HPA is the implementation of horizontal scaling in k8s. There are many ideas that can be used for reference, such as delay queue, time series window, change event mechanism, stability consideration and other key mechanisms. Let's learn the key implementation of the big guys together
1. Basic concepts
As the implementation of general horizontal expansion, horizon pod autoscaler (HPA) has many key mechanisms. Let's first look at the objectives of these key mechanisms
1.1 implementation mechanism of horizontal expansion
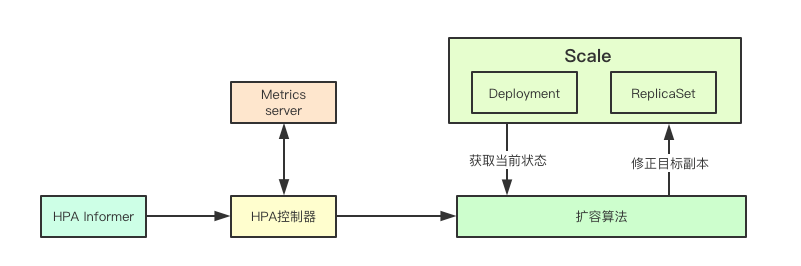
The implementation mechanism of HPA controller is mainly to obtain the current HPA object through the informer, then obtain the monitoring data of the corresponding Pod set through the metrics service, then according to the current scale state of the current target object, and according to the expansion algorithm, make decisions on the current copy of the corresponding resource and update the scale object, so as to realize the automatic expansion
1.2 four intervals of HPA
According to the parameters of HPA and the current replica count of the current scale (target resource), HPA can be divided into the following four sections: closed, high water level, low water level and normal. Only in the normal section can HPA controller dynamically adjust
1.3 measurement type
HPA currently supports two types of measurement: Pod and Resource. Although the rest is described in the official description, it is not implemented in the code at present. The monitoring data is mainly implemented through the API server agent metrics server. The access interface is as follows
/api/v1/model/namespaces/{namespace}/pod-list/{podName1,podName2}/metrics/{metricName}
1.4 delay queue
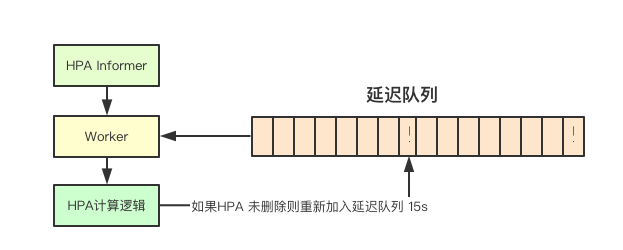
The HPA controller does not monitor the changes of various underlying informer s, such as Pod, Deployment, ReplicaSet and other resources, but puts the current HPA object back into the delay queue after each processing, thus triggering the next detection. If you do not modify the default time is 15s, That is to say, after another consistency test, it will take at least 15 seconds for the HPA to perceive the excess of the immediate measurement index
1.5 monitoring time series window
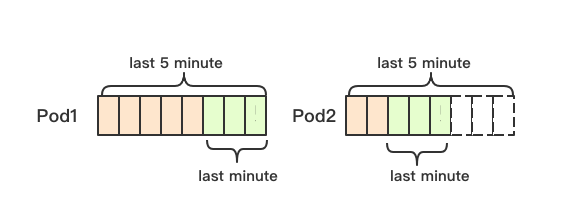
From metrics When the server obtains the pod monitoring data, the HPA controller will obtain the data in the last 5 minutes (hard coding) and obtain the data in the last 1 minute (hard coding) for calculation, which is equivalent to taking the data in the last minute as a sample. Note that 1 minute here refers to the data in the previous minute of the latest indicator in the monitoring data, rather than the data in the current time
1.6 stability and delay
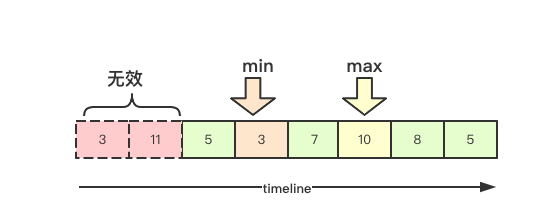
As mentioned earlier, the delay queue will trigger HPA detection every 15s. If the monitoring data changes within one minute, many scale update operations will be generated, resulting in frequent changes in the number of copies of the corresponding controller. In order to ensure the stability of the corresponding resources, The HPA controller adds a delay time to the implementation, that is, the previous decision suggestions will be retained in this time window, and then the decision will be made according to all the current effective decision suggestions, so as to ensure the desired number of copies is changed as small as possible and the stability is guaranteed
The basic concepts are introduced first, because there are more computing logic in HPA and more code in the core implementation today
2. Core implementation
