1, Localstreaminenvironment
Localstreaminenvironment is a subclass of streaminexecutionenvironment. It runs programs locally, multithreaded, and in the JVM that instantiates localstreaminenvironment.
It generates an embedded Flink cluster in the background and executes programs on the cluster.
When instantiating this environment, it uses the default parallelism (the default value is 1). The default parallelism can be set through setParallelism(int).
We usually call the env.execute() method after we finish writing Stream API. If it is executed locally, the localstreaminenvironment #execute method will be called. The first source code of the method is:
StreamGraph streamGraph = getStreamGraph(); streamGraph.setJobName(jobName);
Then continue to trace the source code of StreamExecutionEnvironment#getStreamGraph():
/**
* Getter of the {@link org.apache.flink.streaming.api.graph.StreamGraph} of the streaming job.
*
* @return The streamgraph representing the transformations
*/
@Internal
public StreamGraph getStreamGraph() {
if (transformations.size() <= 0) {
throw new IllegalStateException("No operators defined in streaming topology. Cannot execute.");
}
return StreamGraphGenerator.generate(this, transformations);
}
The source code is also very simple. The logic for generating StreamGraph is encapsulated in StreamGraphGenerator.
2, StreamGraphGenerator
After continuing to trace the code, passing the instance object of the StreamExecutionEnvironment to the StreamGraphGenerator and creating the object, the StreamGraphGenerator#generateInternal method is called:
/**
* This starts the actual transformation, beginning from the sinks.
*/
private StreamGraph generateInternal(List<StreamTransformation<?>> transformations) {
for (StreamTransformation<?> transformation: transformations) {
transform(transformation);
}
return streamGraph;
}
The transformations traversed here are saved in the previous section Flink execution plan level 1 - StreamTransformation The StreamTransformation collection generated by our Stream API code mentioned in.
2.1 transform
Next, let's trace the code of StreamGraphGenerator#transform:
/**
* Transforms one {@code StreamTransformation}.
*
* <p>This checks whether we already transformed it and exits early in that case. If not it
* delegates to one of the transformation specific methods.
*/
private Collection<Integer> transform(StreamTransformation<?> transform) {
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
LOG.debug("Transforming " + transform);
if (transform.getMaxParallelism() <= 0) {
// if the max parallelism hasn't been set, then first use the job wide max parallelism
// from the ExecutionConfig.
int globalMaxParallelismFromConfig = env.getConfig().getMaxParallelism();
if (globalMaxParallelismFromConfig > 0) {
transform.setMaxParallelism(globalMaxParallelismFromConfig);
}
}
// call at least once to trigger exceptions about MissingTypeInfo
transform.getOutputType();
Collection<Integer> transformedIds;
if (transform instanceof OneInputTransformation<?, ?>) {
transformedIds = transformOneInputTransform((OneInputTransformation<?, ?>) transform);
} else if (transform instanceof TwoInputTransformation<?, ?, ?>) {
