Flink execution plan level 1 - StreamTransformation The structure of list + linked list is constructed;
Flink execution plan layer 2 - StreamGraph Transform the first layer into a graph structure;
Next, it's time to convert StreamGraph to JobGraph. StreamGraph inherits the abstract class StreamingPlan and implements the getJobGraph method:
/**
* Gets the assembled {@link JobGraph} with a given job id.
*/
@SuppressWarnings("deprecation")
@Override
public JobGraph getJobGraph(@Nullable JobID jobID) {
// temporarily forbid checkpointing for iterative jobs
if (isIterative() && checkpointConfig.isCheckpointingEnabled() && !checkpointConfig.isForceCheckpointing()) {
throw new UnsupportedOperationException(
"Checkpointing is currently not supported by default for iterative jobs, as we cannot guarantee exactly once semantics. "
+ "State checkpoints happen normally, but records in-transit during the snapshot will be lost upon failure. "
+ "\nThe user can force enable state checkpoints with the reduced guarantees by calling: env.enableCheckpointing(interval,true)");
}
return StreamingJobGraphGenerator.createJobGraph(this, jobID);
}
1, StreamingJobGraphGenerator
Code to track createJobGraph:
private JobGraph createJobGraph() {
// make sure that all vertices start immediately
jobGraph.setScheduleMode(ScheduleMode.EAGER);
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
// Defaultthe current instance object of streamgraphhasher is StreamGraphHasherV2
// A Hash value is generated for each node in the StreamGraph
// When each node calculates the hash, it will take the hash of the node of the input node to participate in the calculation
Map<Integer, byte[]> hashes = defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
// The current legacy version of Hash algorithm implementation class is StreamGraphUserHashHasher
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
Map<Integer, List<Tuple2<byte[], byte[]>>> chainedOperatorHashes = new HashMap<>();
setChaining(hashes, legacyHashes, chainedOperatorHashes);
setPhysicalEdges();
setSlotSharingAndCoLocation();
configureCheckpointing();
JobGraphGenerator.addUserArtifactEntries(streamGraph.getEnvironment().getCachedFiles(), jobGraph);
// set the ExecutionConfig last when it has been finalized
try {
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
}
catch (IOException e) {
throw new IllegalConfigurationException("Could not serialize the ExecutionConfig." +
"This indicates that non-serializable types (like custom serializers) were registered");
}
return jobGraph;
}
Traversing the StreamGraph and generating hash values for each node is mainly used for integrity verification, which is not discussed in detail in this paper. Next, look at other important methods.
2.1 setChaining
Tracking setChaining source code
/**
* Sets up task chains from the source {@link StreamNode} instances.
*
* <p>This will recursively create all {@link JobVertex} instances.
*/
private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes, Map<Integer, List<Tuple2<byte[], byte[]>>> chainedOperatorHashes) {
// getSourceIDs() will get the collection of data source node ID s added to the StreamGraph by the StreamGraph.addSource method
for (Integer sourceNodeId : streamGraph.getSourceIDs()) {
// Next, createChain will be called recursively to create a JobVertex instance
// At present, there are values in hashes, legacyHashes is empty, chainedOperatorHashes is also empty temporarily, but it will be filled in during recursion
createChain(sourceNodeId, sourceNodeId, hashes, legacyHashes, 0, chainedOperatorHashes);
}
}
Continue to track the code for createChain:
private List<StreamEdge> createChain(
Integer startNodeId,
Integer currentNodeId,
Map<Integer, byte[]> hashes,
List<Map<Integer, byte[]>> legacyHashes,
int chainIndex,
Map<Integer, List<Tuple2<byte[], byte[]>>> chainedOperatorHashes) {
// This judgment is to avoid duplicate creation of JobVertex
if (!builtVertices.contains(startNodeId)) {
List<StreamEdge> transitiveOutEdges = new ArrayList<StreamEdge>();
List<StreamEdge> chainableOutputs = new ArrayList<StreamEdge>();
List<StreamEdge> nonChainableOutputs = new ArrayList<StreamEdge>();
// The outEdges of the current StreamNode are divided into "linkable" and "unlinkable", which will be analyzed later
// If there is no outEdges, such as the "final" node, createChain will not be called recursively
for (StreamEdge outEdge : streamGraph.getStreamNode(currentNodeId).getOutEdges()) {