The implementation of HPA controller is mainly divided into the following parts: obtaining scale object, making fast decision according to the interval, and then the core implementation calculates the final expected replica according to the current metric, current replica and scaling strategy according to the scaling algorithm. Let's take a look at the key implementation in turn
2.1 get scale object according to ScaleTargetRef
It mainly obtains the corresponding version according to the artifact scheme, and then obtains the scale object of the corresponding Resource through the version
targetGV, err := schema.ParseGroupVersion(hpa.Spec.ScaleTargetRef.APIVersion) targetGK := schema.GroupKind{ Group: targetGV.Group, Kind: hpa.Spec.ScaleTargetRef.Kind, } scale, targetGR, err := a.scaleForResourceMappings(hpa.Namespace, hpa.Spec.ScaleTargetRef.Name, mappings)
2.2 interval decision

Interval decision-making will first determine the current number of replicas according to the value of the current scale object and the corresponding parameters configured in the current hpa. For the two cases that exceed the set maxReplicas and are less than minReplicas, it only needs to simply modify to the corresponding value and directly update the corresponding scale object. For the object with scale copy 0, hpa will not perform any operation
if scale.Spec.Replicas == 0 && minReplicas != 0 { // autoscaling has been turned off desiredReplicas = 0 rescale = false setCondition(hpa, autoscalingv2.ScalingActive, v1.ConditionFalse, "ScalingDisabled", "scaling is disabled since the replica count of the target is zero") } else if currentReplicas > hpa.Spec.MaxReplicas { // If the current number of copies is greater than the expected number of copies desiredReplicas = hpa.Spec.MaxReplicas } else if currentReplicas < minReplicas { // If the current number of copies is less than the minimum number of copies desiredReplicas = minReplicas } else { // The logic of this part is relatively complex. Later, it is actually one of the most critical implementation parts of HPA }
2.3 core logic of HPA dynamic scaling decision

The core decision logic is mainly divided into two steps: 1) determine the current desired number of copies by monitoring the data; 2) modify the final expected number of copies according to behavior, and then we continue to go deep into the underlying layer
// Obtain the desired number, time and status of replicas through monitoring data acquisition metricDesiredReplicas, metricName, metricStatuses, metricTimestamp, err = a.computeReplicasForMetrics(hpa, scale, hpa.Spec.Metrics) // If the number of copies through the monitoring decision is not 0, the expected number of copies is set as the number of copies of the monitoring decision if metricDesiredReplicas > desiredReplicas { desiredReplicas = metricDesiredReplicas rescaleMetric = metricName } // The final expected replica decision will be made according to whether the behavior is set, and the relevant data of previous stability will also be considered if hpa.Spec.Behavior == nil { desiredReplicas = a.normalizeDesiredReplicas(hpa, key, currentReplicas, desiredReplicas, minReplicas) } else { desiredReplicas = a.normalizeDesiredReplicasWithBehaviors(hpa, key, currentReplicas, desiredReplicas, minReplicas) } // If it is found that the current number of copies is not equal to the expected number of copies rescale = desiredReplicas != currentReplicas
2.4 copy count decision of multidimensional metrics
Multiple monitoring metrics can be set in HPA. HPA will obtain the proposed maximum replica count from multiple metrics based on the monitoring data as the ultimate goal. Why should the largest one be adopted? To meet the capacity expansion requirements of all monitoring metrics as much as possible, you need to select the maximum expected replica count