transformedIds = transformTwoInputTransform((TwoInputTransformation<?, ?, ?>) transform);
} else if (transform instanceof SourceTransformation<?>) {
transformedIds = transformSource((SourceTransformation<?>) transform);
} else if (transform instanceof SinkTransformation<?>) {
transformedIds = transformSink((SinkTransformation<?>) transform);
} else if (transform instanceof UnionTransformation<?>) {
transformedIds = transformUnion((UnionTransformation<?>) transform);
} else if (transform instanceof SplitTransformation<?>) {
transformedIds = transformSplit((SplitTransformation<?>) transform);
} else if (transform instanceof SelectTransformation<?>) {
transformedIds = transformSelect((SelectTransformation<?>) transform);
} else if (transform instanceof FeedbackTransformation<?>) {
transformedIds = transformFeedback((FeedbackTransformation<?>) transform);
} else if (transform instanceof CoFeedbackTransformation<?>) {
transformedIds = transformCoFeedback((CoFeedbackTransformation<?>) transform);
} else if (transform instanceof PartitionTransformation<?>) {
transformedIds = transformPartition((PartitionTransformation<?>) transform);
} else if (transform instanceof SideOutputTransformation<?>) {
transformedIds = transformSideOutput((SideOutputTransformation<?>) transform);
} else {
throw new IllegalStateException("Unknown transformation: " + transform);
}
// need this check because the iterate transformation adds itself before
// transforming the feedback edges
if (!alreadyTransformed.containsKey(transform)) {
alreadyTransformed.put(transform, transformedIds);
}
if (transform.getBufferTimeout() >= 0) {
streamGraph.setBufferTimeout(transform.getId(), transform.getBufferTimeout());
}
if (transform.getUid() != null) {
streamGraph.setTransformationUID(transform.getId(), transform.getUid());
}
if (transform.getUserProvidedNodeHash() != null) {
streamGraph.setTransformationUserHash(transform.getId(), transform.getUserProvidedNodeHash());
}
if (transform.getMinResources() != null && transform.getPreferredResources() != null) {
streamGraph.setResources(transform.getId(), transform.getMinResources(), transform.getPreferredResources());
}
return transformedIds;
}
The transform method is a method that will be called recursively:
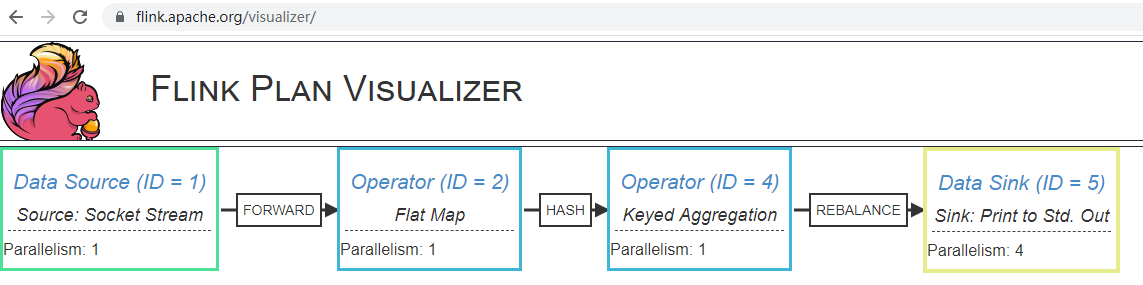
according to Getting started with Flink's first program - WordCount For example, I draw the corresponding schematic diagram:
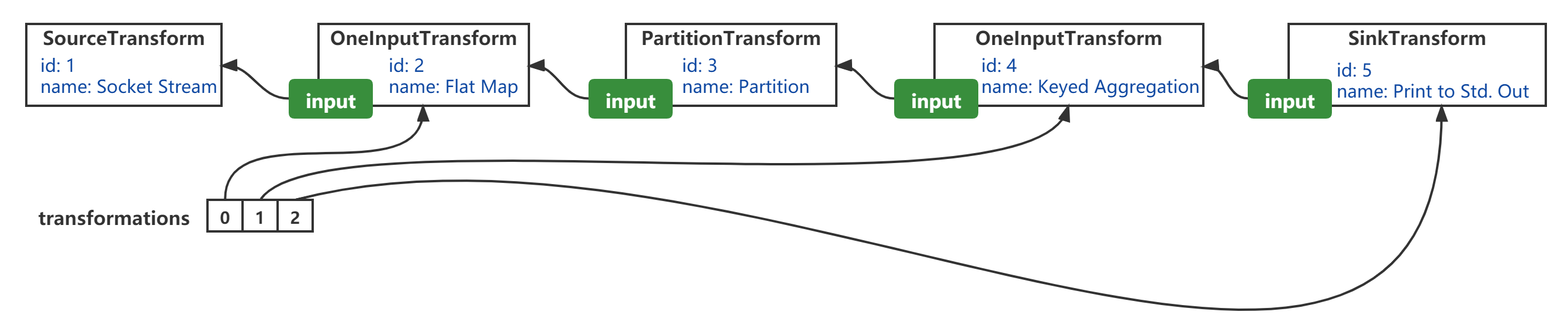
- transformations refers to the member variable of the streaminexecutionenvironment and the method parameter of streamgraphgenerator #generateinternal (list < streamtransformation <? > >);
- From the perspective of "logical order", the transformation order of the transformation method is essentially from the "reverse" of SourceTransformation along the input reference, through OneInputTransformation(id=2), PartitionTransformation, OneInputTransformation(id=4) to SinkTransformation
2.2 transformSource
Therefore, we can now look at the source code in order, so let's first look at the transformation method transformSource for SourceTransformation:
/**
* Transforms a {@code SourceTransformation}.
