During this time, I looked at the download components of the studio's tool library and found some problems:
1. There is a bug in the download core logic, and there is a probability that the download cannot be completed successfully when the download is suspended or fails.
2. Although the original design adopts the design of multi-threaded breakpoint continuous transmission, it is found that the download tasks are executed in serial under the same thread after logging, which does not accelerate the download speed.
Considering that the original code is not complex, this part of the download component is rewritten. Here we record the implementation of multithread breakpoint continuation function.
Please see the full PDF version
(more full project downloads. To be continued. Source code. The graphic knowledge will be uploaded to github later. )
Clickable About me Contact me for full PDF
(VX: mm14525201314)
Significance of multi thread Download
First of all, let's talk about the significance of multi-threaded download.
In daily scenarios, it is impossible to have only one connection between the download party and the server in the network. In order to avoid network congestion in such scenarios, TCP protocol can adjust the size of the window to avoid congestion, but the size of the window may not achieve the effect we expect: make full use of our bandwidth. Therefore, we can use multiple TCP connections to improve our bandwidth utilization, so as to speed up the download speed.
A metaphor is that we need to pump water from a water tank through a water pipe with a pump. Due to the limitation of the diameter of the pipe, etc., our single pipe can not fully use the pumping power of our pump. Therefore, we divide these tasks into several parts and allocate them to multiple pipes, so that we can make full use of our pumping power and improve the pumping speed.
Therefore, the main significance of using multi-threaded download is to improve the download speed.
Principle of multi thread Download
task allocation
As mentioned above, our main purpose is to allocate a total download task to multiple subtasks. For example, if we download this file with 5 threads, we can divide a task with length N equally as shown in the following figure:
However, in real scenarios, n is not exactly a multiple of 5, so for the last task, you need to add the remaining tasks, that is, N/5+N%5.
Http Range request header
We have learned the above task assignment, which seems to be ideal, but there is a problem, how can we only request a certain section of this file from the server instead of all?
We can specify the Range of the request by adding the Range field in the request header, so as to specify a section of data.
For example, RANGE bytes=10000-19999 specifies the data of 10000-19999 bytes
So our core idea is to get the InputStream of the corresponding byte segment of the file through it, and then read and write the file to it.
RandomAccessFile file write
Let's talk about the problem of file writing. Because we download files in multiple threads, the files are not written in bytes from the front to the back every time. It is possible to write data anywhere in the file at any time. So we need to be able to write data in the specified location of the file. Here we use RandomAccessFile to implement this function.
RandomAccessFile is a random access file class, which integrates FileOutputStream and FileInputStream, and supports reading and writing data from any byte of the file. Through it we can write data at any byte of the file.
Let's briefly talk about how we use RandomAccessFile here. We have a starting and ending position for each subtask. Each task can jump to the corresponding byte position of the file through RandomAccessFile::seek, and then read and write the InputStream from that position.
In this way, different threads can write files randomly.
Get file size
Since we need to assign tasks to each thread before we actually start downloading, we need to know the size of the file first.
To get the size of the file, we use the content length field in Response Headers.
As shown in the figure below, you can see that after opening the download request link, the Response Headers contain the content length we need, that is, the size of the file, in bytes.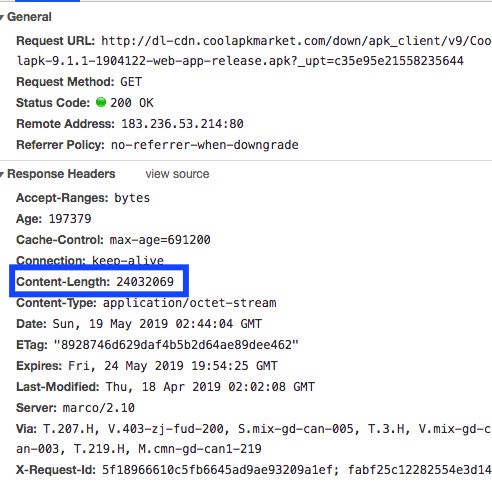
Breakpoint continuation principle
For multiple subtasks, how can we implement their breakpoint continuation?
In fact, the principle is very simple, just to ensure that the download progress of each subtask can be recorded in real time. In this way, you only need to read these download records to continue downloading, starting from the location where the last download ended.
