blog_v2 where reply_count>999990' --create-schema=test
The performance of the new table has been significantly improved after optimization: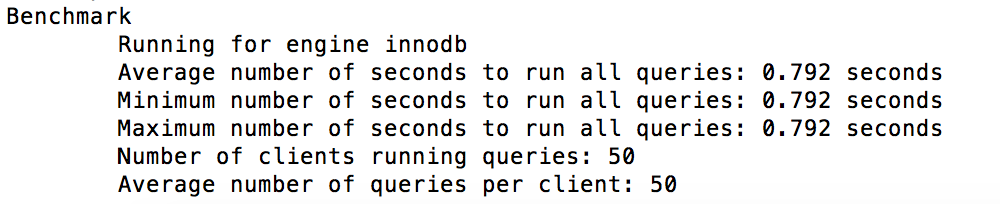
2.3. Selection of Primary Key
Use self-increasing primary keys to keep monotony as far as possible, avoid using uuid, hash mode and business custom primary keys, and reduce the impact of index reconstruction on Performance
3. Decentralized Data Page Query
3.1. Data partitioning
Data partition can effectively improve query performance, make full use of IO storage associated with different partitions, logically belong to the same table, physically can be dispersed to different disk storage, the disadvantage is that the performance of cross-partition query is slightly poor, so Internet companies rarely use data partition in practice, general recommendations Realization of Physical Tabulation -
3.1.1. ZoningCREATE TABLE table_name ( id INT AUTO_INCREMENT, customer_surname VARCHAR(30), store_id INT, salesperson_id INT, order_date DATE, note VARCHAR(500), INDEX idx (id) ) ENGINE = INNODB PARTITION BY LIST(store_id) ( PARTITION p1 VALUES IN (1, 3, 4, 17) INDEX DIRECTORY = '/var/path2' DATA DIRECTORY = '/var/path1';
3.1.1.1,RANGE partitioning
3.1.1.2,LIST PartitioningCREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT NOT NULL, store_id INT NOT NULL ) PARTITION BY RANGE (store_id) ( PARTITION p0 VALUES LESS THAN (6), PARTITION p1 VALUES LESS THAN (11), PARTITION p2 VALUES LESS THAN (16), PARTITION p3 VALUES LESS THAN (21) );
3.1.1.3,COLUMNS PartitioningCREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT, store_id INT ) PARTITION BY LIST(store_id) ( PARTITION pNorth VALUES IN (3,5,6,9,17), PARTITION pEast VALUES IN (1,2,10,11,19,20), PARTITION pWest VALUES IN (4,12,13,14,18), PARTITION pCentral VALUES IN (7,8,15,16) );
3.1.1.4,HASH Partitioning--range columns CREATE TABLE rc1 ( a INT, b INT ) PARTITION BY RANGE COLUMNS(a, b) ( PARTITION p0 VALUES LESS THAN (5, 12), PARTITION p3 VALUES LESS THAN (MAXVALUE, MAXVALUE) ); --list columns CREATE TABLE customers_1 ( first_name VARCHAR(25), last_name VARCHAR(25), street_1 VARCHAR(30), street_2 VARCHAR(30), city VARCHAR(15), renewal DATE ) PARTITION BY LIST COLUMNS(city) ( PARTITION pRegion_1 VALUES IN('Oskarshamn', 'Högsby', 'Mönsterås'), PARTITION pRegion_2 VALUES IN('Vimmerby', 'Hultsfred', 'Västervik'), PARTITION pRegion_3 VALUES IN('Nässjö', 'Eksjö', 'Vetlanda'), PARTITION pRegion_4 VALUES IN('Uppvidinge', 'Alvesta', 'Växjo') );
3.1.1.5,KEY PartitioningCREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT, store_id INT ) PARTITION BY HASH(store_id) PARTITIONS 4;
3.2. Data Subtable/DatabaseCREATE TABLE tk ( col1 INT NOT NULL, col2 CHAR(5), col3 DATE ) PARTITION BY LINEAR KEY (col1) PARTITIONS 3;
The problem solved by data tables can improve the concurrent ability of single tables. Files are distributed in different tables, which further improves IO performance. In addition, the amount of data affected by read-write locks becomes less. The data needed to be indexed and reconstructed for insert or update will be reduced, and the performance of insert or update will be better.
3.2.1. Tabulation and database
3.2.1.1: Hash mode, hash (keyword)% N
3.2.1.2: By time, e.g. by year or month
3.2.1.3. According to business, take order business as an example, platform order and tripartite order
3.2.2. Sub-database and sub-table Middleware
Generally speaking, it can be divided into client-side implementation and proxy-side implementation, such as: cobar, sharding-jdbc, mycat, etc., which can be retrieved by itself.