Test text data used by the program:
Dear River Dear River Bear Spark Car Dear Car Bear Car Dear Car River Car Spark Spark Dear Spark
1 main categories
(1) Maper class
The first is the custom Maper class code
public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//fields: data representing a line of text: dear bear river
String[] words = value.toString().split("\t");
for (String word : words) {
// Once for each word, output as intermediate result
context.write(new Text(word), new IntWritable(1));
}
}
}This Map class is a generic type. It has four parameter types, which specify the input key, input value, output key and output value types of the map() function. LongWritable: input key type, Text: input value type, Text: output key type, IntWritable: output value type
String [] words = value. Tostring(). Split ("\ T"); the value of words is Dear River Bear River
The input key is a long integer offset, which is used to find the data in the first row and the data in the next row. The input value is a row of text Dear River Bear River, the output key is the word bear, and the output value is the integer 1.
Hadoop itself provides a set of basic types that can optimize network serialization transmission without directly using java embedded types. These types are in the org.apache.hadoop.io package. Here we use the LongWritable type (equivalent to Java's Long type), the Text type (equivalent to Java's String type), and the IntWritable type (equivalent to Java's Integer type).
The parameters of the map() method are the input key and the input value. Take this program as an example, the input key LongWritable key is an offset, and the input value Text value is Dear Car Bear Car. First, we convert the Text value containing one line of input into Java String type, and then use substring() method to extract the columns of interest. The map() method also provides Context instances for writing output content.
(2) Reducer class
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
/*
(River, 1)
(River, 1)
(River, 1)
(Spark , 1)
(Spark , 1)
(Spark , 1)
(Spark , 1)
key: River
value: List(1, 1, 1)
key: Spark
value: List(1, 1, 1,1)
*/
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
