Third operation
1, Job content
-
Operation ①:
-
Requirements: specify a website and crawl all the pictures in the website, such as China Meteorological Network( http://www.weather.com.cn ). Single thread and multi thread crawling are used respectively. (the number of crawling pictures is limited to the last 3 digits of the student number)
-
Output information:
Output the downloaded Url information on the console, store the downloaded image in the result subfolder, and give a screenshot.
-
Single thread implementation process:
① BeautifulSoup parsing page:
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"} req = urllib.request.Request(url, headers=headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "lxml")② Functions for page turning:
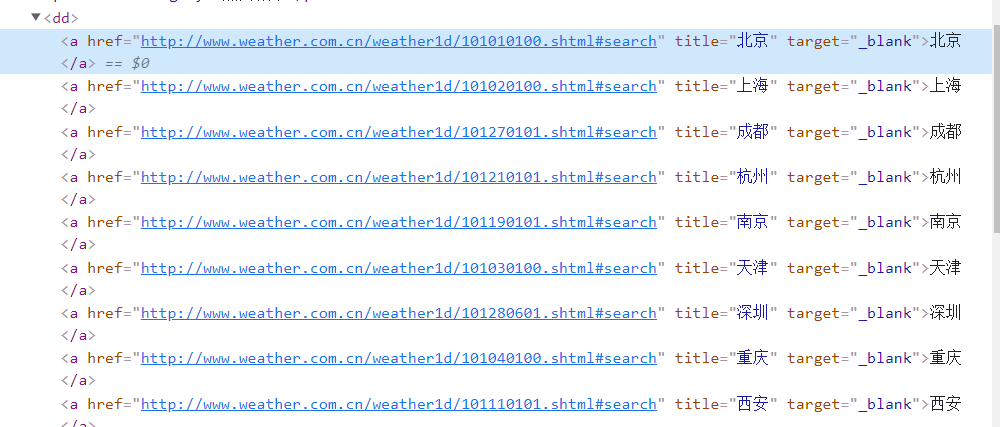
As can be seen from the above figure, the city information can be stored in the dd a node in the form of a list
def getNextPage(data, num): # Page turning processing urls = [] # Save the url of the city citys = [] # Save city name for i in range(num): city = data.select("dd a")[i].text # City name found url = data.select("dd a")[i]["href"] # Find the url to jump to the city page citys.append(city) urls.append(url) return citys, urls③ Functions to store pictures:
''' Function: save picture to local Parameter Description: url : Web address path : Storage path ''' def save(path, url): try: r = requests.get(url) f = open(path, 'wb') f.write(r.content) f.close() except Exception as err: print(err)④ Main function:
Url = "http://www.weather.com.cn "# home page data = getHTMLText(Url) num = 11 citys, urls = getNextPage(data, num) # urls stores urls that jump to individual city pages count = 1 if count <= 425: # The mantissa of the student number is 425, so 425 are taken for i in range(len(urls)): # Traverse each page url = urls[i] city = citys[i] print("Crawling" + str(city) + "Weather information related pictures") data = getHTMLText(url) images = data.select("img") # Extract the information containing the picture url and return a list for j in range(len(images)): # For each picture u image_url = images[j]["src"] # src extract url print(image_url) # url to print the picture file = r"E:/PycharmProjects/DataCollecction/test/3/1.1_result/" + str(count) + r".jpg" # Storage path save(file, image_url) count += 1 # count plus one print("Total crawling%d Picture"%count)⑤ Result display:
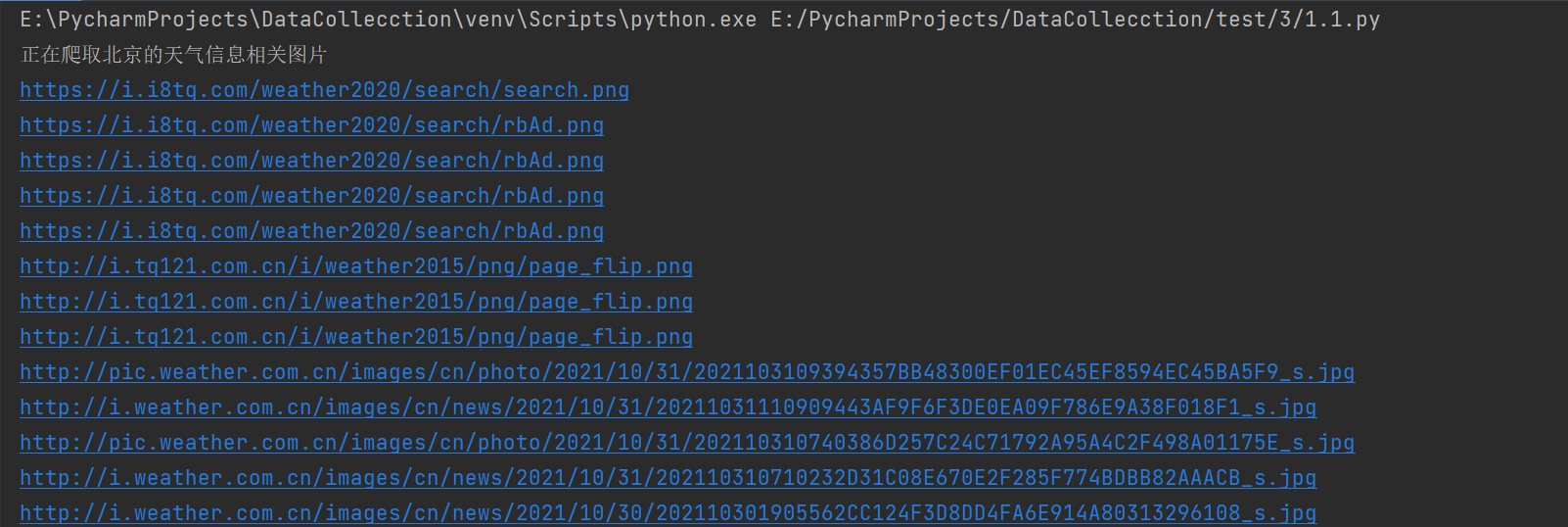
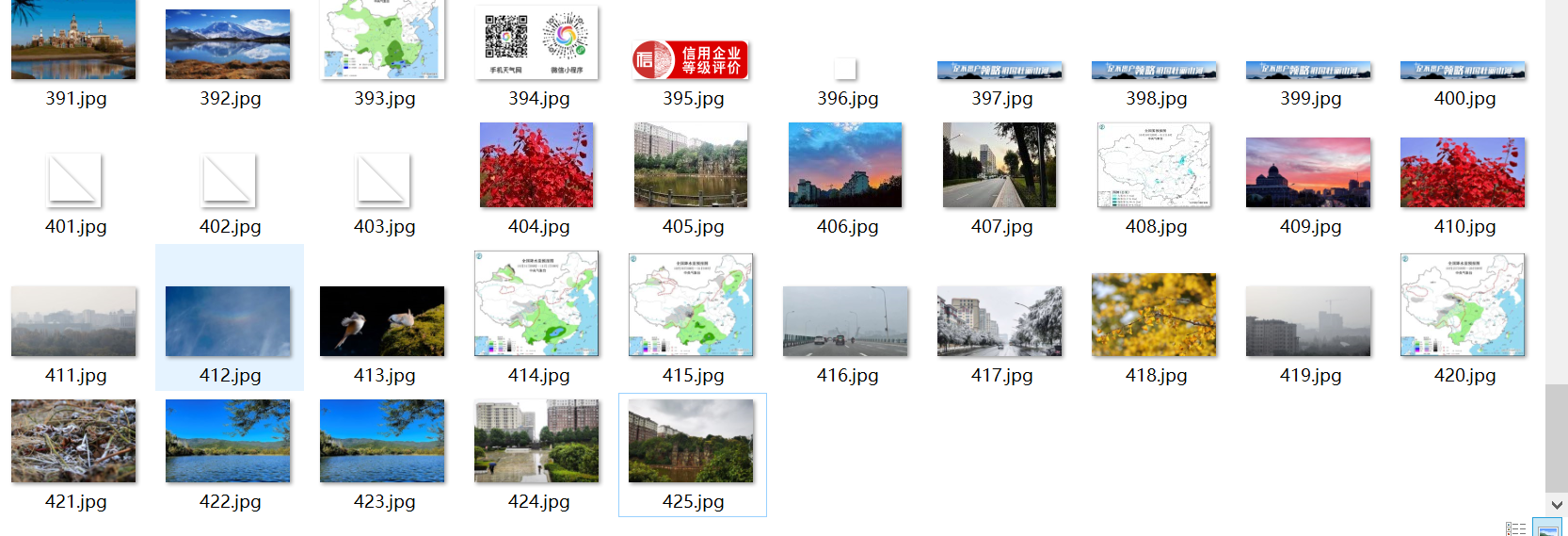
-
Multithreading implementation process:
① imageSpider function:
def imageSpider(start_url): global threads global count try: urls = [] req = urllib.request.Request(start_url, headers=headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "lxml") images = soup.select("img") # Extract the information containing the picture url and return a list for image in images: try: src = image["src"] # src extract url url = urllib.request.urljoin(start_url, src) if url not in urls: print(url) count = count + 1 T = threading.Thread(target=download, args=(url, count)) T.setDaemon(False) T.start() threads.append(T) except Exception as err: print(err) except Exception as err: print(err)② download function:
def download(url,count): try: if(url[len(url)-4]=="."): ext = url[len(url)-4:] else: ext = "" req = urllib.request.Request(url, headers=headers) data = urllib.request.urlopen(req, timeout=100) data = data.read() fobj = open("E:/PycharmProjects/DataCollecction/test/3/1.2_result/"+str(count)+ext, "wb") # Path and picture name fobj.write(data) fobj.close() print("downloaded "+str(count)+ext) except Exception as err: print(err)③ Main function:
start_url = "http://www.weather.com.cn "# home page # Set request header headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"} count=0 # Number of crawled pictures req = urllib.request.Request(start_url, headers=headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "lxml") num = 11 citys = soup.select("dd a") urls = soup.select("dd a") threads=[] for i in range(len(urls)): if count > 425: break else: url = urls[i]["href"] city = citys[i].text print("Crawling" + str(city) + "Weather information related pictures") imageSpider(url) for t in threads: t.join() print("The End")④ Result display:
Because it is multithreaded, the downloaded pictures are not in the crawling order
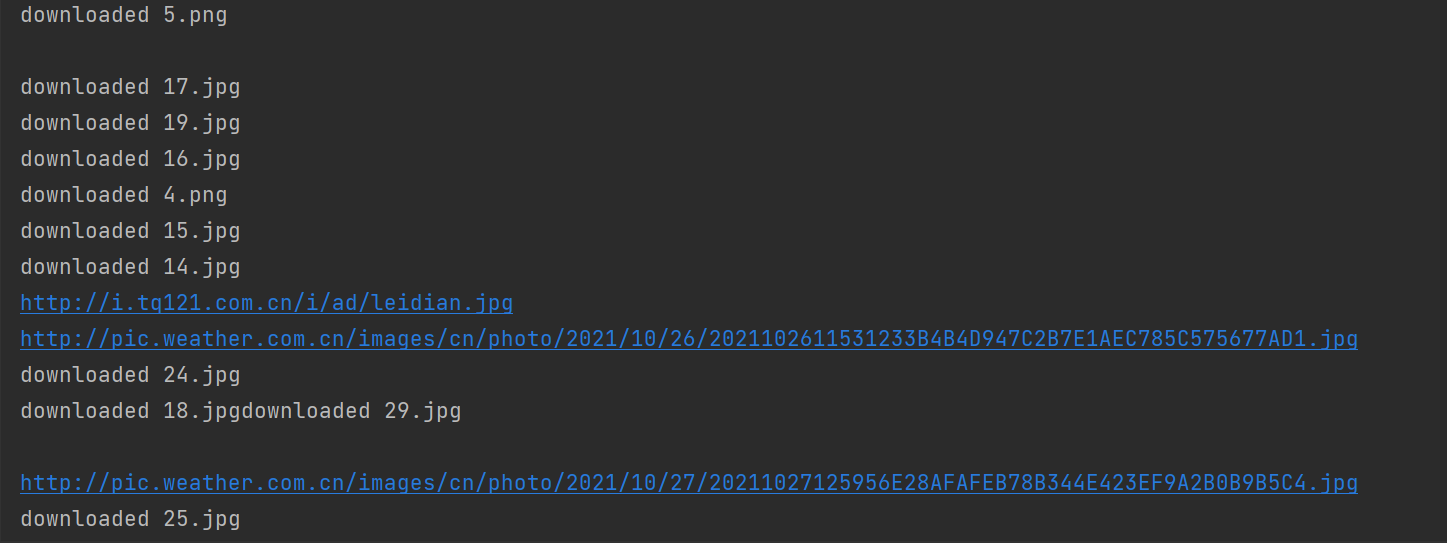
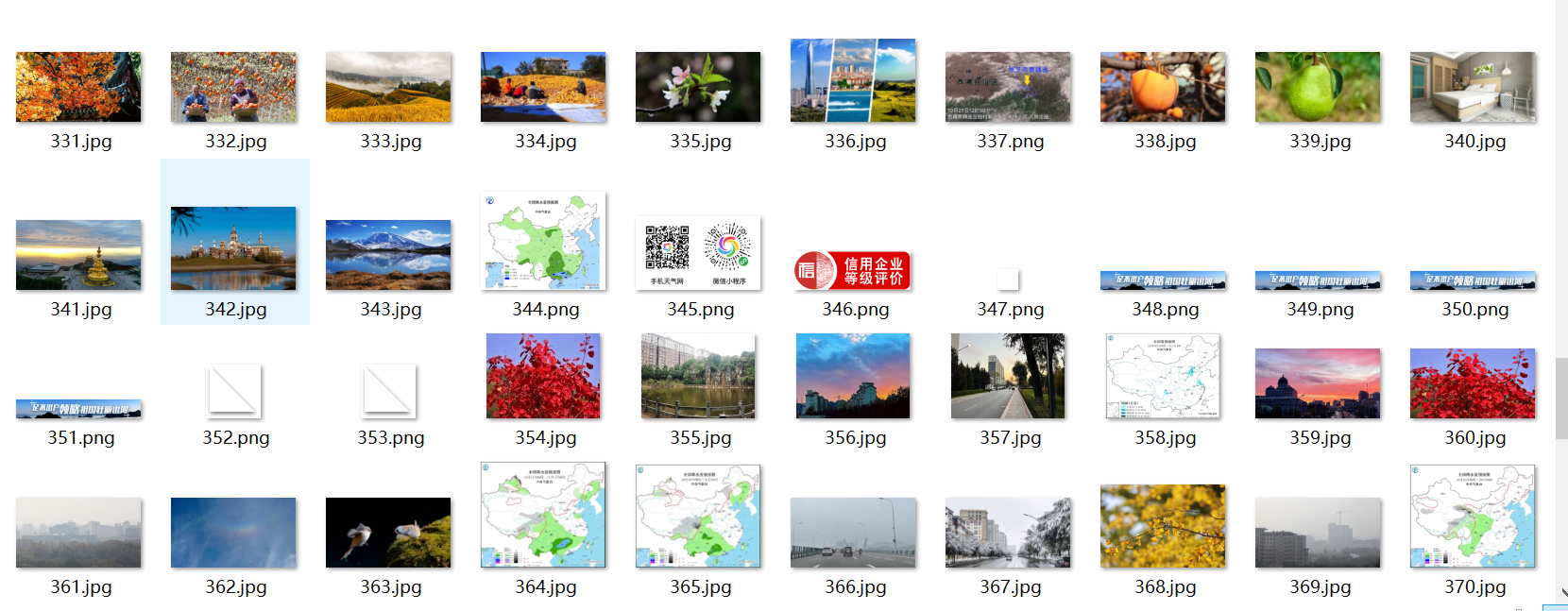
-
-
-
Operation ②
-
Requirements: use the sketch framework to reproduce the operation ①.