There are many ways to implement it, as long as data persistence can be achieved. Here I use the database to implement.
In this way, our subtasks need to have some necessary information
- completedSize: current download completion size
- taskSize: total size of subtasks
- startPos: subtask start location
- currentPos: where subtasks go
- endPos: subtask end position
Through this information, we can record the download progress of the subtasks to restore our previous downloads and realize breakpoint renewal.
code implementation
Now we use the code to implement such a multi-threaded download function.
Download status
First, let's define the states in the download:
public class DownloadStatus {
public static final int IDLE = 233; // Idle, default state
public static final int COMPLETED = 234; // complete
public static final int DOWNLOADING = 235; // Download
public static final int PAUSE = 236; // suspend
public static final int ERROR = 237; // error
}As you can see, the above five states are defined here.
Abstraction of basic auxiliary class
Here we need to use functions such as database and HTTP request. Here we define the interface as follows. You can implement it yourself according to your needs:
Database auxiliary class
public interface DownloadDbHelper {
/**
* Delete subtask record from database
* @param task Subtask record
*/
void delete(SubDownloadTask task);
/**
* Insert subtask record into database
* @param task Subtask record
*/
void insert(SubDownloadTask task);
/**
* Update subtask records in database
* @param task Subtask record
*/
void update(SubDownloadTask task);
/**
* Get all subtask records under the specified Task
* @param taskTag Task Tag
* @return Subtask record
*/
List<SubDownloadTask> queryByTaskTag(String taskTag);
}Http helper class
public interface DownloadHttpHelper {
/**
* Get total file length
* @param url Download url
* @param callback Get file length CallBack
*/
void getTotalSize(String url, NetCallback<Long> callback);
/**
* Get InputStream
* @param url Download url
* @param start Starting position
* @param end End position
* @param callback Get the CallBack of the byte stream
*/
void getStreamByRange(String url, long start, long end, NetCallback<InputStream> callback);
}Subtask implementation
Member variables and explanation
Let's start from top to bottom and start from subtasks. In my design, it has the following member variables:
@Entity
public class SubDownloadTask implements Runnable {
public static final int BUFFER_SIZE = 1024 * 1024;
private static final String TAG = SubDownloadTask.class.getSimpleName();
@Id
private Long id;
private String url; // url of file download
private String taskTag; // Tag of parent task
private long taskSize; // Subtask size
private long completedSize; // Subtask completion size
private long startPos; // Starting position
private long currentPos; // current location
private long endPos; // End position
private volatile int status; // Current download status
@Transient
private SubDownloadListener listener; // Sub task download listening, mainly used to prompt the parent task
@Transient
private File saveFile; // File to save to
...
}Because the operation of the database here is implemented by green Dao, there are some related comments here that you can ignore.
InputStream get
As you can see, the subtask is a Runnable. We can start downloading through its run method, so that we can start multiple threads to execute subtasks through ExecutorService.
We see its run method:
@Override
public void run() {
status = DownloadStatus.DOWNLOADING;
DownloadManager.getInstance()
.getHttpHelper()
.getStreamByRange(url, currentPos, endPos, new NetCallback<InputStream>() {
@Override
public void onResult(InputStream inputStream) {
listener.onSubStart();
writeFile(inputStream);
}
@Override
public void onError(String message) {
listener.onSubError("Failed to get file stream");
status = DownloadStatus.ERROR;
}
});
}As you can see, we get the byte stream from currentPos to endPos, get its InputStream through its Response Body, and then call writeFile(InputStream) to write the file.