*/
private <T> Collection<Integer> transformSource(SourceTransformation<T> source) {
String slotSharingGroup = determineSlotSharingGroup(source.getSlotSharingGroup(), Collections.emptyList());
streamGraph.addSource(source.getId(),
slotSharingGroup,
source.getCoLocationGroupKey(),
source.getOperator(),
null,
source.getOutputType(),
"Source: " + source.getName());
if (source.getOperator().getUserFunction() instanceof InputFormatSourceFunction) {
InputFormatSourceFunction<T> fs = (InputFormatSourceFunction<T>) source.getOperator().getUserFunction();
streamGraph.setInputFormat(source.getId(), fs.getFormat());
}
streamGraph.setParallelism(source.getId(), source.getParallelism());
streamGraph.setMaxParallelism(source.getId(), source.getMaxParallelism());
return Collections.singleton(source.getId());
}
The core logic of StreamGraphGenerator#transformSource is the StreamGraph#addSource method, which will be discussed in the next section.
-
The main function of transformSource is to convert SourceTransformation into StreamNode, which is used to form StreamGraph.
-
After the implementation of the transformSource method, continue to return to the transform method and put the currently converted SourceTransformation object into the member variable alreadytransformed: Map < streamtransformation <? > Collection<Integer>> ;
2.3 transformOneInputTransform
The following is the source code of transformOneInputTransform of StreamGraphGenerator:
/**
* Transforms a {@code OneInputTransformation}.
*
* <p>This recursively transforms the inputs, creates a new {@code StreamNode} in the graph and
* wired the inputs to this new node.
*/
private <IN, OUT> Collection<Integer> transformOneInputTransform(OneInputTransformation<IN, OUT> transform) {
//
Collection<Integer> inputIds = transform(transform.getInput());
// the recursive call might have already transformed this
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
String slotSharingGroup = determineSlotSharingGroup(transform.getSlotSharingGroup(), inputIds);
streamGraph.addOperator(transform.getId(),
slotSharingGroup,
transform.getCoLocationGroupKey(),
transform.getOperator(),
transform.getInputType(),
transform.getOutputType(),
transform.getName());
if (transform.getStateKeySelector() != null) {
TypeSerializer<?> keySerializer = transform.getStateKeyType().createSerializer(env.getConfig());
streamGraph.setOneInputStateKey(transform.getId(), transform.getStateKeySelector(), keySerializer);
}
streamGraph.setParallelism(transform.getId(), transform.getParallelism());
streamGraph.setMaxParallelism(transform.getId(), transform.getMaxParallelism());
for (Integer inputId: inputIds) {
streamGraph.addEdge(inputId, transform.getId(), 0);
}
return Collections.singleton(transform.getId());
}
transformOneInputTransform calls the addOperator method of StreamGraph to create StreamNode, and also calls the addEdge method to add StreamEdge, which will be analyzed in the next section.
2.4 transformPartition
Next, let's take a look at the source code of the transformpartion of the StreamGraphGenerator:
/**
* Transforms a {@code PartitionTransformation}.