if (isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}
for (StreamEdge chainable : chainableOutputs) {
// Recursive call to createChain
transitiveOutEdges.addAll(
createChain(startNodeId, chainable.getTargetId(), hashes, legacyHashes, chainIndex + 1, chainedOperatorHashes));
}
for (StreamEdge nonChainable : nonChainableOutputs) {
transitiveOutEdges.add(nonChainable);
// Recursive call to createChain
createChain(nonChainable.getTargetId(), nonChainable.getTargetId(), hashes, legacyHashes, 0, chainedOperatorHashes);
}
List<Tuple2<byte[], byte[]>> operatorHashes =
chainedOperatorHashes.computeIfAbsent(startNodeId, k -> new ArrayList<>());
byte[] primaryHashBytes = hashes.get(currentNodeId);
for (Map<Integer, byte[]> legacyHash : legacyHashes) {
operatorHashes.add(new Tuple2<>(primaryHashBytes, legacyHash.get(currentNodeId)));
}
chainedNames.put(currentNodeId, createChainedName(currentNodeId, chainableOutputs));
chainedMinResources.put(currentNodeId, createChainedMinResources(currentNodeId, chainableOutputs));
chainedPreferredResources.put(currentNodeId, createChainedPreferredResources(currentNodeId, chainableOutputs));
// If startNodeId is equal to currentNodeId, create a JobVertex and add it to the JobGraph, and then return the StreamConfig object; Otherwise, an empty StreamConfig object is returned
StreamConfig config = currentNodeId.equals(startNodeId)
? createJobVertex(startNodeId, hashes, legacyHashes, chainedOperatorHashes)
: new StreamConfig(new Configuration());
// Before setVertexConfig is executed, config is an object that has just been created but not set.
setVertexConfig(currentNodeId, config, chainableOutputs, nonChainableOutputs);
if (currentNodeId.equals(startNodeId)) {
config.setChainStart();
config.setChainIndex(0);
config.setOperatorName(streamGraph.getStreamNode(currentNodeId).getOperatorName());
config.setOutEdgesInOrder(transitiveOutEdges);
config.setOutEdges(streamGraph.getStreamNode(currentNodeId).getOutEdges());
for (StreamEdge edge : transitiveOutEdges) {
// Create JobEdge
connect(startNodeId, edge);
}
config.setTransitiveChainedTaskConfigs(chainedConfigs.get(startNodeId));
} else {
Map<Integer, StreamConfig> chainedConfs = chainedConfigs.get(startNodeId);
if (chainedConfs == null) {
chainedConfigs.put(startNodeId, new HashMap<Integer, StreamConfig>());
}
config.setChainIndex(chainIndex);
StreamNode node = streamGraph.getStreamNode(currentNodeId);
config.setOperatorName(node.getOperatorName());
chainedConfigs.get(startNodeId).put(currentNodeId, config);
}
config.setOperatorID(new OperatorID(primaryHashBytes));
if (chainableOutputs.isEmpty()) {
config.setChainEnd();
}
return transitiveOutEdges;
} else {
return new ArrayList<>();
}
}
Let's take a look at the source code of isChainable(StreamEdge, StreamGraph):
public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) {
// Upstream node of edge
StreamNode upStreamVertex = streamGraph.getSourceVertex(edge);
// Downstream node of edge
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
// Gets the StreamOperator of the upstream node
StreamOperator<?> headOperator = upStreamVertex.getOperator();
// Gets the StreamOperator of the downstream node
StreamOperator<?> outOperator = downStreamVertex.getOperator();
return downStreamVertex.getInEdges().size() == 1
&& outOperator != null
&& headOperator != null
// Check that the upstream node and downstream node are in the same SlotSharingGroup
&& upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
// The StreamOperator of the downstream node allows the StreamOperator of the front node to be linked
&& outOperator.getChainingStrategy() == ChainingStrategy.ALWAYS
// The StreamOperator of the upstream node allows the StreamOperator of the post node to be linked
&& (headOperator.getChainingStrategy() == ChainingStrategy.HEAD ||
headOperator.getChainingStrategy() == ChainingStrategy.ALWAYS)
// Direct transmission
&& (edge.getPartitioner() instanceof ForwardPartitioner)
// The parallelism of upstream and downstream nodes is equal
&& upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
// StreamGraph allows the StreamOperator link of nodes in the graph
&& streamGraph.isChainingEnabled();
}
Among them, what I don't understand most is the use of this ChainingStrategy? So look at the source code:
/**
* Defines the chaining scheme for the operator. When an operator is chained to the
* predecessor, it means that they run in the same thread. They become one operator
* consisting of multiple steps.
