Catalog
-
The requests module is simple to use
- A simple understanding of the requests module
- Use the requests module to crawl the source data of the first page of a search dog
- Implement a simple web page collector
- Solve garbled problems
- Solve UA detection problems
- Requs module crawls details of Douban movie
- The requests module crawls the results of a KFC restaurant query
- Exercises
The requests module is simple to use
A simple understanding of the requests module
- What is the requests module?
- A network request-based module is encapsulated in Python.
- What is the function of the requests module?
- Used to simulate browser requests
- Environment installation for requests module:
- pip install requests
- Coding flow for requests module:
- 1. Specify url
- 2. Initiate Request
- 3. Get response data
- 4. Persistent Storage
Use the requests module to crawl the source data of the first page of a search dog
#Crawl the page source data of the Sogou Homepage
import requests
#1. Specify url
url = 'https://www.sogou.com/'
#2. Request send get:get return value is a response object
response = requests.get(url=url)
#3. Get response data
page_text = response.text #Returns response data in string form
#4. Persistent Storage
with open('sogou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
Implement a simple web page collector
#Implement a simple web collector to crawl search results
#You need to make the parameters carried by the url dynamic
import requests
url = 'https://www.sogou.com/web'
#Implement Parameter Dynamization
wd = input('enter a key:')
params = {
'query':wd
}
#The dictionary corresponding to the request parameter needs to be applied to the parameter of the params get method in the request
response = requests.get(url=url,params=params)
page_text = response.text
fileName = wd+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
#results of enforcement
#Enter enter a key:Guo Kaifen
//When the above code executes, it is found that:
1.Random code appears
2.Incorrect data magnitude
Solve garbled problems
import requests
url = 'https://www.sogou.com/web'
#Implement Parameter Dynamization
wd = input('enter a key:')
params = {
'query':wd
}
#The dictionary corresponding to the request parameter needs to be applied to the parameter of the params get method in the request
response = requests.get(url=url,params=params)
response.encoding = 'utf-8' #Modify the encoding format of response data
page_text = response.text
fileName = wd+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
#results of enforcement
enter a key:jay
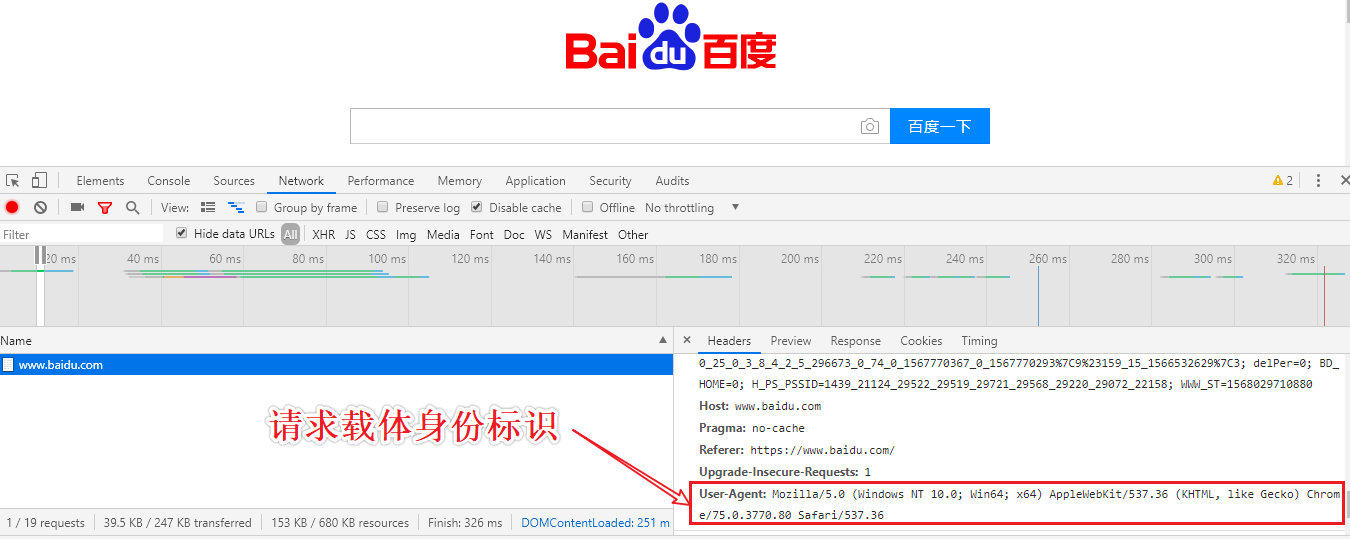
UA Detection: The portal website determines whether the change request is a crawler request by detecting the identity of the request carrier
UA Fake: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36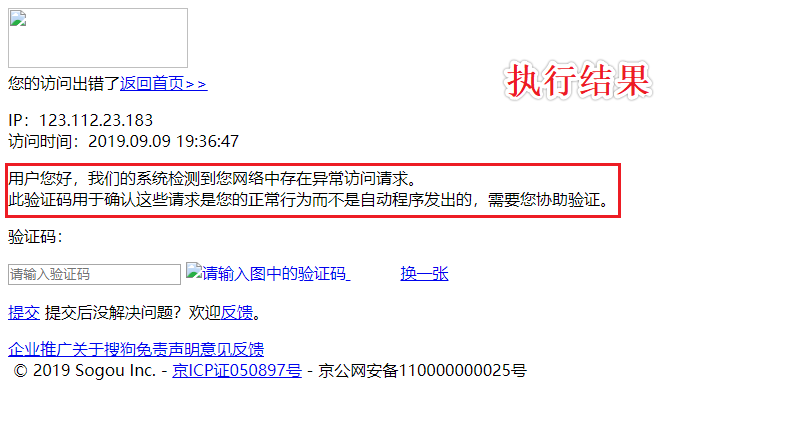
Solve UA detection problems
import requests
url = 'https://www.sogou.com/web'
#Implement Parameter Dynamization