*
* <p>For this we create a virtual node in the {@code StreamGraph} that holds the partition
* property. @see StreamGraphGenerator
*/
private <T> Collection<Integer> transformPartition(PartitionTransformation<T> partition) {
StreamTransformation<T> input = partition.getInput();
List<Integer> resultIds = new ArrayList<>();
Collection<Integer> transformedIds = transform(input);
for (Integer transformedId: transformedIds) {
// Notice that a new unique id is generated here
int virtualId = StreamTransformation.getNewNodeId();
streamGraph.addVirtualPartitionNode(transformedId, virtualId, partition.getPartitioner());
resultIds.add(virtualId);
}
return resultIds;
}
transformPartition calls the addVirtualPartitionNode method of StreamGraph, which is also parsed in the next section.
2.5 transformSink
Finally, let's take a look at the source code of transformSink of StreamGraphGenerator:
/**
* Transforms a {@code SourceTransformation}.
*/
private <T> Collection<Integer> transformSink(SinkTransformation<T> sink) {
Collection<Integer> inputIds = transform(sink.getInput());
String slotSharingGroup = determineSlotSharingGroup(sink.getSlotSharingGroup(), inputIds);
streamGraph.addSink(sink.getId(),
slotSharingGroup,
sink.getCoLocationGroupKey(),
sink.getOperator(),
sink.getInput().getOutputType(),
null,
"Sink: " + sink.getName());
streamGraph.setParallelism(sink.getId(), sink.getParallelism());
streamGraph.setMaxParallelism(sink.getId(), sink.getMaxParallelism());
for (Integer inputId: inputIds) {
streamGraph.addEdge(inputId,
sink.getId(),
0
);
}
if (sink.getStateKeySelector() != null) {
TypeSerializer<?> keySerializer = sink.getStateKeyType().createSerializer(env.getConfig());
streamGraph.setOneInputStateKey(sink.getId(), sink.getStateKeySelector(), keySerializer);
}
return Collections.emptyList();
}
transformSink also calls the addSink method of StreamGraph and the addEdge method. These methods will also be parsed in the next section.
3, StreamGraph
First, the data structure of "Graph" is used here.
- The graph contains several nodes;
- The part where two nodes are connected is called Edge;
- Nodes are also called vertices;
Picture quoted from Data structure for beginners: Graph
3.1 addSource&addSink
Let's take a look at the addSource and addSink source of StreamGraph:
public <IN, OUT> void addSource(Integer vertexID,
String slotSharingGroup,
@Nullable String coLocationGroup,
StreamOperator<OUT> operatorObject,
TypeInformation<IN> inTypeInfo,
TypeInformation<OUT> outTypeInfo,
String operatorName) {
addOperator(vertexID, slotSharingGroup, coLocationGroup, operatorObject, inTypeInfo, outTypeInfo, operatorName);
sources.add(vertexID);
}
public <IN, OUT> void addSink(Integer vertexID,
String slotSharingGroup,
@Nullable String coLocationGroup,
StreamOperator<OUT> operatorObject,
TypeInformation<IN> inTypeInfo,
TypeInformation<OUT> outTypeInfo,
String operatorName) {
addOperator(vertexID, slotSharingGroup, coLocationGroup, operatorObject, inTypeInfo, outTypeInfo, operatorName);
sinks.add(vertexID);
}
- sources is used to record the id of the vertex in the graph as the "data source"
- Sins is used to record the id of the vertex in the graph as the "end point"
Both call the same method addOperator.