File write
Next, see the writeFile method:
private void writeFile(InputStream in) {
try {
RandomAccessFile file = new RandomAccessFile(saveFile, "rwd"); // Creating RandomAccessFile through saveFile
file.seek(currentPos); // Jump to the corresponding position
byte[] buffer = new byte[BUFFER_SIZE];
while (true) {
// Loop through InputStream until pause or end of read
if (status != DownloadStatus.DOWNLOADING) {
// The status is not DOWNLOADING, stop DOWNLOADING
break;
}
int offset = in.read(buffer, 0, BUFFER_SIZE);
if (offset == -1) {
// Unable to read data, indicating the end of reading
break;
}
// Write the read data to a file
file.write(buffer, 0, offset);
// Download data and update in database
currentPos += offset;
completedSize += offset;
DownloadManager.getInstance()
.getDbHelper()
.update(this);
// Notify parent task download progress
listener.onSubDownloading(offset);
}
if(status == DownloadStatus.DOWNLOADING) {
// Download complete
status = DownloadStatus.COMPLETED;
// Notify parent task download complete
listener.onSubComplete(completedSize);
}
file.close();
in.close();
} catch (IOException e) {
e.printStackTrace();
listener.onSubError("File download failed");
status = DownloadStatus.ERROR;
resetTask();
}
}See the comments in the code for the specific process. As you can see, the subtask is actually to read the InputStream circularly, write to the file, and synchronize the download progress to the database.
Parent task implementation
The parent task is our specific download task. We also see the member variables first:
public class DownloadTask implements SubDownloadListener {
private static final String TAG = DownloadTask.class.getSimpleName();
private String tag; // Tag of download task, used to distinguish different download tasks
private String url; // Download url
private String savePath; // Save path
private String fileName; // Save filename
private DownloadListener listener; // Download monitoring
private long completeSize; // Download complete size
private long totalSize; // Total download task size
private int status; // Current download progress
private int threadNum; // Number of threads (download threads per task set externally)
private File file; // Save file
private List<SubDownloadTask> subTasks; // Subtask list
private ExecutorService mExecutorService; // Thread pool for subtasks
...
}Download function
For a download task, the download method can be used to start execution:
public void download() {
listener.onStart();
subTasks = querySubTasks();
status = DownloadStatus.DOWNLOADING;
if (subTasks.isEmpty()) {
// It's a new task.
downloadNewTask();
} else if (subTasks.size() == threadNum) {
// It's not a new task
downloadExistTask();
} else {
// It is not a new task, but the number of download threads is wrong
listener.onError("Wrong breakpoint data");
resetTask();
}
}As you can see, we first read the list of subtasks from the database.
- If the list of subtasks is empty, it means that there is no download record, that is, a new task. Call the downloadNewTask method.
- If the subtask list size is equal to the number of threads, it is not a new task. Call the downloadExistTask method.
-
If the subtask list size is not equal to the number of threads, the current download record is no longer available, so reset the download task and download from a new one.
Download new tasks
Let's first see the downloadNewTask method:
DownloadManager.getInstance() .getHttpHelper() .getTotalSize(url, new NetCallback<Long>() { @Override public void onResult(Long total) { completeSize = 0L; totalSize = total; initSubTasks(); startAsyncDownload(); } @Override public void onError(String message) { error("Failed to get file length"); } });It can be seen that after obtaining the total length, the subtask list is initialized (by calculating the length of the sub task) by calling the initSubTasks method, then the startAsyncDownload method is invoked, and the sub task is run through ExecutorService to enter the sub task to download.
We see the initSubTasks method:
private void initSubTasks() {
long averageSize = totalSize / threadNum;
for (int taskIndex = 0; taskIndex < threadNum; taskIndex++) {
long taskSize = averageSize;
if (taskIndex == threadNum - 1) {
// For the last task, size needs to add the remaining quantity
taskSize += totalSize % threadNum;
}
long start = 0L;
int index = taskIndex;
while (index > 0) {
start += subTasks.get(index - 1).getTaskSize();
index--;
}
long end = start + taskSize - 1; // Pay attention here.
SubDownloadTask subTask = new SubDownloadTask();
subTask.setUrl(url);
subTask.setStatus(DownloadStatus.IDLE);
subTask.setTaskTag(tag);
subTask.setCompletedSize(0);
subTask.setTaskSize(taskSize);
subTask.setStartPos(start);
subTask.setCurrentPos(start);
subTask.setEndPos(end);
subTask.setSaveFile(file);
subTask.setListener(this);
DownloadManager.getInstance()
.getDbHelper()
.insert(subTask);
subTasks.add(subTask);
}
}It can be seen that it is to calculate the size of each task and the position of the start and end points. Here, it should be noted that - 1 is required for endPos, otherwise the download positions of each task will overlap, and the last task will download one more byte, resulting in such effects as file damage. The reason is that for example, a file with a size of 500 should be 0-499 instead of 0-500.
Restore old tasks
Next let's look at the downloadExistTask method:
private void downloadExistTask() {
// It is not a new task, and the number of download threads is correct. Calculate the downloaded size
completeSize = countCompleteSize();
totalSize = countTotalSize();
startAsyncDownload();
}In fact, it is very simple here. Traverse the subtask list to calculate the downloaded amount and total task amount, and call startAsyncDownload to start multi-threaded download.
Perform subtasks
For specific sub tasks, we can see the startAsyncDownload method:
private void startAsyncDownload() {
for (SubDownloadTask subTask : subTasks) {
if (subTask.getCompletedSize() < subTask.getTaskSize()) {
// Download only subtasks without end of download
mExecutorService.execute(subTask);
}
}
}As you can see, this is just to execute the corresponding sub task (Runnable) through ExecutorService.
####Pause function
Let's see the pause method:
public void pause() {
stopAsyncDownload();
status = DownloadStatus.PAUSE;
listener.onPause();
}As you can see, here you just call the stopAsyncDownload method to stop the subtask.
See the stopAsyncDownload method:
private void stopAsyncDownload() {
for (SubDownloadTask subTask : subTasks) {
if (subTask.getStatus() != DownloadStatus.COMPLETED) {
// Download completed will not be cancelled
subTask.cancel();
}
}
}As you can see, the cancel method of the subtask is called.
Continue to see the cancel method for subtasks:
void cancel() {
status = DownloadStatus.PAUSE;
listener.onSubCancel();
}It's very simple here. Just set the download status to PAUSE, so that when the next while loop is written to the file, it will abort the loop and end the Runnable execution.
Cancel function
See the cancel method:
public void cancel() {
stopAsyncDownload();
resetTask();
listener.onCancel();
}It can be seen that the logic is similar to that of pause, except that the subtasks need to be reset after pause so that the next download starts from scratch.
Notification mechanism from bottom to top
As mentioned earlier, external users can monitor the download progress through DownloadListener. The following is the definition of DownloadListener interface:
public interface DownloadListener {
default void onStart() {}
default void onDownloading(long progress, long total) {}
default void onPause() {}
default void onCancel() {}
default void onComplete() {}
default void onError(String message) {}
}Our real-time download progress can only be reflected in the process of saving files of subtasks. Similarly, the download failure of subtasks also needs to be notified to DownloadListener. How can we do this?
As mentioned earlier, we also defined a SubDownloadListener whose listener is the parent task of the child task. By listening, we can feed back the status of the subtask to the parent task, and the parent task feeds back the data to the DownloadListener according to the specific situation.
public interface SubDownloadListener {
void onSubStart();
void onSubDownloading(int offset);
void onSubCancel();
void onSubComplete(long completeSize);
void onSubError(String message);
}For example, as we have seen before, onSubError will be called every time the download fails, onSubDownload(offset) will be called every time the offset data is read, and onSubComplete(completeSize) will be called every time the download fails. In this way, the download status of our subtasks is successfully returned to the upper level.
Let's take a look at how the upper layer deals with it:
@Override
public void onSubStart() {}
@Override
public void onSubDownloading(int offset) {
synchronized (this) {
completeSize = completeSize + offset;
listener.onDownloading(completeSize, totalSize);
}
}
@Override
public void onSubCancel() {}
@Override
public void onSubComplete(long completeSize) {
checkComplete();
}
@Override
public void onSubError(String message) {
error(message);
}It can be seen that every time a piece of data is downloaded, it will return the data amount. At this time, completeSize adds the corresponding offset, and then notifies the listener of the new completeSize, so as to monitor the download progress. The reason for locking here is that there will be multiple threads (subtask threads) to operate completeSize. Locking ensures thread safety.
Each time a subtask is completed, it will call the checkComplete method to check whether the download is complete. If each subtask is completed, it means that the task download is complete, and then notify the listener.
Similarly, every time an error occurs in a subtask, the listener will be notified of the error, and some processing will be done in case of error.
So far, this article is over. We have successfully implemented the multi thread breakpoint download function. Based on this principle, we can do some upper encapsulation to implement a file download framework.
Please see the full PDF version
(more full project downloads. To be continued. Source code. The graphic knowledge will be uploaded to github later. )
Clickable About me Contact me for full PDF
(VX: mm14525201314)