Introduction
Team practice, not very good, there are many places can be improved, such as the answer strategy, their own check-in unexpectedly wa issued, shame.
Points of knowledge involved
Graph Theory, Two-Dimensional Difference, Search, Segment Tree, Number Theory, dp, Greed
Links: ICPC Millet Network Selection Match 1, 2020
subject
A
Main idea: Given a sequence, select the most numbers so that the selected numbers are multiples of each other
Idea: The first is violence, assuming dp[i]For the maximum optional number when all the numbers currently selected are the approximate number of i, the multiple of I can be updated each time. This idea is stuck in time, and sometimes it is too old when submitting. However, the second idea is optimized by using a prime number on the basis of the first one. The first idea is actually updated repeatedly in many cases, such as 6 is the multiple of 2 and 3.Multiplication, but updated twice in the calculation of 2 and 3. Consider using the unique decomposition theorem to optimize. When I is the sum, I can be divided into multiple prime multipliers, I can reduce useless updates by using a strategy with fewer repetitions. In other words, aggregates can be assembled by several prime numbers, so there is no need to consider the combination when processing.Multiple i, because multiple I must be updated from product I of multiple prime numbers, so when updating dp, consider multiple I
Code (Violence)
#include <iostream>
#include <cstdlib>
#include <cstdio>
using namespace std;
typedef long long ll;
const int maxn=1e7+10;
int n,t,dp[maxn],ans,cnt[maxn];
int main() {
scanf("%d",&n);
for(int i=1; i<=n; i++) {
scanf("%d",&t);
cnt[t]++;
}
for(int i=1; i<=maxn-10; i++)
if(cnt[i]) {
dp[i]+=cnt[i];
for(int j=2*i; j<=maxn-10; j+=i)
dp[j]=max(dp[j],dp[i]);
ans=max(dp[i],ans);
}
printf("%d",ans);
return 0;
}
Code (dp with Prime optimization)
#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <cstring>
using namespace std;
typedef long long ll;
const int maxn=1e7+10;
bool IsPrime[maxn];//True value is a prime number
int Prime[maxn],ans,cnt[maxn],acc,n,t,dp[maxn],M;
void Choose(int n) { //Screen to n
memset(IsPrime,1,sizeof(IsPrime));//Initialization
//Assume that each number is a prime number
IsPrime[1]=IsPrime[0]=1;
for(int i=2; i<=n; i++) {
if(IsPrime[i])//If this number is not screened out, then add it to the prime sequence
Prime[++ans]=i;
for(int j=1; j<=ans&&i*Prime[j]<=n; j++) {
IsPrime[i*Prime[j]]=0;
if(!i%Prime[j])break;
}
}
}
int main() {
Choose(maxn);//Prime number sieve
scanf("%d",&n);
for(int i=1; i<=n; i++) {
scanf("%d",&t);
cnt[t]++;
M=max(M,t);//Get the maximum as the boundary
}
for(int i=1; i<=maxn-10; i++) {
dp[i]+=cnt[i];
for(int j=1; j<=ans&&Prime[j]*i<=M; j++) {//Similar prime number screening
int k=Prime[j]*i;
dp[k]=max(dp[k],dp[i]);
}
acc=max(acc,dp[i]);
}
printf("%d",acc);
return 0;
}
C
Headline: Check-in
Idea: Simulate it directly, notice that there is no w
Code
#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <cstring>
using namespace std;
typedef long long ll;
int main() {
char s[121212];
scanf("%s",s+1);
int len=strlen(s+1),ans=0,res=0;
for(int i=1; i<=len; i++) {
if(s[i]=='w')
res++;
else if(res) {
ans+=res*2-1;
res=0;
}
}
if(res)
ans+=2*res-1;
printf("%d",ans);
return 0;
}
D
Main idea of topic: Give a graph, do not guarantee connectivity, find the number of connected blocks after each point is deleted separately
Ideas: Here the dual connected components and their related definitions are given
Definition 1: In an undirected connected graph, if there is a set of vertices, delete the set of vertices and the edges associated with all vertices in the set, then the original graph becomes more than one connected block, which is called the set of cut points (the set of cut points)Similarly, if there is a set of edges, after deleting the set of edges, the original graph becomes more than one connected block, which is called the set of secant edges. The edge connectivity of a graph is defined as the minimum number of edges in the set of secant edges.
Definition 2:If the point/edge connectivity of an undirected connected graph is greater than 1, the graph is called point/edge dual connectivity, or double connectivity or re-connectivity. A graph has a cut point, and if and only if the point connectivity of the graph is 1, the only element of the set of cut points is called a cut point, also known as a joint point. A graph has a bridge, and if and only if the edge connectivity of the graph is 1, the only element of the set of cut edges isA connected undirected graph is doubly connected if and only if it has no joint points
Definition 3: In all subgraphs G'of graph G, if G' is double connected, then G'is called double connected subgraph. If a double connected subgraph G' is not a true subset of any double connected subgraph, then G'is a very large double connected subgraph. A double connected component or a reconnected component is a very large double connected subgraph of a graph, in particular, a point double connected component is also called a block.
Definition 4: If any two vertices of Directional Graph G are reachable to each other, then Graph G is strongly connected, otherwise it is not.
Definition 5: If the directional graph G is not a strongly connected graph, subgraph G'is a strongly connected graph, point v is a G', and any strongly connected subgraph containing V is a G' subgraph, then G'is called the extremely strongly connected subgraph of G, also known as the strongly connected component.
In fact, the meaning of the title is very clear, that is, after removing a point, it can be judged that there are several more strongly connected components.
Code
E
Main idea of the title: Give a sequence of length n with m queries. The number of queries increases from 1 to M. Ask for the first time to find out the length of the shortest interval [l,r] with 1 to i i n the original sequence.
Thought: This idea is really coincident, I don't think I can make it clear. If I can't read it, I can read the reference blog. If I can't understand it, I should be able to read it all together.
Firstly, since the number of questions is increasing, the number i of the current query can be used as a result of the number i-1 of the previous query. For solving the interval length, a basic idea is to fix the left endpoint, find the minimum right endpoint that meets the criteria, and set R i , j R_{i,j} Ri,j is the smallest right endpoint with j as the left endpoint when i is asked, and with i increasing, from R i , j − > R i + 1 , j R_{i,j}->R_{i+1,j} Ri,j >Ri+1, j, easy to get R i + 1 , j ≥ R i , j R{i+1,j}\ge R_{i,j} Ri+1,j≥Ri,j, R i + 1 , j R_{i+1,j} Ri+1,j may only change or jump to a greater than R i , j R_{i,j} i+1 position of Ri,j
Suppose t[i] is an interval [ i , t [ i ] ] [i,t[i]] [i,t[i]] includes the right endpoint of all values from 1 to i, and for specific i, the minimum length of the interval is t [ i ] − i + 1 t[i]-i+1 t[i]i+1, you can add a min record minimum interval length
If there is a value x in the range pos[i+1][j-1]~pos[i+1][j], as shown in the figure, so that the right endpoint of the pos[i+1][j] is in the interval, t[x] needs to be expanded to the position pos[i+1][j] for the new query i+1. Similarly, pos[i+1][j-1]The right endpoint of all values in the range +1~x needs to be expanded to pos[i+1][j], of course, if the original value of t[x] is greater than pos[i+1][j], i t does not need to be expanded
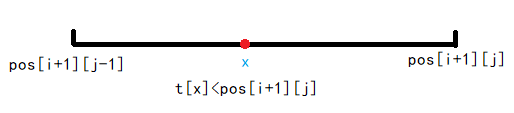
To maintain the above modifications and intervals, you need to use a segment tree. The segment tree nodes record the minimum of the right endpoint array within the corresponding interval, the minimum interval length that satisfies the criteria, and update the marker. When the interval length is 1, min is a single point value, and
[
l
,
r
]
[l,r]
t and in [l,r]
p
o
s
[
i
+
1
]
[
j
]
pos[i+1][j]
Find pos[i+1][j] from the segment tree before selecting it
[
l
,
r
]
[l,r]
[l,r] as shown in x, and then update the t-value in the pos[i+1][j-1]+1~x interval, assuming recursion to
[
l
′
,
r
′
]
[l',r']
[l′,r′],
l
′
≥
l
,
r
′
≤
x
l'\ge l,r' \le x
L'> l,r'= x, corresponding node is R t, minimum interval length is updated to pos[i+1][j-1]-r'+1, because the segment tree records the minimum length and the minimum right endpoint within the corresponding [l,r] interval of the t array, so in order to obtain the minimum interval length, only R (rightmost t[i]) needs to be subtracted.
Code
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int maxn=2e5+10;
const int INF = 0x3f3f3f3f;//This place must use positive infinity
int n,m,a[maxn];
vector<int>pos[maxn];
struct node {
int minn,lazy,val;
} seg[maxn<<2];
void pushup(int rt) {
seg[rt].val=min(seg[rt<<1].val,seg[rt<<1|1].val);
seg[rt].minn=min(seg[rt<<1].minn,seg[rt<<1|1].minn);
}
void pushdown(int rt,int l,int r) {
if(seg[rt].lazy) {
seg[rt<<1].lazy=seg[rt<<1|1].lazy=seg[rt].lazy;
int mid=(l+r)>>1;
seg[rt<<1].minn=seg[rt<<1|1].minn=seg[rt].lazy;
seg[rt<<1].val=seg[rt].lazy-mid+1;
seg[rt<<1|1].val=seg[rt].lazy-r+1;
seg[rt].lazy=0;
}
}
void update(int rt,int l,int r,int L,int R,int v) {
if(l>=L&&R>=r) {
seg[rt].lazy=seg[rt].minn=v;
seg[rt].val=v-r+1;
return ;
}
pushdown(rt,l,r);
int mid=(l+r)>>1;
if(mid>=L)update(rt<<1,l,mid,L,R,v);
if(R>mid)update(rt<<1|1,mid+1,r,L,R,v);
pushup(rt);
}
int query(int rt,int l,int r,int L,int R) {
if(seg[rt].minn>=R)return 0;
if(l==r)return l;
pushdown(rt,l,r);
int mid=(l+r)>>1,ans=0;
if(R>mid)ans=query(rt<<1|1,mid+1,r,L,R);
if(L<=mid&&!ans)ans=query(rt<<1,l,mid,L,R);
return ans;
}
int main() {
scanf("%d%d",&n,&m);
for(int i=1; i<=n; i++)//Input
scanf("%d",a+i);
for(int i=1; i<=m; ++i)pos[i].push_back(0);//Initialize, add initial 0 position
for(int i=1; i<=n; ++i)pos[a[i]].push_back(i);//Record where each number appears
//pos[i][j] is the jth position in the sequence where the number I appears
for(int i=1; i<=m; ++i) {//Number of queries
for(int j=1; j<pos[i].size(); j++) {
int p=query(1,1,n,pos[i][j-1],pos[i][j]);//Find locations that meet the criteria within an interval
if(p)update(1,1,n,pos[i][j-1]+1,p,pos[i][j]);//Update the rightmost value in the pos[i][j-1]+1~p interval to the next position of I
}
if(pos[i].back()<n)update(1,1,n,pos[i].back()+1,n,INF);
printf(i==m?"%d\n":"%d ",seg[1].val);
}
return 0;
}
F
Main idea of the title: There are k titles, one number per title a i a_i ai, now you need to construct a number of subject sets, each of which has a range of topics [ L , R ] [L,R] In [L,R], the number of occurrences of each topic in the title set must be [ l i , r i ] [l_i,r_i] Within [li, ri], find the maximum number of subject sets that can be formed (do not require the same number of subject sets)
Thought: Greed + Divide, first of all, you need to decide whether there is a conflict before the given number, and sum up the number s of all topics at least. If s > R, it means that it cannot be formed. Similarly, if the maximum number of occurrences is less than L, it cannot be formed either.
Since the maximum number of subject sets is to be constructed, the number of titles in each subject set should be as small as possible. Set the number of titles in the subject set to P, then P = m a x ( L , ∑ l i ) P=max(L,\sum l_i) P=max(L, li), which is easy to understand because the number of titles must be both greater than L less than R and greater than at least the number and
Ideally, a topic is a set of titles, that is, the sum of titles on the right boundary, and the number of dichotomous titles. Assuming the current dichotomy value is A, you can first determine if each topic can be divided into a set of titles, that is, the number of dichotomous titles. a i ≥ A × l i a_i\ge A×l_i ai < A * li satisfies or not, and then check if the number of titles per set can reach L to get A set of titles satisfies ∑ l i \sum l_i _li and A × L A×L The difference between the A *L values, that is, the requirement, to determine the number of topics that each topic can provide and whether it meets the requirement, and the number that each topic can provide m i n ( a i − A × l i , A × ( r i − l i ) ) min(a_i-A×l_i,A×(r_i-l_i)) min(ai A *li, A * (ri li)), the first topic in min has the number left after assigning A topic set, and the second is satisfying [ l i , r i ] [l_i,r_i] The number of [li, ri] provides the maximum quantity, since both conditions are met, the minimum value is chosen
Code
#include <bits/stdc++.h>
using namespace std;
typedef __int128 ll;
const int maxn=5e6+10;
ll k,L,R,a[maxn],l[maxn],r[maxn],suml,sumr,minn;
__int128 read() {
__int128 x=0,f=1;
char ch=getchar();
while(!isdigit(ch)&&ch!='-')ch=getchar();
if(ch=='-')f=-1;
while(isdigit(ch))x=x*10+ch-'0',ch=getchar();
return f*x;
}
void print(__int128 x) {
if(x<0)putchar('-'),x=-x;
if(x>9)print(x/10);
putchar(x%10+'0');
}
bool check(ll A) {
ll need=A*(L-suml),sum=0;//Get the number of topics to fill in
for(int i=1; i<=k; ++i)
if(a[i]<A*l[i])return 0;//If this value does not compose a set of A titles, it is not desirable
for(int i=1; i<=k; ++i)
sum+=min(a[i]-A*l[i],A*(r[i]-l[i]));//Get the amount that can be filled to determine if you can make up the difference
return sum>=need;
}
int main() {
k=read(),L=read(),R=read();
ll low=0,high=0,ans=0;
for(int i=1; i<=k; ++i) {
a[i]=read();
high+=a[i];//Record the sum as the right boundary
}
for(int i=1; i<=k; ++i) {
l[i]=read(),r[i]=read();
suml+=l[i], sumr+=r[i];//Record left and right boundaries and
}
if(suml>R||sumr<L) {//If the left boundary is larger than the right boundary of the title set, if the right boundary is smaller than the left boundary of the title set
puts("0");
return 0;
}
while(low<=high) {//Number of Binary Topic Sets
ll mid=(low+high)>>1;
if(check(mid))ans=mid,low=mid+1;//Determine if this number is sufficient
else high=mid-1;
}
print(ans);
return 0;
}
G
Headline: Give two sequences A , B A,B A,B, you need to build a rootless tree from these two sequences (any node can be the root), A is the possible topological order of the tree, B is the possible dfs order, to determine whether such a tree exists or not
Thought: The idea of this question is very clear. Use dfs order to construct a tree that satisfies the topological order or use the topological order to construct a tree that satisfies the dfs order. The solution uses the topological order to satisfy the dfs order. Here is a illustration
Five points are shown in the figure. The numbering of points is arranged from left to right according to the topological order. By default, these points are joined into a chain. The goal now is to change the connection relationship of some points so that the constructed tree satisfies the dfs order without changing the topological order. For tree construction, if you want to operate without changing the topological order, you need to connect the newly added nodes to the already constructed nodes.A set of edges constructed by
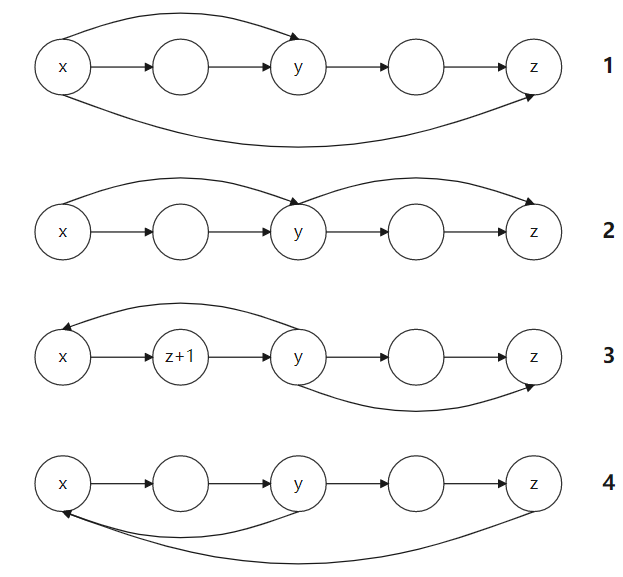
For the first chain, the direction of the arrow indicates the direction of the dfs order, then the set constructed after Z is x->y and x->z, and z+1 must have a solution whether between x,y or y,z (only for x,y,z,z+1)
For the second chain, the set constructed before Z insertion is y->x, and after Z insertion is x->y->z, so the solution of z+1 must exist
For the third chain, the set constructed before Z insertion is y->x, and the inserted Z has two choices. If Z chooses to connect with y, then the set becomes y->x,y->z. If z+1 is between X and y, in order to maintain dfs order, z+1 needs to follow z, but if z+1 is connected with z, the topological order will be destroyed, that is, there must be no solution in this case.
For the fourth chain, another option for the third chain is to select the node with the smallest topological order in the set to connect, so there must be a solution.
After the analysis, we can conclude that when inserting a new node into the set, if the node with the smallest topological order in the connected set is selected, there must be a solution; if the node with the smallest topological order in the connected set is selected, there must be no solution for connecting other nodes. The solution that can be obtained is required by the title, so the node with the smallest topological order in the set can be connected each time.
To understand this, the problem is solved by enumerating B arrays from left to right, finding the one with the smallest topological order in A for a B[i]
And one of the guys in the team O ( n log n ) O(n\log n) O(nlogn) algorithm, after understanding
Code
#include <bits/stdc++.h>
using namespace std;
typedef __int128 ll;
const int maxn=5e6+10;
int n,a[maxn],b[maxn],pos[maxn],cur;
int main() {
scanf("%d",&n);
for(int i=1; i<=n; i++) {
scanf("%d",a+i);
pos[a[i]]=i;
}
for(int i=1; i<=n; i++)
scanf("%d",b+i);
printf("YES\n");
cur=b[1];
for(int i=2; i<=n; i++) {
printf("%d %d\n",cur,b[i]);
if(pos[cur]>pos[b[i]])cur=b[i];//Gets the minimum value of the constructed set
}
return 0;
}
Reference
- All Questions in the First ICPC Millet Network Selection Competition in 2020
- The first E-question Phone Network of the 2020ICPC Millet Network Selection Competition
- First E-Phone Network (Think + Segment Tree) in the 2020 ICPC Millet Network Selection Competition
- acm - (segment tree, maximum and minimum interval) first E.Phone Network in the 2020 ICPC Millimeter Network Selection Competition
- G Tree Projection 2020 ICPC Millet Network Selection Game 1