context.write(key, new IntWritable(sum));// Output final results
};
}The Reduce task initially grabs data from the Map side according to the partition number as follows:
(River, 1)
(River, 1)
(River, 1)
(spark, 1)
(Spark , 1)
(Spark , 1)
(Spark , 1)
After treatment, the results are as follows:
key: hello value: List(1, 1, 1)
key: spark value: List(1, 1, 1,1)
So the parameters iteratable & lt; intwritable & gt; values of the reduce() function receive the values List(1, 1, 1) and List(1, 1, 1,1)
(3) Main function
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountMain {
//If the MR program is executed locally in IDEA, you need to change the mapreduce.framework.name value in mapred-site.xml to local
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
if (args.length != 2 || args == null) {
System.out.println("please input Path!");
System.exit(0);
}
//System.setProperty("HADOOP_USER_NAME","hadoop2.7");
Configuration configuration = new Configuration();
//configuration.set("mapreduce.job.jar","/home/bruce/project/kkbhdp01/target/com.kaikeba.hadoop-1.0-SNAPSHOT.jar");
//Call getInstance method to generate job instance
Job job = Job.getInstance(configuration, WordCountMain.class.getSimpleName());
// jar bag
job.setJarByClass(WordCountMain.class);
// Set input / output format through job
// The default input format of MR is TextInputFormat, so the next two lines can be commented out
// job.setInputFormatClass(TextInputFormat.class);
// job.setOutputFormatClass(TextOutputFormat.class);
// Set input / output path
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// Set the class to process the Map/Reduce phase
job.setMapperClass(WordCountMap.class);
//map combine reduces network outgoing traffic
job.setCombinerClass(WordCountReduce.class);
job.setReducerClass(WordCountReduce.class);
//If the output kv pair types of map and reduce are the same, just set the output kv pair of reduce directly; if not, you need to set the output kv type of map and reduce respectively
//job.setMapOutputKeyClass(.class)
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(IntWritable.class);
// Set the type of key/value of the final output of reduce task
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// Submit homework