func (a *HorizontalController) computeReplicasForMetrics(hpa *autoscalingv2.HorizontalPodAutoscaler, scale *autoscalingv1.Scale, // Calculate the number of proposed copies according to the set metricsl for i, metricSpec := range metricSpecs { // Get proposed copies, number, time replicaCountProposal, metricNameProposal, timestampProposal, condition, err := a.computeReplicasForMetric(hpa, metricSpec, specReplicas, statusReplicas, selector, &statuses[i]) if err != nil { if invalidMetricsCount <= 0 { invalidMetricCondition = condition invalidMetricError = err } // Invalid replica count invalidMetricsCount++ } if err == nil && (replicas == 0 || replicaCountProposal > replicas) { // Take a larger copy proposal each time timestamp = timestampProposal replicas = replicaCountProposal metric = metricNameProposal } } }
2.5 calculation of pod metrics and Realization of expected replica decision
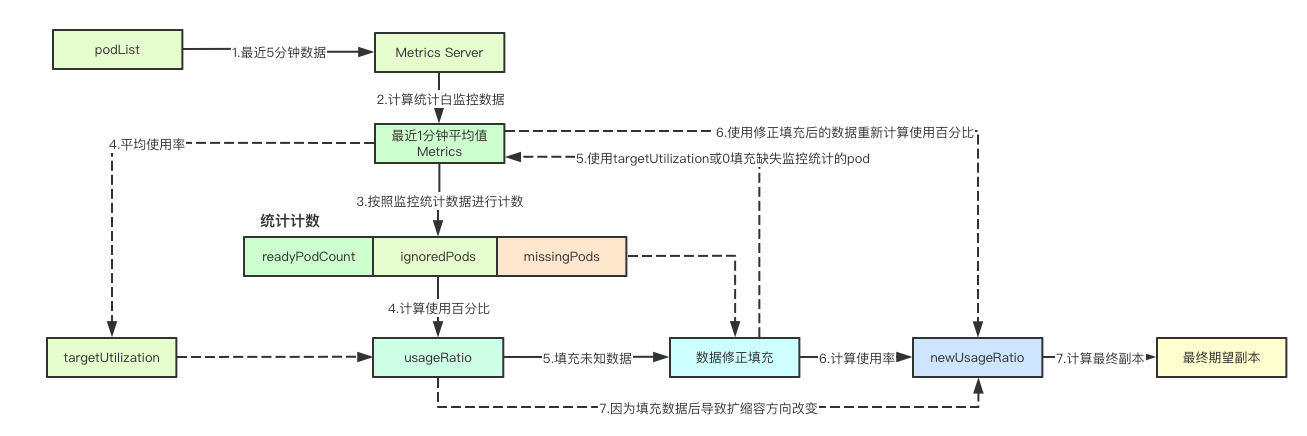
Because of the limitation of space, only the calculation and implementation mechanism of Pod metrics are described here. Because there are many contents, there will be several sections here. Let's explore them together
2.5.1 calculation of Pod measurement data
This is the acquisition part of the latest monitoring indicator. After obtaining the monitoring indicator data, the average value of the last minute monitoring data corresponding to the Pod will be taken as the sample to participate in the subsequent expected copy calculation
func (h *HeapsterMetricsClient) GetRawMetric(metricName string, namespace string, selector labels.Selector, metricSelector labels.Selector) (PodMetricsInfo, time.Time, error) { // Get all pod s podList, err := h.podsGetter.Pods(namespace).List(metav1.ListOptions{LabelSelector: selector.String()}) // Status of last 5 minutes startTime := now.Add(heapsterQueryStart) metricPath := fmt.Sprintf("/api/v1/model/namespaces/%s/pod-list/%s/metrics/%s", namespace, strings.Join(podNames, ","), metricName) resultRaw, err := h.services. ProxyGet(h.heapsterScheme, h.heapsterService, h.heapsterPort, metricPath, map[string]string{"start": startTime.Format(time.RFC3339)}). DoRaw() var timestamp *time.Time res := make(PodMetricsInfo, len(metrics.Items)) // Traverse the monitoring data of all pods, and then conduct the last minute sampling for i, podMetrics := range metrics.Items { // The average value of pod in the last minute val, podTimestamp, hadMetrics := collapseTimeSamples(podMetrics, time.Minute) if hadMetrics { res[podNames[i]] = PodMetric{ Timestamp: podTimestamp, Window: heapsterDefaultMetricWindow, // 1 minutes Value: int64(val), } if timestamp == nil || podTimestamp.Before(*timestamp) { timestamp = &podTimestamp } } } }
2.5.2 expected copy calculation implementation
The calculation and implementation of the desired replica is mainly in calcPlainMetricReplicas. There are many things to consider here. According to my understanding, I will split this part into sections for the convenience of readers. These codes belong to calcPlainMetricReplicas
1. When acquiring monitoring data, the corresponding Pod may have three situations:
readyPodCount, ignoredPods, missingPods := groupPods(podList, metrics, resource, c.cpuInitializationPeriod, c.delayOfInitialReadinessStatus)
1) Currently, Pod is still in Pending status. This kind of Pod is recorded as ignore or skipped in monitoring (because you don't know whether it will succeed or not, but at least it is not successful at present) as ignored pods 2) Normal state, i.e. with monitoring data, is normal. At least you can get your monitoring data, which is extremely recorded as readyPod 3) Apart from the above two states, all the pods that have not been deleted are recorded as missingPods
2. Calculation of utilization rate
usageRatio, utilization := metricsclient.GetMetricUtilizationRatio(metrics, targetUtilization)
In fact, it is relatively simple to calculate the usage rate. We only need to calculate the usage rate of all pods of readyPods
3. Rebalancing ignored
rebalanceIgnored := len(ignoredPods) > 0 && usageRatio > 1.0 // Middle omit part logic if rebalanceIgnored { // on a scale-up, treat unready pods as using 0% of the resource request // If you need to rebalance skipped pods. After zooming in, treat the not ready pods as using 0% of resource requests for podName := range ignoredPods { metrics[podName] = metricsclient.PodMetric{Value: 0} } }
If the utilization rate is greater than 1.0, it indicates that the ready Pod has actually reached the HPA trigger threshold, but how to calculate the currently pending Pod? In k8s, it's often said that the final expected state is the final expected state. In fact, for these pods that are currently in the pending state, the final high probability will become ready. Because the utilization rate is now too high, can I add this part of Pod that may succeed in the future to meet the threshold requirements? So here, the corresponding Value is mapped to 0, which will be recalculated later, and whether the threshold setting of HPA can be met after adding this part of Pod
4.missingPods
if len(missingPods) > 0 { // If the bad pod is greater than 0, some pods do not get metric data if usageRatio < 1.0 { // If it is less than 1.0, it means that the usage rate is not reached, then set the corresponding value to target target target usage for podName := range missingPods { metrics[podName] = metricsclient.PodMetric{Value: targetUtilization} } } else { // If > 1 indicates that the capacity expansion is to be carried out, then the pod value of those status not obtained is set to 0 for podName := range missingPods { metrics[podName] = metricsclient.PodMetric{Value: 0} } } }
missingPods are currently Pods that are neither Ready nor Pending. These Pods may be lost or failed, but we can't predict their status. There are two options, one is to give a maximum value, the other is to give a minimum value. How to make a decision? The answer is to look at the current utilization rate. If the utilization rate is less than 1.0, we will try to give the maximum value of this unknown Pod. If this part of Pod cannot be recovered, we will try to find out whether we will reach the threshold value at present. Otherwise, we will give the minimum value and pretend that they do not exist
5. Decision results
if math.Abs(1.0-newUsageRatio) <= c.tolerance || (usageRatio < 1.0 && newUsageRatio > 1.0) || (usageRatio > 1.0 && newUsageRatio < 1.0) { // Returns the current copy if the change is too small, or if the new usage will result in a change in the zoom direction return currentReplicas, utilization, nil }
After the above correction data, the usage rate will be calculated again, i.e. new usage ratio. If it is found that the calculated value is within the tolerance range and the current value is 0.1, then any scaling operation will be performed
On the other hand, after recalculating the usage rate, if our original usage rate is less than 1.0, that is, the threshold is not reached, and after data filling, now it is more than 1.0, then no operation should be carried out. Why? Because the utilization rate of all the nodes in the original ready is less than 1.0, but now you are calculating more than 1.0, you should scale. If you scale the ready, and the unknown nodes are still down, you need to scale again. Is this useless?