3.2 addOperator&&addNode
There are three calls to addOperator:

The source code is as follows:
public <IN, OUT> void addOperator(
Integer vertexID,
String slotSharingGroup,
@Nullable String coLocationGroup,
StreamOperator<OUT> operatorObject,
TypeInformation<IN> inTypeInfo,
TypeInformation<OUT> outTypeInfo,
String operatorName) {
if (operatorObject instanceof StoppableStreamSource) {
addNode(vertexID, slotSharingGroup, coLocationGroup, StoppableSourceStreamTask.class, operatorObject, operatorName);
} else if (operatorObject instanceof StreamSource) {
addNode(vertexID, slotSharingGroup, coLocationGroup, SourceStreamTask.class, operatorObject, operatorName);
} else {
addNode(vertexID, slotSharingGroup, coLocationGroup, OneInputStreamTask.class, operatorObject, operatorName);
}
TypeSerializer<IN> inSerializer = inTypeInfo != null && !(inTypeInfo instanceof MissingTypeInfo) ? inTypeInfo.createSerializer(executionConfig) : null;
TypeSerializer<OUT> outSerializer = outTypeInfo != null && !(outTypeInfo instanceof MissingTypeInfo) ? outTypeInfo.createSerializer(executionConfig) : null;
setSerializers(vertexID, inSerializer, null, outSerializer);
if (operatorObject instanceof OutputTypeConfigurable && outTypeInfo != null) {
@SuppressWarnings("unchecked")
OutputTypeConfigurable<OUT> outputTypeConfigurable = (OutputTypeConfigurable<OUT>) operatorObject;
// sets the output type which must be know at StreamGraph creation time
outputTypeConfigurable.setOutputType(outTypeInfo, executionConfig);
}
if (operatorObject instanceof InputTypeConfigurable) {
InputTypeConfigurable inputTypeConfigurable = (InputTypeConfigurable) operatorObject;
inputTypeConfigurable.setInputType(inTypeInfo, executionConfig);
}
if (LOG.isDebugEnabled()) {
LOG.debug("Vertex: {}", vertexID);
}
}
In this method, first create an addNode, and then set the node.
protected StreamNode addNode(Integer vertexID,
String slotSharingGroup,
@Nullable String coLocationGroup,
Class<? extends AbstractInvokable> vertexClass,
StreamOperator<?> operatorObject,
String operatorName) {
if (streamNodes.containsKey(vertexID)) {
throw new RuntimeException("Duplicate vertexID " + vertexID);
}
StreamNode vertex = new StreamNode(environment,
vertexID,
slotSharingGroup,
coLocationGroup,
operatorObject,
operatorName,
new ArrayList<OutputSelector<?>>(),
vertexClass);
// Vertex id map vertex object
streamNodes.put(vertexID, vertex);
return vertex;
}
3.3 addEdge
The source code of the addEdge method of StreamGraph is very simple. The main logic is in addEdgeInternal:
public void addEdge(Integer upStreamVertexID, Integer downStreamVertexID, int typeNumber) {
addEdgeInternal(upStreamVertexID,
downStreamVertexID,
typeNumber,
null,
new ArrayList<String>(),
null);
}
addEdgeInternal is a method that can be called recursively:
private void addEdgeInternal(Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner<?> partitioner,
List<String> outputNames,
OutputTag outputTag) {
if (virtualSideOutputNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSideOutputNodes.get(virtualId).f0;
if (outputTag == null) {
outputTag = virtualSideOutputNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, null, outputTag);
} else if (virtualSelectNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSelectNodes.get(virtualId).f0;
if (outputNames.isEmpty()) {
// selections that happen downstream override earlier selections
outputNames = virtualSelectNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag);
} else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtualPartitionNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag);
} else {
StreamNode upstreamNode = getStreamNode(upStreamVertexID);
StreamNode downstreamNode = getStreamNode(downStreamVertexID);
// If no partitioner was specified and the parallelism of upstream and downstream
// operator matches use forward partitioning, use rebalance otherwise.