job.waitForCompletion(true);
}
}2 local operation
First, change the mapred-site.xml file configuration
Set the value of mapreduce.framework.name to local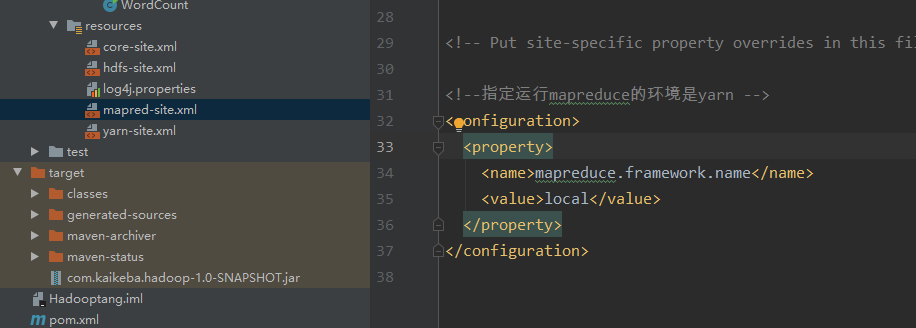
Then run locally: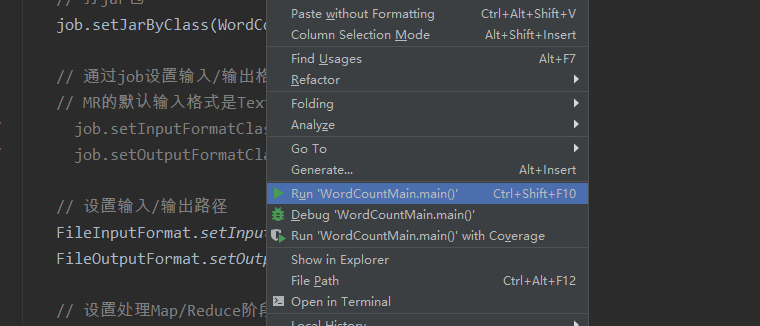
View results: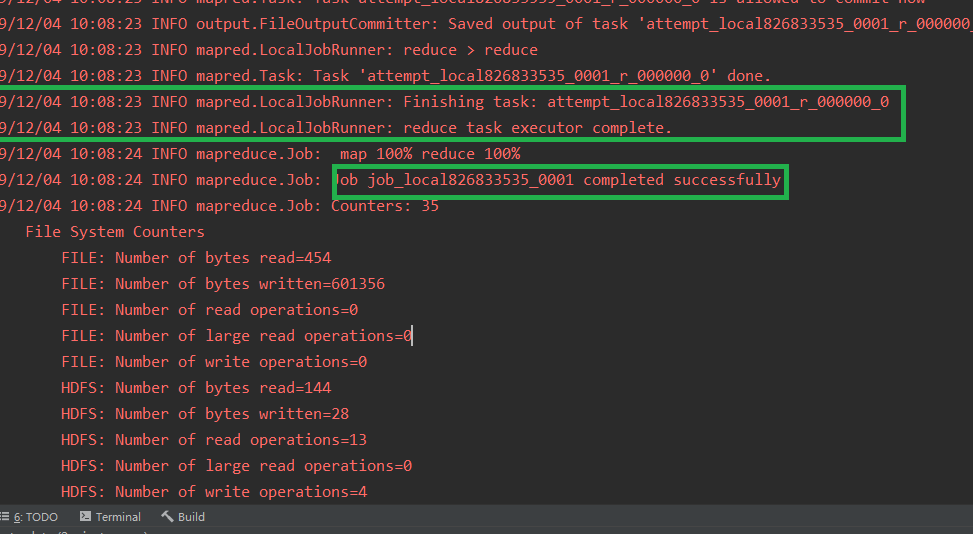
3 cluster operation
Method 1:
First packaging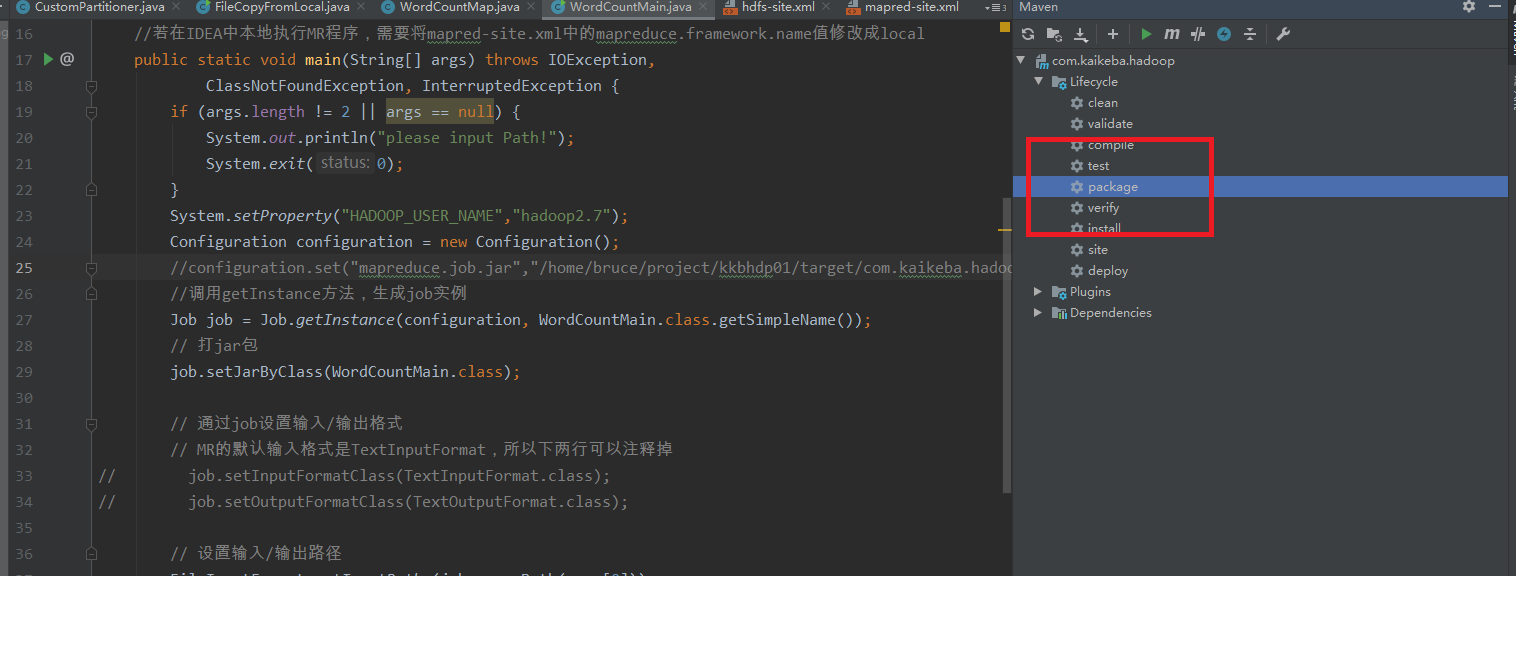
Change the configuration file to yarn mode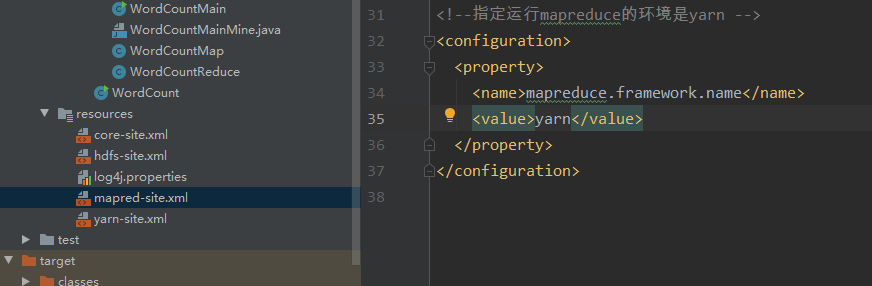
Add local jar package location:
Configuration configuration = new Configuration();
configuration.set("mapreduce.job.jar","C:\\Users\\tanglei1\\IdeaProjects\\Hadooptang\\target");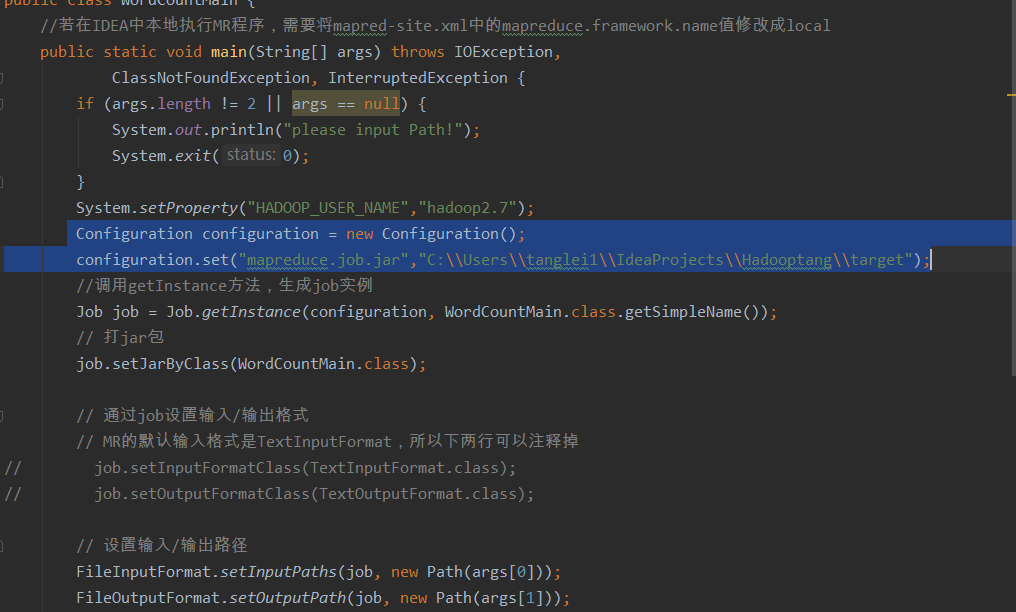
Set to allow cross platform remote calls:
configuration.set("mapreduce.app-submission.cross-platform","true");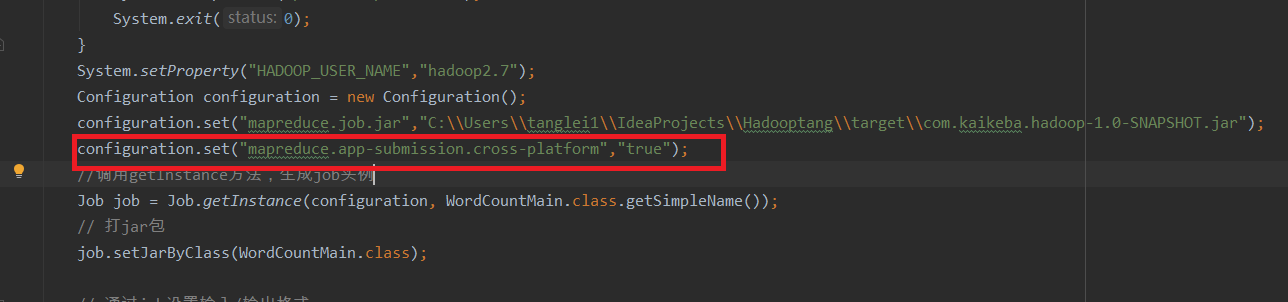
Modify input parameters: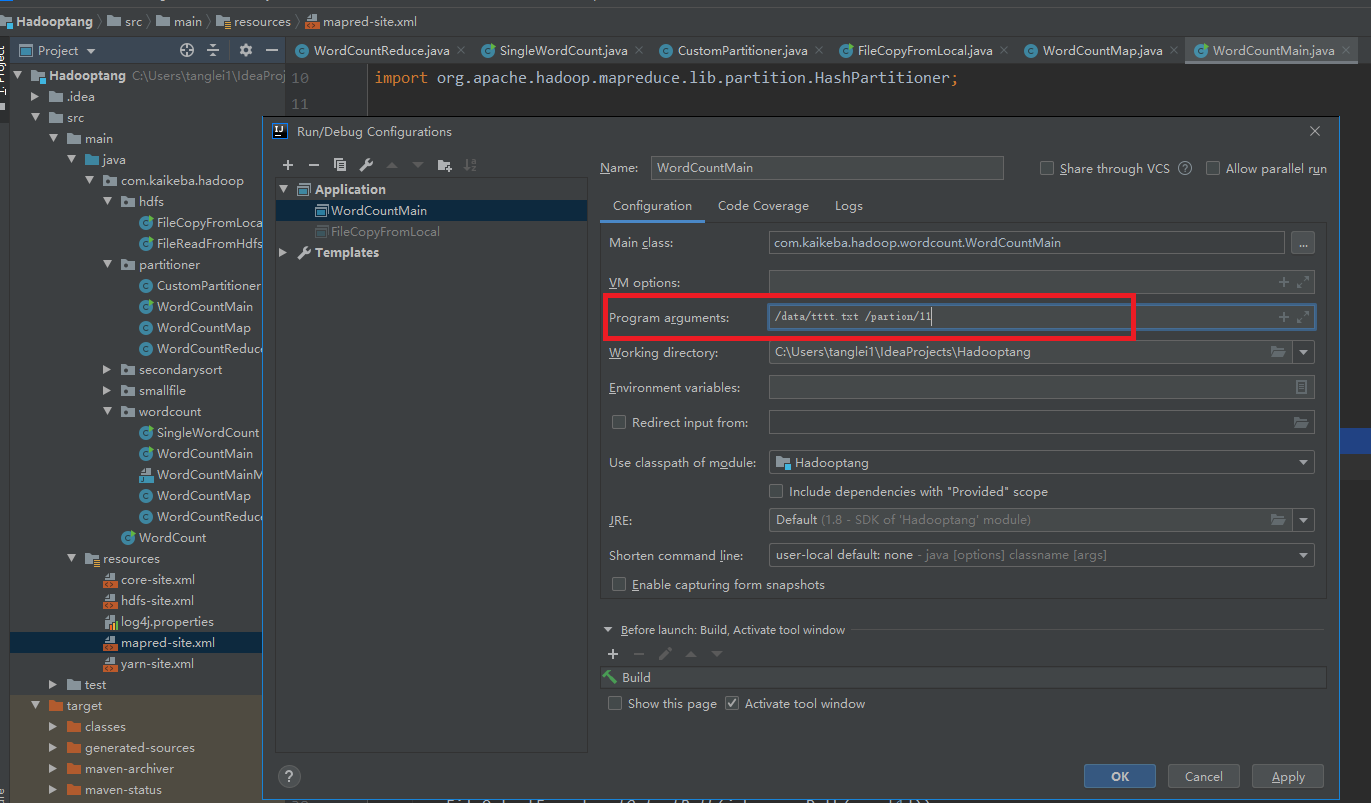
Operation result:
Mode two:
Pack maven project and run mr program with command on the server side
hadoop jar com.kaikeba.hadoop-1.0-SNAPSHOT.jar com.kaikeba.hadoop.wordcount.WordCountMain /tttt.txt /wordcount11