* Defines the link scheme for the StreamOperator.
* When operators are linked to the predecessor operator, this means that they run in the same thread.
* They become an operator composed of multiple steps.
*
* <p>The default value used by the {@link StreamOperator} is {@link #HEAD}, which means that
* the operator is not chained to its predecessor. Most operators override this with
* {@link #ALWAYS}, meaning they will be chained to predecessors whenever possible.
*/
@PublicEvolving
public enum ChainingStrategy {
/**
* Operators will be eagerly chained whenever possible.
* Link now
*
* <p>To optimize performance, it is generally a good practice to allow maximal
* chaining and increase operator parallelism.
*/
ALWAYS,
/**
* The operator will not be chained to the preceding or succeeding operators.
* Not linked to pre - or post operator s
*/
NEVER,
/**
* The operator will not be chained to the predecessor, but successors may chain to this
* operator.
* It is not linked to the front operator, but it can be linked to the rear operator
*/
HEAD
}
2.1.1 process of creating JobGraph
- After several recursive calls, it reaches the "final" node (id=5)
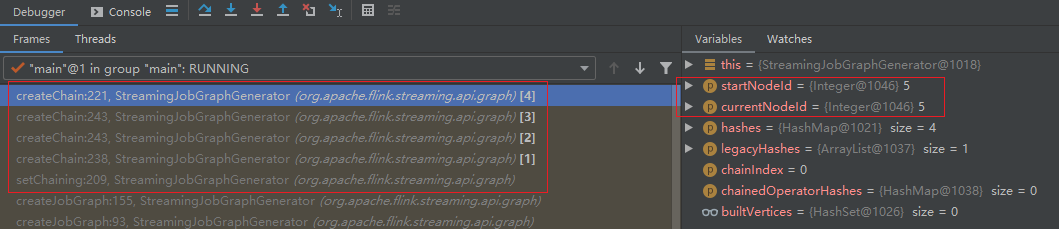
- Call createVertex, create JobVertex and add it to JobGraph:

- The method stack pops up the last createChain and executes createVertex again:

- Call connect to create JobEdge:
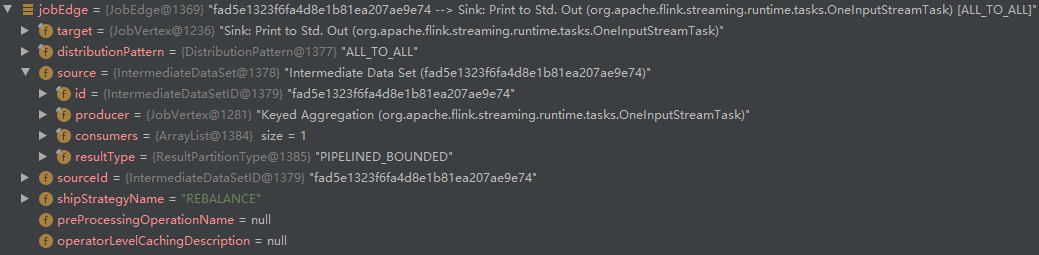
- Execute createVertex again, and "Source: Socket Stream" and "Flat Map" merge:

- Call connect again to create JobEdge:
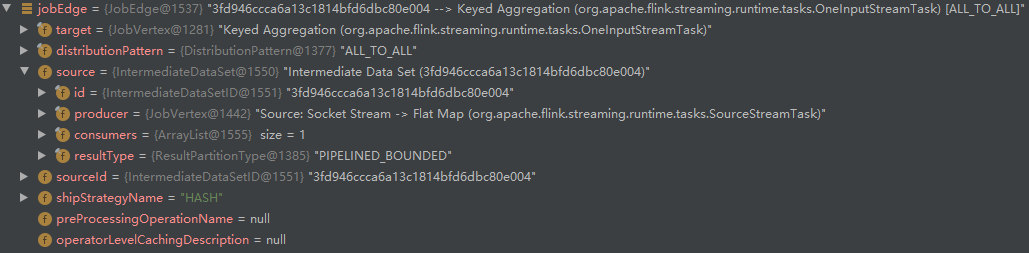
We can find that JobGraph has one fewer node than StreamGraph because the "linkable" StreamOperator is merged.
2.1.2 other questions
Question 1: how do you get the name Source: socket stream - > flat map after the combination of StreamNode (id=1) and StreamNode (id=2)?
A: the place where the name is set is the code in the createChain method:
chainedNames.put(currentNodeId, createChainedName(currentNodeId, chainableOutputs));
Track the source code of createChainedName:
private String createChainedName(Integer vertexID, List<StreamEdge> chainedOutputs) {
String operatorName = streamGraph.getStreamNode(vertexID).getOperatorName();
if (chainedOutputs.size() > 1) {
List<String> outputChainedNames = new ArrayList<>();
for (StreamEdge chainable : chainedOutputs) {
outputChainedNames.add(chainedNames.get(chainable.getTargetId()));
}
return operatorName + " -> (" + StringUtils.join(outputChainedNames, ", ") + ")";
} else if (chainedOutputs.size() == 1) {
return operatorName + " -> " + chainedNames.get(chainedOutputs.get(0).getTargetId());
} else {
return operatorName;
}
}
During debugging, it is found that the mapping of chainedNames is as follows:
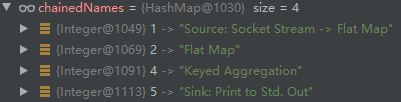
Then, in the source code of createJobVertex, the code for creating JobVertex is as follows:
jobVertex = new JobVertex(
// Query chainedNames mapping according to the id of StreamNode to determine the assignment name
chainedNames.get(streamNodeId),
jobVertexId,
legacyJobVertexIds,
chainedOperatorVertexIds,
userDefinedChainedOperatorVertexIds);
Question 2: what is the source of the property OperatorIDs in JobVertex?
First, trace the constructor of JobVertex:
public JobVertex(String name, JobVertexID primaryId, List<JobVertexID> alternativeIds, List<OperatorID> operatorIds, List<OperatorID> alternativeOperatorIds) {
(ellipsis... )
this.operatorIDs = new ArrayList();
(ellipsis... )
his.operatorIDs.addAll(operatorIds);
(ellipsis... )
}
Then trace where the constructor is called:
jobVertex = new JobVertex(
chainedNames.get(streamNodeId),
jobVertexId,
legacyJobVertexIds,
// Corresponding to the operatorIds parameter in the constructor
chainedOperatorVertexIds,
userDefinedChainedOperatorVertexIds);
Trace to createJobVertex:
List<Tuple2<byte[], byte[]>> chainedOperators = chainedOperatorHashes.get(streamNodeId);
List<OperatorID> chainedOperatorVertexIds = new ArrayList<>(); // Operator ID automatically generated by Flink
List<OperatorID> userDefinedChainedOperatorVertexIds = new ArrayList<>(); // Operator ID set by user
if (chainedOperators != null) {
for (Tuple2<byte[], byte[]> chainedOperator : chainedOperators) {
chainedOperatorVertexIds.add(new OperatorID(chainedOperator.f0));
userDefinedChainedOperatorVertexIds.add(chainedOperator.f1 != null ? new OperatorID(chainedOperator.f1) : null);
}
}
chainedOperatorHashes is the fourth parameter of createJobVertex:
List<Tuple2<byte[], byte[]>> operatorHashes =
chainedOperatorHashes.computeIfAbsent(startNodeId, k -> new ArrayList<>());
// Source hashes
byte[] primaryHashBytes = hashes.get(currentNodeId);
for (Map<Integer, byte[]> legacyHash : legacyHashes) {
operatorHashes.add(new Tuple2<>(primaryHashBytes, legacyHash.get(currentNodeId)));
}
(ellipsis...)
StreamConfig config = currentNodeId.equals(startNodeId)
// Corresponding chainedOperatorHashes
? createJobVertex(startNodeId, hashes, legacyHashes, chainedOperatorHashes)
: new StreamConfig(new Configuration());
The data source of operatorIDs is hashes, and the creation of hashes should be traced to the following code in StreamingJobGraphGenerator#createJobGraph:
Map<Integer, byte[]> hashes = defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
Question 3: when was the IntermediateDataSet created?
We set the breakpoint on the first line of the constructor of the IntermediateDataSet:
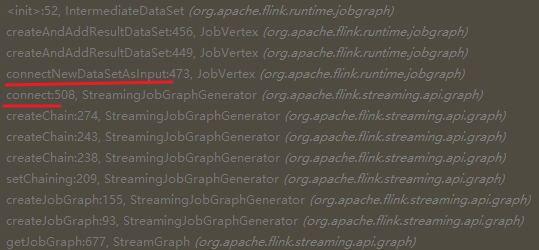
This place was ignored by me before. When the connect method creates JobEdge, it will create an IntermediateDataSet object.
2.2 physicalEdgesInOrder
Let's look back to the StreamingJobGraphGenerator#createJobGraph method to see the setPhysicalEdges executed after setChaining
private void setPhysicalEdges() {
Map<Integer, List<StreamEdge>> physicalInEdgesInOrder = new HashMap<Integer, List<StreamEdge>>();
for (StreamEdge edge : physicalEdgesInOrder) {
int target = edge.getTargetId();
List<StreamEdge> inEdges = physicalInEdgesInOrder.get(target);
// create if not set
if (inEdges == null) {
inEdges = new ArrayList<>();
physicalInEdgesInOrder.put(target, inEdges);
}
inEdges.add(edge);
}
for (Map.Entry<Integer, List<StreamEdge>> inEdges : physicalInEdgesInOrder.entrySet()) {
int vertex = inEdges.getKey();
List<StreamEdge> edgeList = inEdges.getValue();
vertexConfigs.get(vertex).setInPhysicalEdges(edgeList);
}
}
The physicalEdgesInOrder data source is from the connect method:
private void connect(Integer headOfChain, StreamEdge edge) {
physicalEdgesInOrder.add(edge);
(ellipsis...)
}
The StreamEdge corresponding to JobEdge is also saved in StreamConfig.
2.3 setSlotSharingAndCoLocation
The code continues to run, and the setSlotSharingAndCoLocation is invoked in createJobGraph. This command is well understood. Next, set up JobVertex's SlotSharingGroup and CoLocationGroup.
SlotSharingGroup: the slot sharing unit defines which different tasks (from different job vertices) can be deployed together in the slot. This is a soft permission, contrary to the hard constraint defined by the co location prompt.
Co location group: CO location group is a group of jobvertices. The ith subtask of one vertex must be executed on the same TaskManager as the ith subtask of all other job vertices in the same group. For example, use the co location group to ensure that the ith subtask at the beginning and end of the iteration is scheduled to the same TaskManager.
Refer to Flink – SlotSharingGroup[ https://www.cnblogs.com/fxjwind/p/6703312.html]
2.4 configureCheckpointing
Continue tracking the createJobGraph method configureCheckpointing:
private void configureCheckpointing() {
CheckpointConfig cfg = streamGraph.getCheckpointConfig();
long interval = cfg.getCheckpointInterval();
if (interval > 0) {
ExecutionConfig executionConfig = streamGraph.getExecutionConfig();
// propagate the expected behaviour for checkpoint errors to task.
executionConfig.setFailTaskOnCheckpointError(cfg.isFailOnCheckpointingErrors());
} else {
// interval of max value means disable periodic checkpoint
interval = Long.MAX_VALUE;
}
// --- configure the participating vertices ---
// collect the vertices that receive "trigger checkpoint" messages.
// currently, these are all the sources
List<JobVertexID> triggerVertices = new ArrayList<>();
// collect the vertices that need to acknowledge the checkpoint
// currently, these are all vertices
List<JobVertexID> ackVertices = new ArrayList<>(jobVertices.size());
// collect the vertices that receive "commit checkpoint" messages
// currently, these are all vertices
List<JobVertexID> commitVertices = new ArrayList<>(jobVertices.size());
for (JobVertex vertex : jobVertices.values()) {
if (vertex.isInputVertex()) {
triggerVertices.add(vertex.getID());
}
commitVertices.add(vertex.getID());
ackVertices.add(vertex.getID());
}
// --- configure options ---
CheckpointRetentionPolicy retentionAfterTermination;
if (cfg.isExternalizedCheckpointsEnabled()) {
CheckpointConfig.ExternalizedCheckpointCleanup cleanup = cfg.getExternalizedCheckpointCleanup();
// Sanity check
if (cleanup == null) {
throw new IllegalStateException("Externalized checkpoints enabled, but no cleanup mode configured.");
}
retentionAfterTermination = cleanup.deleteOnCancellation() ?
CheckpointRetentionPolicy.RETAIN_ON_FAILURE :
CheckpointRetentionPolicy.RETAIN_ON_CANCELLATION;
} else {
retentionAfterTermination = CheckpointRetentionPolicy.NEVER_RETAIN_AFTER_TERMINATION;
}
CheckpointingMode mode = cfg.getCheckpointingMode();
boolean isExactlyOnce;
if (mode == CheckpointingMode.EXACTLY_ONCE) {
isExactlyOnce = true;
} else if (mode == CheckpointingMode.AT_LEAST_ONCE) {
isExactlyOnce = false;
} else {
throw new IllegalStateException("Unexpected checkpointing mode. " +
"Did not expect there to be another checkpointing mode besides " +
"exactly-once or at-least-once.");
}
// --- configure the master-side checkpoint hooks ---
final ArrayList<MasterTriggerRestoreHook.Factory> hooks = new ArrayList<>();
for (StreamNode node : streamGraph.getStreamNodes()) {
StreamOperator<?> op = node.getOperator();
if (op instanceof AbstractUdfStreamOperator) {
Function f = ((AbstractUdfStreamOperator<?, ?>) op).getUserFunction();
if (f instanceof WithMasterCheckpointHook) {
hooks.add(new FunctionMasterCheckpointHookFactory((WithMasterCheckpointHook<?>) f));
}
}
}
// because the hooks can have user-defined code, they need to be stored as
// eagerly serialized values
final SerializedValue<MasterTriggerRestoreHook.Factory[]> serializedHooks;
if (hooks.isEmpty()) {
serializedHooks = null;
} else {
try {
MasterTriggerRestoreHook.Factory[] asArray =
hooks.toArray(new MasterTriggerRestoreHook.Factory[hooks.size()]);
serializedHooks = new SerializedValue<>(asArray);
}
catch (IOException e) {
throw new FlinkRuntimeException("Trigger/restore hook is not serializable", e);
}
}
// because the state backend can have user-defined code, it needs to be stored as
// eagerly serialized value
final SerializedValue<StateBackend> serializedStateBackend;
if (streamGraph.getStateBackend() == null) {
serializedStateBackend = null;
} else {
try {
serializedStateBackend =
new SerializedValue<StateBackend>(streamGraph.getStateBackend());
}
catch (IOException e) {
throw new FlinkRuntimeException("State backend is not serializable", e);
}
}
// --- done, put it all together ---
JobCheckpointingSettings settings = new JobCheckpointingSettings(
triggerVertices,
ackVertices,
commitVertices,
new CheckpointCoordinatorConfiguration(
interval,
cfg.getCheckpointTimeout(),
cfg.getMinPauseBetweenCheckpoints(),
cfg.getMaxConcurrentCheckpoints(),
retentionAfterTermination,
isExactlyOnce),
serializedStateBackend,
serializedHooks);
jobGraph.setSnapshotSettings(settings);
}
Finally, the JobCheckpointingSettings object is assembled and set in the JobGraph.