if (partitioner == null && upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner = new ForwardPartitioner<Object>();
} else if (partitioner == null) {
partitioner = new RebalancePartitioner<Object>();
}
if (partitioner instanceof ForwardPartitioner) {
if (upstreamNode.getParallelism() != downstreamNode.getParallelism()) {
throw new UnsupportedOperationException("Forward partitioning does not allow " +
"change of parallelism. Upstream operation: " + upstreamNode + " parallelism: " + upstreamNode.getParallelism() +
", downstream operation: " + downstreamNode + " parallelism: " + downstreamNode.getParallelism() +
" You must use another partitioning strategy, such as broadcast, rebalance, shuffle or global.");
}
}
StreamEdge edge = new StreamEdge(upstreamNode, downstreamNode, typeNumber, outputNames, partitioner, outputTag);
getStreamNode(edge.getSourceId()).addOutEdge(edge);
getStreamNode(edge.getTargetId()).addInEdge(edge);
}
}
3.4 process of creating diagram
- addNode create StreamNode (id=1):

- addNode create StreamNode (id=2):

- addEdge creates an edge between StreamNode (id=1) and StreamNode (id=2), and then adds it to the outEdges list of StreamNode (id=1) and the inEdges list of StreamNode (id=2):
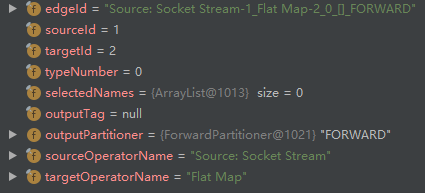
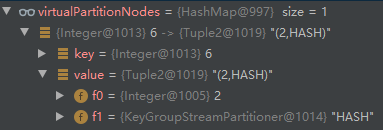
- addVirtualPartitionNode adds a virtual node with id=6. Enter node id=2:
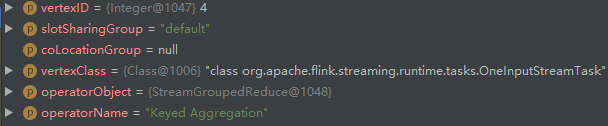
- addNode create StreamNode (id=4):
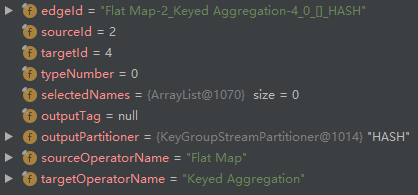
- addEdge creates an edge between StreamNode (id=2) and StreamNode (id=4), and then adds it to the outEdges list of StreamNode (id=2) and the inEdges list of StreamNode (id=4):
- addNode create StreamNode (id=5):
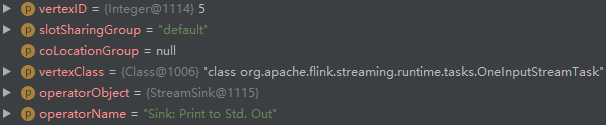
- addEdge creates an edge between StreamNode (id=4) and StreamNode (id=5), and then adds it to the outEdges list of StreamNode (id=4) and the inEdges list of StreamNode (id=5):
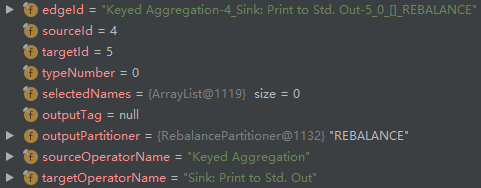
By observing and comparing steps 3 and 8, we can find that the outputPartitioner is different. One is ForwardPartitioner and the other is RebalancePartitioner. If the parallelism of two nodes is equal, use the former, and if they are not equal, use the latter.
The source code of judgment logic is as follows:
// If no partitioner was specified and the parallelism of upstream and downstream
// operator matches use forward partitioning, use rebalance otherwise.
if (partitioner == null && upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner = new ForwardPartitioner<Object>();
} else if (partitioner == null) {
partitioner = new RebalancePartitioner<Object>();
}
4, Summary
The return type of the getExecutionPlan method of the StreamExecutionEnvironment is exactly StreamGraph. In Flink execution plan level 1 - StreamTransformation The visualization function of execution plan has been shown. Finally, this figure is shown again: