Window function is often used in work and often asked in interview. Do you know the implementation principle behind it?
Starting from the problems encountered in a business, this paper discusses the data flow principle of window function in hsql, and gives a solution to this problem at the end of the article.

1, Business background
First, simulate a business background. For example, when you look at Taobao app, as shown in the following figure:

After searching a keyword, a series of products will be displayed. These products have different types. For example, the first one is advertising products, and the last several are normal products. Use the following test table to describe the data:
create table window_test_table (id int, -- user idsq string, -- can identify each product cell_type int, -- identify each product type, such as advertisement, non advertisement rank int -- the location of the product under this search, such as the first advertised product is 1, followed by 2, 3, 4...) row format delayed fields terminated by ',';
Insert the following data into the table:
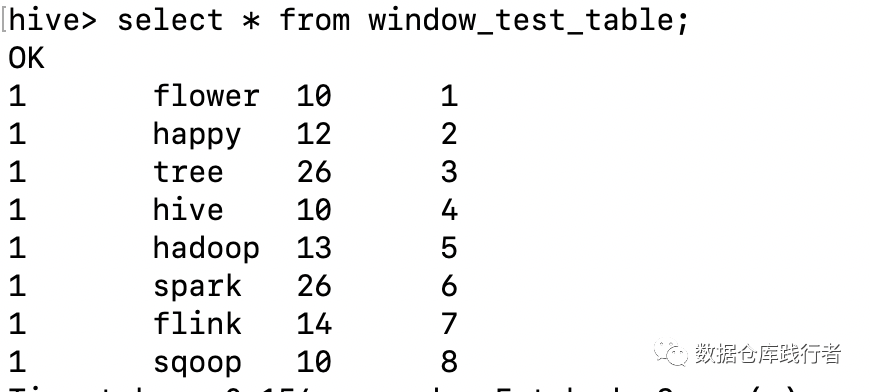
In the above data, cell ﹣ type column, assume that 26 represents advertising. Now there is a demand to get the natural ranking of non advertising product locations under each user's search. If:
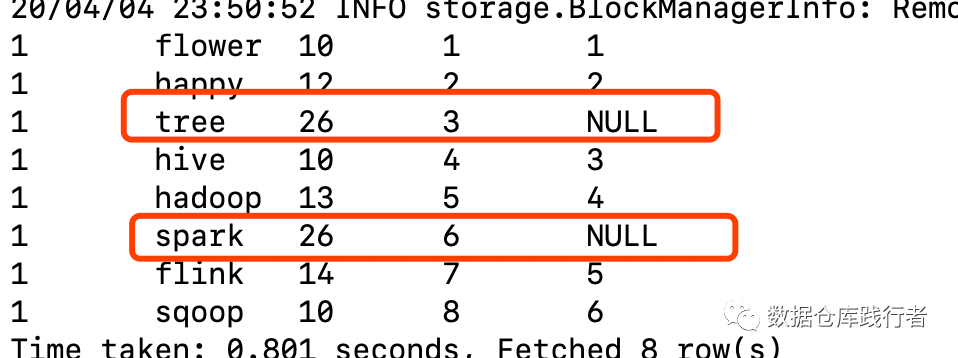
Business side's implementation method:
--Business side writingselectid,sq,cell_type,rank,if(cell_type!=26,row_number() over(partition by id order by rank),null) naturl_rankfrom window_test_table order by rank;
The results are as follows:

The result of the above writing method is obviously not what we want. Although 26 types of rank are removed, the ranking of non advertising products is not supplemented upward
Why? I think it's right? ~ ~ ~
Next, let's share the implementation principle of window function
2, Implementation principle of window s
Before analyzing the principle, let's briefly go through the use paradigm of window function:
selectrow_number() over( partition by col1 order by col2 )from table
The above statement is mainly divided into two parts
-
window func
-
Window definition section
2.1 window function part
The windows function part is the function to be executed on the window. spark supports three types of window functions:
-
aggregate functions
-
Sorting functions
-
Analysis functions
The first is familiar with count, sum, avg, etc
The second kind is row Hou number, rank and other sort functions
The third function is specially generated for the window. For example, the cume ﹣ dist function calculates the percentile of the current value in the window
2.2 window definition
This part is the content of over, which also has three parts
-
partition by
-
order by
-
ROWS | RANGE BETWEEN
The first two parts are to divide the data into buckets and then sort them in the buckets. Only when the data is sorted can you find out which data you need to take forward or backward to participate in the calculation. The third part is to determine what data you need.
spark provides two methods: one is ROWS BETWEEN, i.e. by distance
-
Rows between unbounded forecasting and current row is to retrieve the data from the beginning to the current. This is how the row [u number() function retrieves the data
-
Rows between 2 forecasting and 2 following represents taking the first two and the last two data to participate in the calculation, such as the moving average within five days before and after the calculation
Another way is to use RANGE BETWEEN, which is to use the current value as the anchor point for calculation. For example, if the current value of RANGE BETWEEN 20 forecasting and 10 following is 50, the data before and after the value is between 30 and 60 will be removed.
2.3 implementation principle of window function
The implementation of window function mainly relies on Partitioned Table Function (i.e. missing PTF);
The input of PTFs can be: table, subquery or output of another PTFs function;
The PTF s output is also a table.
Write a relatively complex sql to see the data flow when executing window functions:
selectid,sq,cell_type,rank,row_number() over(partition by id order by rank ) naturl_rank,rank() over(partition by id order by rank) as r,dense_rank() over(partition by cell_type order by id) as drfrom window_test_tablegroup by id,sq,cell_type,rank;
Data flow is as follows:

The above code implementation mainly includes three stages:
-
Calculate all other operations except window functions, such as group by, join, having, etc. The first phase of the above code is:
selectid,sq,cell_type,rankfrom window_test_tablegroup byid,sq,cell_type,rank
-
Take the output of the first step as the input of the first PTF s, and calculate the corresponding window function value. The second phase of the above code is:
Select id, SQ, cell_type, rank, naturl_rank, R from window (< w >, -- record the first stage output as wpartition by id, -- partition order by rank, -- order[naturl_rank:row_number(),r:rank()] - window function call)
Since the window corresponding to row u number() and rank() is the same (partition by id order by rank), the two functions can be completed in one shuffle.
-
Take the output of the second step as the input of the second PTF s, and calculate the corresponding window function value. The third phase of the above code is:
Select id, SQ, cell_type, rank, naturl_rank, R, Dr from window (< W1 >, -- record the output of the second stage as w1partition by cell_type, -- partition order by id, -- order of window function [Dr: deny_rank()] -- window function call)
Because the window of deny_rank() is different from the first two functions, you need to partition again to get the final output.
It can be seen from the above that to get the final result, you need to shuffle three times. In map reduce, you need to go through three map - > reduce combinations. In spark sql, you need to Exchange three times, plus the intermediate sorting operation. In the case of a large amount of data, the efficiency is basically not saved~~
These may be one of the reasons why window functions run slowly.
The execution plan of spark sql is attached here, which can be detailed (the execution plan of hive sql is too long, but the routine is basically the same):
spark-sql> explain select id,sq,cell_type,rank,row_number() over(partition by id order by rank ) naturl_rank,rank() over(partition by id order by rank) as r,dense_rank() over(partition by cell_type order by id) as dr from window_test_table group by id,sq,cell_type,rank;== Physical Plan ==Window [dense_rank(id#164) windowspecdefinition(cell_type#166, id#164 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS dr#156], [cell_type#166], [id#164 ASC NULLS FIRST]+- *(4) Sort [cell_type#166 ASC NULLS FIRST, id#164 ASC NULLS FIRST], false, 0+- Exchange hashpartitioning(cell_type#166, 200)+- Window [row_number() windowspecdefinition(id#164, rank#167 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS naturl_rank#154, rank(rank#167) windowspecdefinition(id#164, rank#167 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS r#155], [id#164], [rank#167 ASC NULLS FIRST]+- *(3) Sort [id#164 ASC NULLS FIRST, rank#167 ASC NULLS FIRST], false, 0+- Exchange hashpartitioning(id#164, 200)+- *(2) HashAggregate(keys=[id#164, sq#165, cell_type#166, rank#167], functions=[])+- Exchange hashpartitioning(id#164, sq#165, cell_type#166, rank#167, 200)+- *(1) HashAggregate(keys=[id#164, sq#165, cell_type#166, rank#167], functions=[])+- Scan hive tmp.window_test_table [id#164, sq#165, cell_type#166, rank#167], HiveTableRelation `tmp`.`window_test_table`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#164, sq#165, cell_type#166, rank#167]Time taken: 0.064 seconds, Fetched 1 row(s)
3, Solutions
Review the above sql:
selectid,sq,cell_type,rank,if(cell_type!=26,row_number() over(partition by id order by rank),null) naturl_rankfrom window_test_table
From the execution plan, you can see that the execution location of if function in sql is as follows:
spark-sql> explain select id,sq,cell_type,rank,if(cell_type!=26,row_number() over(partition by id order by rank),null) naturl_rank from window_test_table;== Physical Plan ==*(2) Project [id#4, sq#5, cell_type#6, rank#7, if (NOT (cell_type#6 = 26)) _we0#8 else null AS naturl_rank#0]### partition as well as row_number After implementation if ###+- Window [row_number() windowspecdefinition(id#4, rank#7 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS _we0#8], [id#4], [rank#7 ASC NULLS FIRST]+- *(1) Sort [id#4 ASC NULLS FIRST, rank#7 ASC NULLS FIRST], false, 0+- Exchange hashpartitioning(id#4, 200)+- Scan hive tmp.window_test_table [id#4, sq#5, cell_type#6, rank#7], HiveTableRelation `tmp`.`window_test_table`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#4, sq#5, cell_type#6, rank#7]Time taken: 0.728 seconds, Fetched 1 row(s)
Data flow:
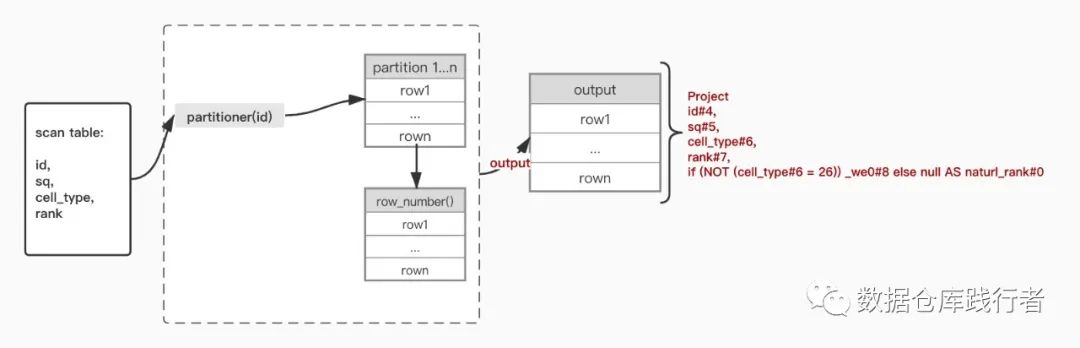
if function is executed after partition and row Ou number, so the position ranking is incorrect.
Rewrite it:
selectid,sq,cell_type,rank,if(cell_type!=26,row_number() over(partition by if(cell_type!=26,id,rand()) order by rank),null) naturl_rankfrom window_test_table
What should be paid attention to in this way of writing: make sure that the rand() function does not collide with the id.
Or the following can be written:
selectid,sq,cell_type,rank,row_number() over(partition by id order by rank) as naturl_rankfrom window_test_tablewhere cell_type!=26union allselectid,sq,cell_type,rank,null as naturl_rankfrom window_test_tablewhere cell_type=26
The disadvantage is to read the window test table table twice
Recommended reading:
The integration of Flink SQL client 1.10 and hive to read real-time data
Flink SQL client1.10 source code integrates hive in IDEA and runs
A design method of user retention model
spark sql multidimensional analysis and Optimization -- details are the devil
Record the optimization process of spark sql once
Comprehensive replay and source code analysis from the hive predicate triggered by a sql (I)
A comprehensive copy and source code analysis from the hive predicate triggered by sql (2)