wd = input('enter a key:')
params = {
'query':wd
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
#The dictionary corresponding to the request parameter needs to be applied to the parameter of the params get method in the request
response = requests.get(url=url,params=params,headers=headers)
response.encoding = 'utf-8' #Modify the encoding format of response data
page_text = response.text
fileName = wd+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
UA detection is a anti-crawl mechanism to determine whether access is legal
Requs module crawls details of Douban movie
#Details of the movie in Douban movie are crawled
https://movie.douban.com/typerank?type_name=%E7%88%B1%E6%83%85&type=13&interval_id=100:90&action=
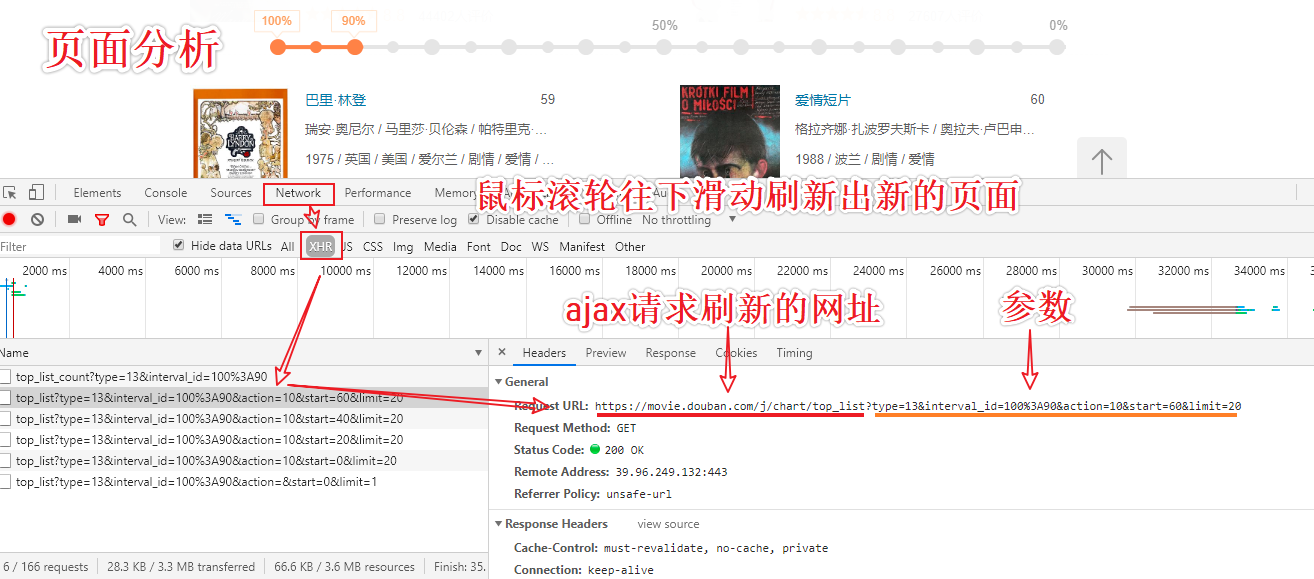
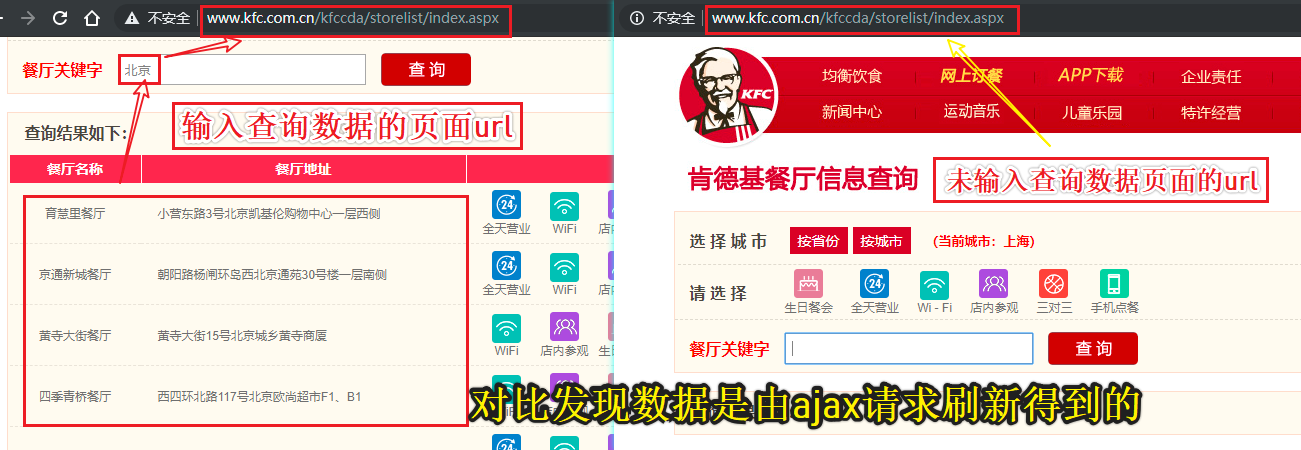
#Analysis: When the scrollbar slides to the bottom of the page, a partial refresh (request from ajax) occurs on the current page.
//Dynamically loaded page data
- Data requested through another separate request
import requests
url = 'https://movie.douban.com/j/chart/top_list'
start = input('Which movie do you want to start getting?:')
limit = input('How much movie data do you want to get?:')
dic = {
'type': '13',
'interval_id': '100:90',
'action': '',
'start': start,
'limit': limit,
}
response = requests.get(url=url,params=dic,headers=headers)
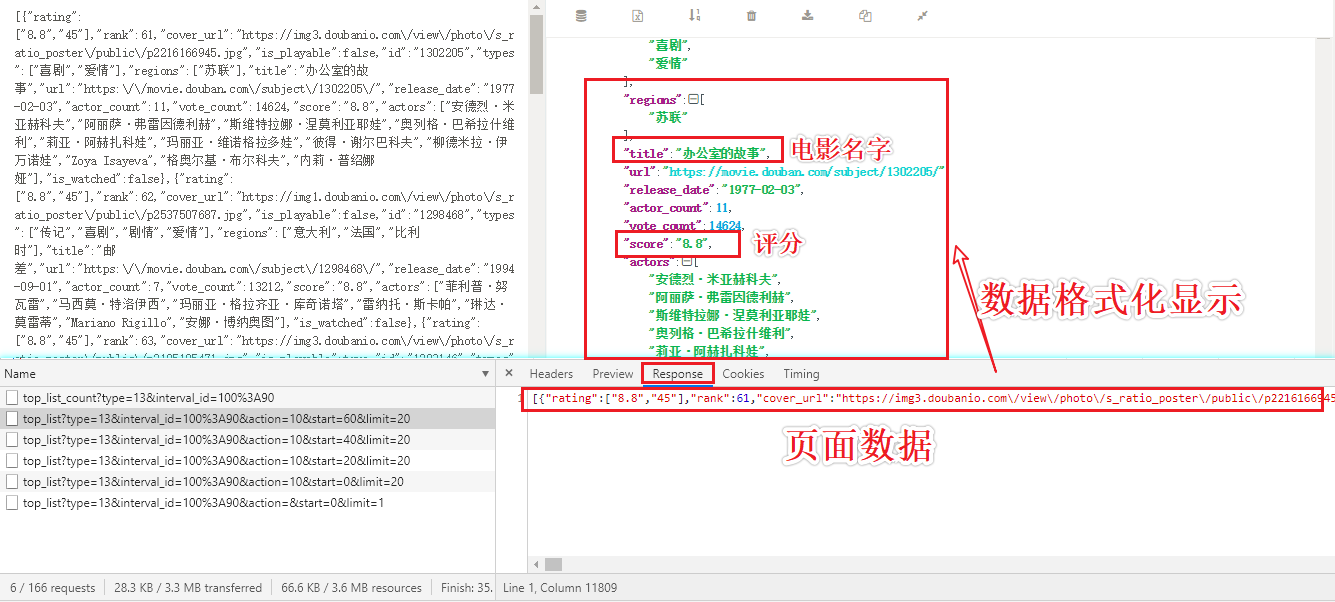
page_text = response.json() #json() returns a serialized instance object