2.6 stability decision with Behavior
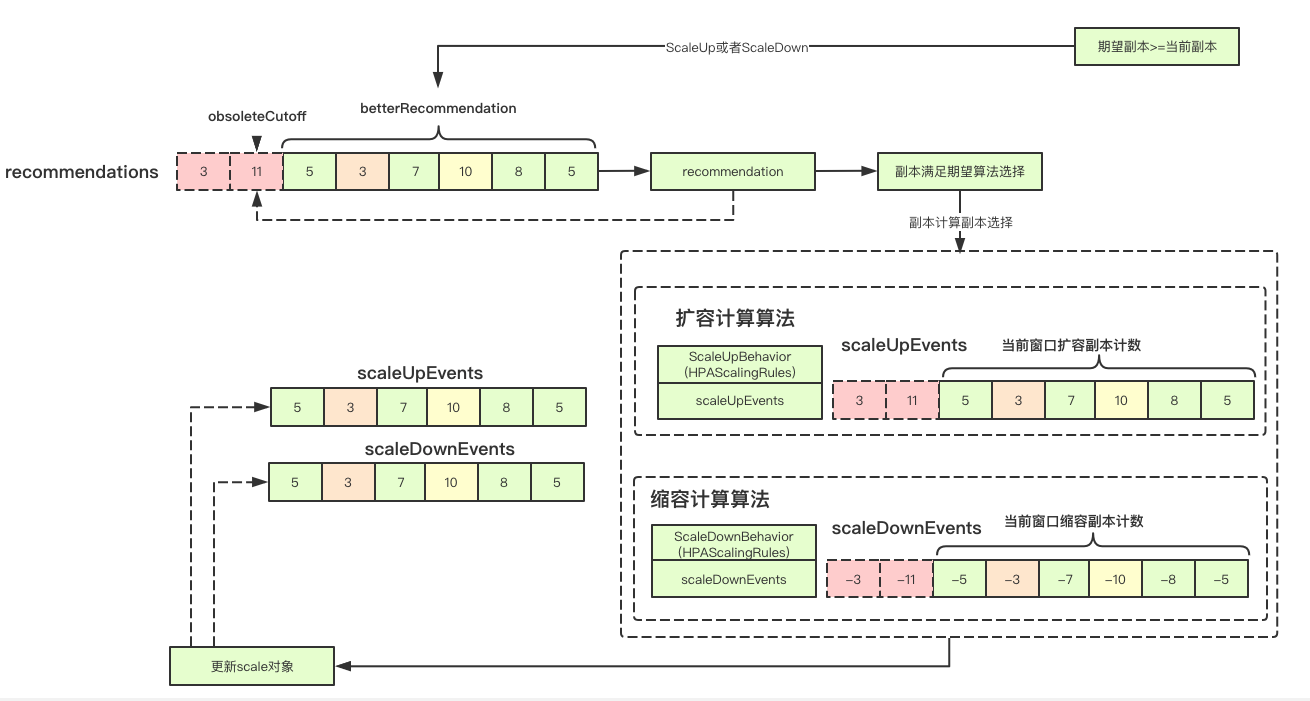
The decision-making without behaviors is relatively simple. Here we mainly talk about the decision-making implementation with behaviors. The content is relatively large and can be divided into several sections. All the implementations are mainly in the stabilize recommendation with behaviors
2.6.1 stable time window
In the HPA controller, there is a time window for expanding and shrinking, that is to say, in this window, the ultimate goal of HPA expanding and shrinking will be kept in a stable state as far as possible, in which the expanding is 3 minutes, and the shrinking is 5 minutes
2.6.2 according to whether the expected copy meets the update delay time
if args.DesiredReplicas >= args.CurrentReplicas { // If the expected number of copies is greater than or equal to the current number of copies, the delay time = the stable window time of scaleUpBehaviro scaleDelaySeconds = *args.ScaleUpBehavior.StabilizationWindowSeconds betterRecommendation = min } else { // Expected copies < current copies scaleDelaySeconds = *args.ScaleDownBehavior.StabilizationWindowSeconds betterRecommendation = max }
In the expansion strategy, the expansion will be based on the minimum value in the window, while the expansion will be based on the maximum value in the window
2.6.3 calculation of the number of copies of the final proposal
First, according to the delay time in the current window, according to the proposed comparison function, get the recommended number of target copies,
// Expiration date obsoleteCutoff := time.Now().Add(-time.Second * time.Duration(maxDelaySeconds)) // Deadline cutoff := time.Now().Add(-time.Second * time.Duration(scaleDelaySeconds)) for i, rec := range a.recommendations[args.Key] { if rec.timestamp.After(cutoff) { // After the deadline, the current proposal is valid, and the final number of proposal copies is determined according to the previous comparison function recommendation = betterRecommendation(rec.recommendation, recommendation) } }
2.6.4 make expected copy decision according to behavior
After making a decision before, I will decide the expected maximum value. Here, I just need to make the final decision of the desired copy according to behavior (actually, our strategy of scaling), Among them, calculateScaleUpLimitWithScalingRules and calculateScaleDownLimitWithBehaviors only increase or decrease the number of pod according to our expansion strategy. The key design is the correlation calculation of the following periodic events
func (a *HorizontalController) convertDesiredReplicasWithBehaviorRate(args NormalizationArg) (int32, string, string) { var possibleLimitingReason, possibleLimitingMessage string if args.DesiredReplicas > args.CurrentReplicas { // If the expected replica is larger than the current replica, the capacity is expanded scaleUpLimit := calculateScaleUpLimitWithScalingRules(args.CurrentReplicas, a.scaleUpEvents[args.Key], args.ScaleUpBehavior) if scaleUpLimit < args.CurrentReplicas { // If the current number of replicas is greater than the limit, you should not continue to expand. Currently, the expansion requirements have been met scaleUpLimit = args.CurrentReplicas } // Maximum allowed quantity maximumAllowedReplicas := args.MaxReplicas if maximumAllowedReplicas > scaleUpLimit { // If the maximum quantity is greater than the capacity expansion Online maximumAllowedReplicas = scaleUpLimit } else { } if args.DesiredReplicas > maximumAllowedReplicas { // If the desired number of copies > the maximum number of copies allowed return maximumAllowedReplicas, possibleLimitingReason, possibleLimitingMessage } } else if args.DesiredReplicas < args.CurrentReplicas { // Shrink if the desired replica is smaller than the current replica scaleDownLimit := calculateScaleDownLimitWithBehaviors(args.CurrentReplicas, a.scaleDownEvents[args.Key], args.ScaleDownBehavior) if scaleDownLimit > args.CurrentReplicas { scaleDownLimit = args.CurrentReplicas } minimumAllowedReplicas := args.MinReplicas if minimumAllowedReplicas < scaleDownLimit { minimumAllowedReplicas = scaleDownLimit } else { } if args.DesiredReplicas < minimumAllowedReplicas { return minimumAllowedReplicas, possibleLimitingReason, possibleLimitingMessage } } return args.DesiredReplicas, "DesiredWithinRange", "the desired count is within the acceptable range" }
2.6.5 periodic events
Periodic events refer to all the change events corresponding to resources in a stable time window. For example, we finally decide that the expected replica is new replicas, and there are curRepicas, After the scale interface is updated, the number of changes will be recorded, i.e. newReplicas curreplicas. Finally, we can count the events in our stable window, and know whether we have expanded n pods or reduced N pods in this cycle. Then, the next time we calculate the expected replica, we can subtract the number of changes in this part Only add the part that is still missing after the current round of decision-making
func getReplicasChangePerPeriod(periodSeconds int32, scaleEvents []timestampedScaleEvent) int32 { // Computation cycle period := time.Second * time.Duration(periodSeconds) // Deadline cutoff := time.Now().Add(-period) var replicas int32 // Get recent changes for _, rec := range scaleEvents { if rec.timestamp.After(cutoff) { // There will be positive and negative changes in the number of updates and replicas. Finally, replicas is the number of recent changes replicas += rec.replicaChange } } return replicas }
3. Implementation summary
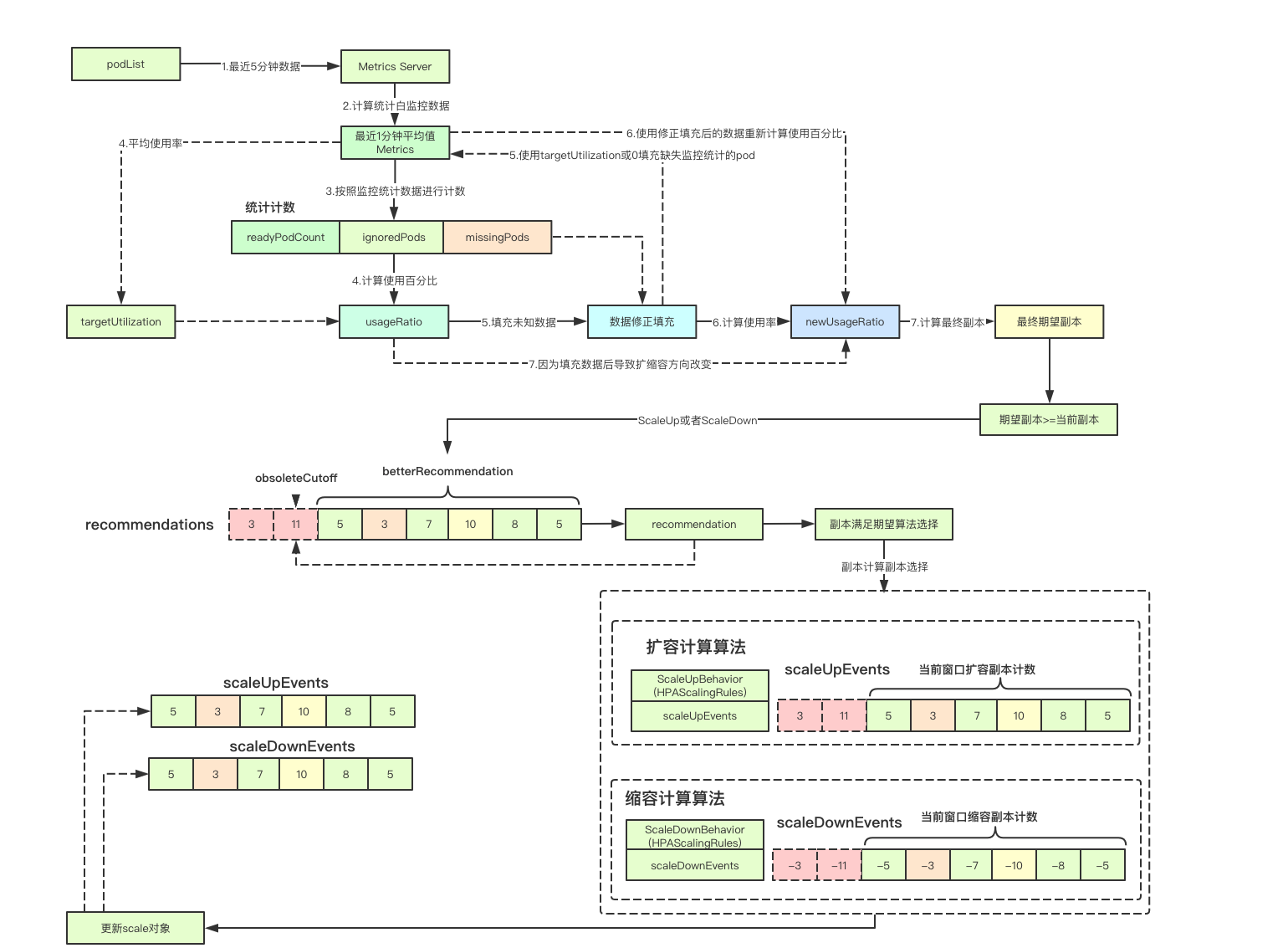
In the implementation of HPA controller, the most exciting part should be the utilization calculation part. How to fill in the unknown data according to different states and make a new decision (a design worth learning), Secondly, the final decision-making based on stability, change event and expansion strategy is relatively aggressive design, and the final user-oriented only needs a yaml to learn from the big guys
Reference
https://kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
kubernetes learning notes address: https://www.yuque.com/baxiaoshi/tyado3
Wechat: baxiaoshi2020  Pay attention to the bulletin number to read more source code analysis articles
Pay attention to the bulletin number to read more source code analysis articles  More articles www.sreguide.com
More articles www.sreguide.com