-
Output information:
Same as operation ①
-
Implementation process:
① items.py:
import scrapy class Demo2Item(scrapy.Item): img_url = scrapy.Field() # url used to store pictures pass② piplines.py: (the storage function of job ① plays the same role)
import urllib class Demo2Pipeline: count = 0 def process_item(self, item, spider): try: for url in item["img_url"]: print(url) if (url[len(url) - 4] == "."): ext = url[len(url) - 4:] else: ext = "" req = urllib.request.Request(url) data = urllib.request.urlopen(req, timeout=100) data = data.read() fobj = open("E:/PycharmProjects/DataCollecction/test/3/demo_2/result/" + str(Demo2Pipeline.count) + ext, "wb") fobj.write(data) fobj.close() print("downloaded " + str(Demo2Pipeline.count) + ext) Demo2Pipeline.count += 1 except Exception as err: print(err) return item③ setting.py
DEFAULT_REQUEST_HEADERS = { # Set request header 'accept': 'image/webp,*/*;q=0.8', 'accept-language': 'zh-CN,zh;q=0.8', 'referer': 'http://www.weather.com.cn', 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36" }④ Myspider.py (the main function of job ① plays the same role as crawling image information)
Picture information:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"]) data = dammit.unicode_markup selector = scrapy.Selector(text=data) img_url = selector.xpath("//img/@src").extract() MySpider.count += len(img_url) item = Demo2Item() item["img_url"] = img_url yield item Page turning processing:
if MySpider.count <= 425: url = selector.xpath("//dd/a/@href").extract()[MySpider.page] # get the url of the next page city = selector.xpath("//dd/a/text()").extract()[MySpider.page] print("Crawling" + str(city) + "Weather information related pictures") yield scrapy.Request(url=url, callback=self.parse) # Callback function page turning MySpider.page += 1 # Update page number⑤ Result display:

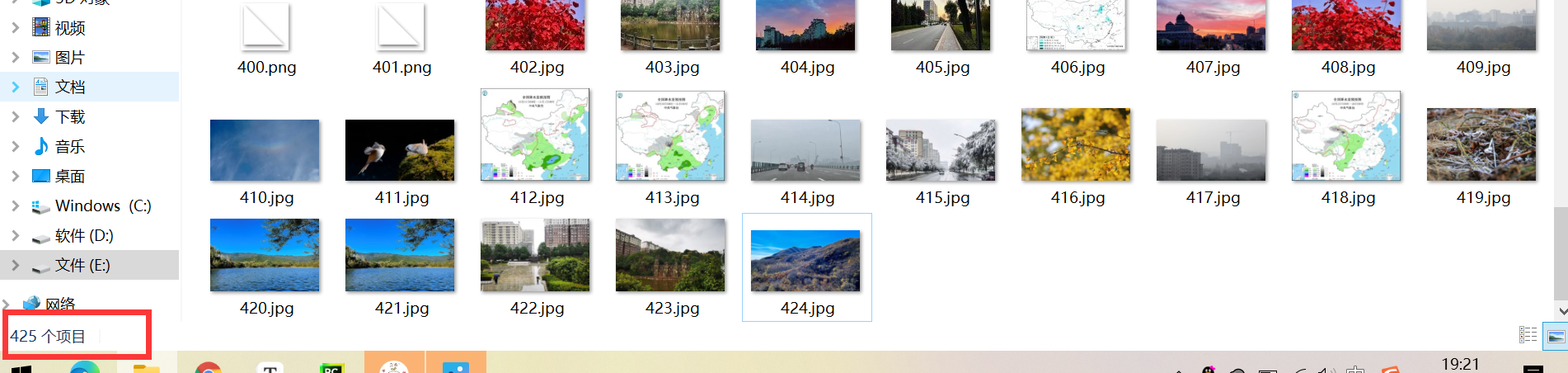
-
experience:
-
-
-
Operation ③:
-
Requirements: crawl the Douban movie data, use scene and xpath, store the content in the database, and store the pictures in the imgs path.
-
Candidate sites: https://movie.douban.com/top250
-
Output information:
Serial number Movie title director performer brief introduction Film rating Film cover 1 The Shawshank Redemption Frank delabond Tim Robbins Want to set people free 9.7 ./imgs/xsk.jpg 2.... -
Implementation process:
① items.py:
import scrapy class Demo3Item(scrapy.Item): num = scrapy.Field() # Serial number name = scrapy.Field() # Movie title director = scrapy.Field() # director actor = scrapy.Field() # performer introduction = scrapy.Field() # brief introduction score = scrapy.Field() # Film rating cover = scrapy.Field() # Movie cover url pass② piplines.py:
Store information in the database:
def open_spider(self, spider): print("opened") try: self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="qwe1346790", db="mydb", charset="utf8") self.cursor = self.con.cursor(pymysql.cursors.DictCursor) self.cursor.execute("delete from movies") self.opened = True self.count = 0 except Exception as err: print(err) self.opened = False def close_spider(self, spider): if self.opened: self.con.commit() self.con.close() self.opened = False print("closed") print("Total crawling", self.count, "Movie information") def process_item(self, item, spider): try: print("Serial number: ", end="") print(item["num"]) # Print movie serial number print("Movie Title: ", end="") print(item["name"]) # Print movie name print("Director: ", end="") print(item["director"]) # Print film director print("Actors: ", end="") print(item["actor"]) # Print actor print("Introduction: ", end="") print(item["introduction"]) # Print introduction print("Movie rating: ", end="") print(item["score"]) # Print movie ratings print("Film cover: ", end="") print(item["cover"]) # Print movie cover print() if self.opened: self.cursor.execute("insert into movies (num, name, director, actor, introduction, score, cover) values( % s, % s, % s, % s, % s, % s, % s)" , (item["num"], item["name"], item["director"], item["actor"], item["introduction"], item["score"], item["cover"],)) self.count += 1 Save picture locally:
def process_item(self, item, spider): try: url = item["cover"] req = urllib.request.Request(url) data = urllib.request.urlopen(req, timeout=100) data = data.read() fobj = open("E:/PycharmProjects/DataCollecction/test/3/demo_3/result/" + str(self.count) + ".jpg", "wb") fobj.write(data) fobj.close() print("downloaded " + str(self.count) + ".jpg") self.count += 1③ setting.py:
ITEM_PIPELINES = { 'demo_3.pipelines.Demo3Pipeline': 300, } DEFAULT_REQUEST_HEADERS = { # Set request header 'accept': 'image/webp,*/*;q=0.8', 'accept-language': 'zh-CN,zh;q=0.8', 'referer': 'https://movie.douban.com/top250', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36', 'Cookie': 'll="108300"; bid=suhTDj9VAic; douban-fav-remind=1; __gads=ID=91b3b86e72bb1bdc-22f833a798cb00ff:T=1631273458:RT=1631273458:S=ALNI_Mb_chXR7p5DDTuCl3S6BX87GbcBTw; viewed="4006425"; gr_user_id=125cd979-ed5d-41e6-9bb0-f4e248d2faab; __utmz=30149280.1631273897.1.1.utmcsr=edu.cnblogs.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmz=223695111.1635338543.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmc=30149280; __utmc=223695111; _pk_ses.100001.4cf6=*; __utma=30149280.2089450980.1631273897.1635427621.1635435215.5; __utmb=30149280.0.10.1635435215; __utma=223695111.1984107456.1635338543.1635427621.1635435215.4; __utmb=223695111.0.10.1635435215; ap_v=0,6.0; _pk_id.100001.4cf6=251801600b05f8b9.1635338543.4.1635437309.1635429350.', }④ MySpider.py:
def start_requests(self): url = MySpider.source_url # URL of the first page yield scrapy.Request(url=url, callback=self.parse) # Callback to next function Parse page:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"]) data = dammit.unicode_markup selector = scrapy.Selector(text=data)
Locate the node where the movie is stored:
lis = selector.xpath("//ol[@class='grid_view']/li ") # find the node where the movie information is stored Find the information we want in each node:
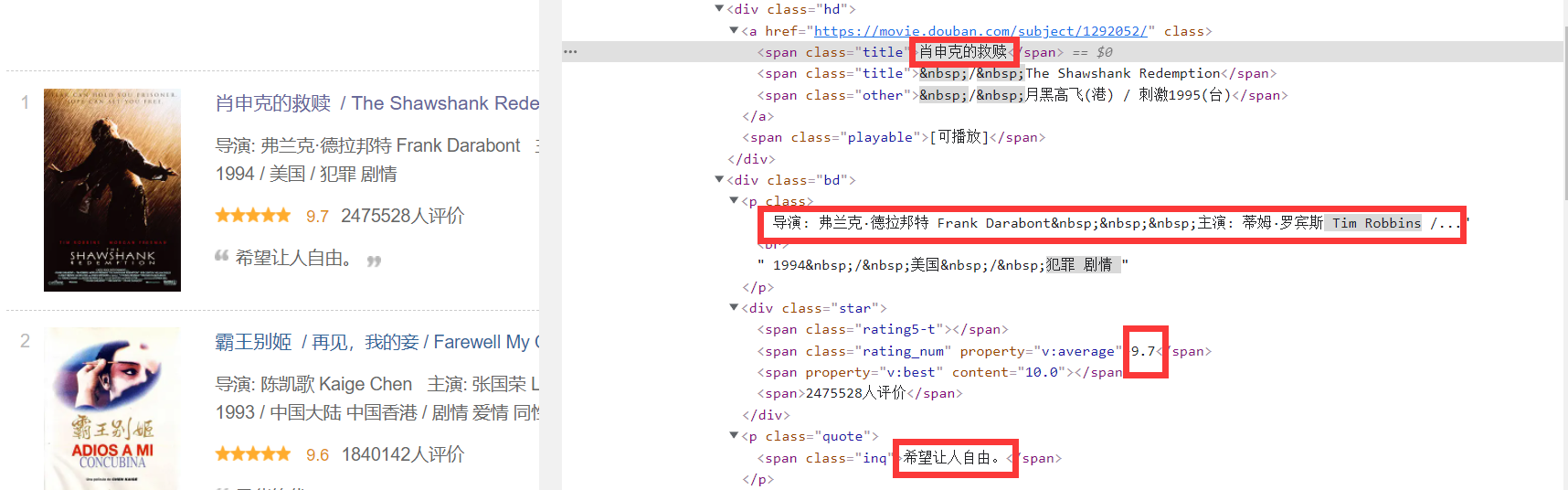
for li in lis: num = li.xpath("./div[@class='item']/div[@class='pic']/em/text()").extract_first() # Serial number name = li.xpath("./div[@class='item']/div[@class='pic']/a/img/@alt").extract_first() # Movie title # Contains starring and directing information source = li.xpath("./div[@class='item']/div[@class='info']/div[@class='bd']/p[@class='']/text()").extract_first() if len(source.split(':')) > 2: # Separated by: when the separated unit is greater than 2, the starring content cannot be empty director = source.split(':')[1].split('to star')[0].split(' ')[1].strip() # Extract director information actor = source.split(':')[2].split('/')[0].split(' ')[1].strip() # Extract starring information else: # Separated by: when the separated unit is less than or equal to 2, the starring content is empty director = source.split(':')[1].split('/')[0].split(' ')[1].strip() actor = ' ' # brief introduction introduction = li.xpath("./div[@class='item']/div[@class='info']/div[@class='bd']/p[@class='quote']/span/text()").extract_first() # score score = li.xpath("./div[@class='item']/div[@class='info']/div[@class='bd']/div[@class='star']/span[@class='rating_num']/text()").extract_first() # url of the cover image cover = li.xpath("./div[@class='item']/div[@class='pic']/a/img/@src").extract_first() item = Demo3Item() # Import data into items item["num"] = num item["name"] = name item["director"] = director item["actor"] = actor item["introduction"] = introduction item["score"] = score item["cover"] = cover yield item MySpider.count += 1 Page turning processing:
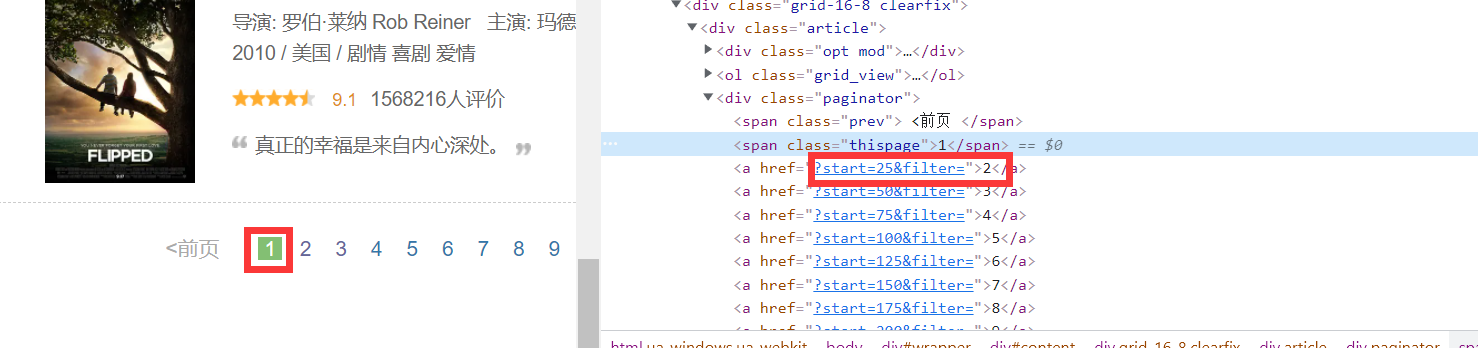

As can be seen from the above figure, the hrefl + home page url on the next page can get the complete url:
next_link = selector.xpath("//div[@class='article']/div[@class='paginator']/a/@href").extract() # next_url = MySpider.source_url + next_link[MySpider.page - 1] if MySpider.page < 5: print("I'm climbing the third floor now" + str(MySpider.page) + "page.......") print(next_url) yield scrapy.Request(url=next_url, callback=self.parse) # Callback function page turning MySpider.page += 1 # Update page number -
Experience*
In assignment 3, the main problem is that the director and starring information exist in a text, and the string needs to be segmented:
We first use the xpath method to find the string containing this text: (code implementation)
source = li.xpath("./div[@class='item']/div[@class='info']/div[@class='bd']/p[@class='']/text()").extract_first()Look again, for some movies, there are stars, while some movies don't
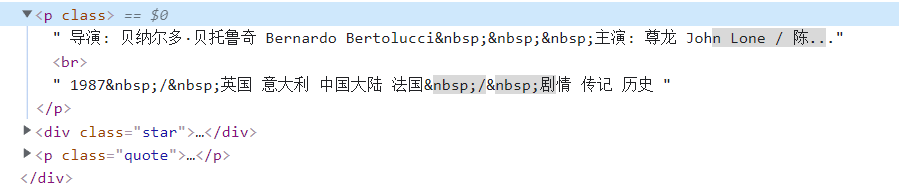

Therefore, we need to deal with the details:
Use source.split(':') to segment the source. For movies with starring stars, the number of segments after segmentation is greater than 2, while for movies without starring stars, the number of segments after segmentation is less than or equal to 2;
if len(source.split(':')) > 2: # Separated by: when the separated unit is greater than 2, the starring content cannot be empty director = source.split(':')[1].split('to star')[0].split(' ')[1].strip() # Extract director information actor = source.split(':')[2].split('/')[0].split(' ')[1].strip() # Extract starring information else: # Separated by: when the separated unit is less than or equal to 2, the starring content is empty director = source.split(':')[1].split('/')[0].split(' ')[1].strip() actor = ' 'Note: split ('' ') [1] is to separate English name from Chinese name and output Chinese name
Attached: Full code link
-
-