for dic in page_text:
print(dic['title']+':'+dic['score'])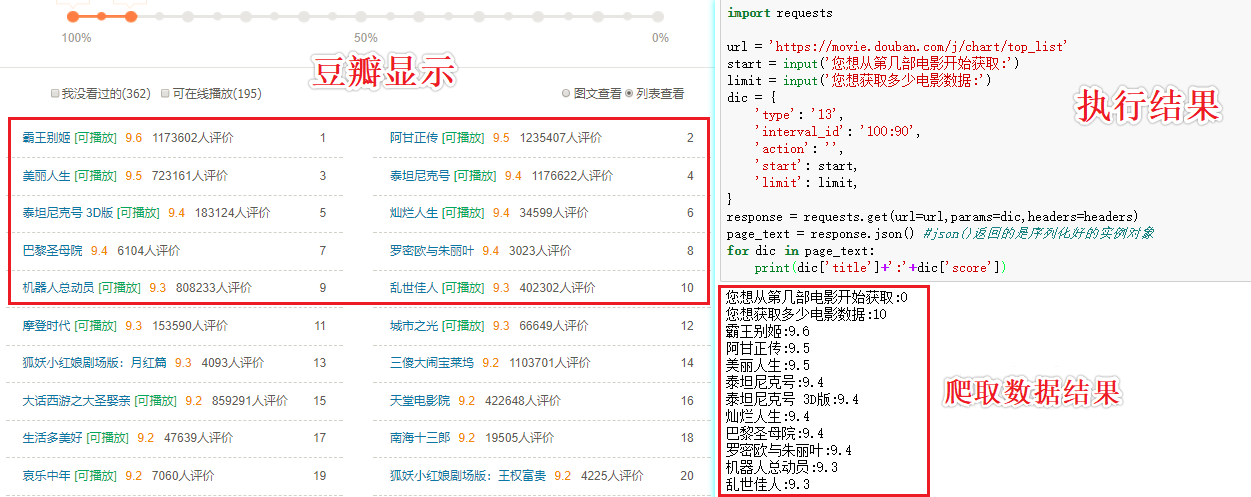
Page Analysis Process
The requests module crawls the results of a KFC restaurant query
#Kentucky Restaurant Query http://www.kfc.com.cn/kfccda/storelist/index.aspx
import requests
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
for page in range(1,2):
data = {
'cname': '',
'pid': '',
'keyword': 'Xi'an',
'pageIndex': str(page),
'pageSize': '5',
}
response = requests.post(url=url,headers=headers,data=data)
print(response.json())Analysis Page
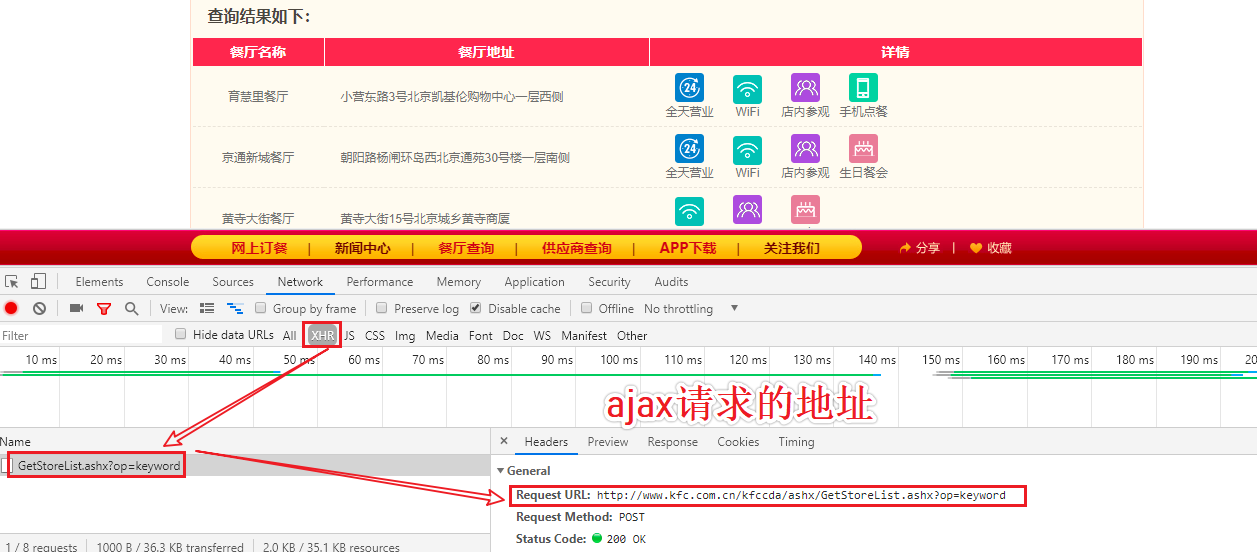
Crawl Data
{
'Table': [{
'rowcount': 33
}],
'Table1': [{
'rownum': 1,
'storeName': 'East Street (Xi'an)',
'addressDetail': '53 East Street',
'pro': '24 hour,Wi-Fi,Jukebox,Gift Card',
'provinceName': 'Qinghai Province',
'cityName': 'Xining City'
}, {
'rownum': 2,
'storeName': 'Tong An',
'addressDetail': 'First floor and second floor of Xi'an Square, Xi'an Road, Tong'an District',
'pro': '24 hour,Wi-Fi,Jukebox,Gift Card,Birthday Dinner',
'provinceName': 'Fujian Province',
'cityName': 'Xiamen City'
}, {
'rownum': 3,
'storeName': 'Definition',
'addressDetail': 'First floor of Minyong Building, No. 60 Xi'an Road',
'pro': '24 hour,Wi-Fi,Jukebox,In-store Visits,Gift Card',
'provinceName': 'Liaoning Province',
'cityName': 'Dalian'
}, {
'rownum': 4,
'storeName': 'Franklin Delano Roosevelt',
'addressDetail': 'No. 1, 139 Xi'an Road',
'pro': 'Wi-Fi,Jukebox,In-store Visits,Gift Card',
'provinceName': 'Liaoning Province',
'cityName': 'Dalian'
}, {
'rownum': 5,
'storeName': 'Mount Helan (Xi'an)',
'addressDetail': '1st floor, 6 Youyi East Street',
'pro': '24 hour,Wi-Fi,In-store Visits,Gift Card,Birthday Dinner',
'provinceName': 'Ningxia',
'cityName': 'Shizuishan'
}]
}
#Get the data you want based on your needsExercises
-
demand
- Crawling details of relevant enterprises in the General Administration of Drug Control http://125.35.6.84:81/xk/
requirement analysis
- How do I detect the presence of dynamically loaded data on a page?
- Implementation based on package capture tool
- Capture all packets after site requests
- Locate the requested packet in the packet corresponding to the address bar and perform a local search (a set of content on the page) in the data corresponding to the response tab.
- Searchable: crawled data is not dynamically loaded
- Not found: crawled data is dynamically loaded
- How do I locate the data package that is dynamically loaded in?
- Perform global search
- Implementation based on package capture tool
Author: Guo Kaifeng
Support blogger: If you feel the article is helpful to you, you can click on the bottom right corner of the article [Recommend ) One time.Your encouragement is the blogger's greatest motivation!
Self-explanatory: life, need to pursue; dream, need to insist; life, need to cherish; but on the way of life, more need to be strong.Start with gratitude, learn to love, love your parents, love yourself, love your friends, love others.