This document is based on Python 2.7 and has changed in Python 3.
Basic crawling of web pages
get method
import urllib2 url = "http://www.baidu.com" response = urllib2.urlopen(url) print response.read()
post method
import urllib import urllib2 url = "http://abcde.com" form = {'name':'abc','password':'1234'} form_data = urllib.urlencode(form) request = urllib2.Request(url,form_data) response = urllib2.urlopen(request) print response.read()
Using proxy IP
In the process of crawler development, IP is often blocked, so proxy IP is needed.
There is a ProxyHandler class in the urllib2 package, through which you can set up a proxy to access the Web page, as follows:
import urllib2 proxy = urllib2.ProxyHandler({'http': '127.0.0.1:8087'}) opener = urllib2.build_opener(proxy) urllib2.install_opener(opener) response = urllib2.urlopen('http://www.baidu.com') print response.read()
Cookies processing
Cooks are the data stored on the user's local terminal (usually encrypted) by some websites in order to identify users and track session s. python provides a cookielib module to process cookies. The main function of the cookielib module is to provide objects that can store cookies, so that it can be used in conjunction with urllib2 module. Access Internet resources.
Code snippet:
import urllib2, cookielib cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar()) opener = urllib2.build_opener(cookie_support) urllib2.install_opener(opener) content = urllib2.urlopen('http://XXXX').read()
The key is CookieJar(), which manages HTTP cookie values, stores cookies generated by HTTP requests, and adds cookie objects to outgoing HTTP requests. The entire cookie is stored in memory, and after garbage collection of CookieJar instances, the cookie will also be lost, and all processes need not be operated separately.
Manual addition of cookie s
cookie = "PHPSESSID=91rurfqm2329bopnosfu4fvmu7; kmsign=55d2c12c9b1e3; KMUID=b6Ejc1XSwPq9o756AxnBAg=" request.add_header("Cookie", cookie)
Camouflage as a browser
Some websites are disgusted with the crawler's visits, so they refuse all requests to the crawler. So direct access to websites with urllib2 often results in HTTP Error 403: Forbidden
Pay special attention to some headers. Server will check these headers.
1.User-Agent Some Server s or Proxy check this value to determine whether it is a browser-initiated Request
2. When Content-Type uses the REST interface, the Server checks the value to determine how the content in the HTTP Body should be parsed.
This can be achieved by modifying the header in the http package. The code snippet is as follows:
import urllib2 headers = { 'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6' } request = urllib2.Request( url = 'http://my.oschina.net/jhao104/blog?catalog=3463517', headers = headers ) print urllib2.urlopen(request).read()
Form processing
It is necessary to fill in the form for login. How do you fill in the form? Firstly, the tool is used to intercept the contents of the form.
For example, I usually use the firefox+httpfox plug-in to see what packages I sent.
Let me give you an example. Take verycd as an example. First, find your own POST request and POST form items.
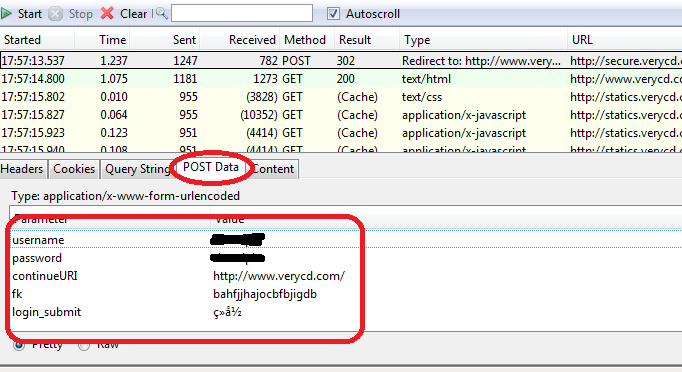
You can see that verycd needs to fill in username,password,continueURI,fk,login_submit, where FK is randomly generated (actually not very random, it looks like epoch time is generated by simple coding). It needs to be retrieved from the web page, that is to say, first visit the web page, intercept with regular expressions and other tools. Get the FK item in the returned data. ContinueURI, as its name implies, can be written casually, and login_submit is fixed, as can be seen from the source code. And username, password, that's obvious.
Okay, with the data to fill in, we're going to generate postdata
import urllib postdata=urllib.urlencode({ 'username':'XXXXX', 'password':'XXXXX', 'continueURI':'http://www.verycd.com/', 'fk':fk, 'login_submit':'Sign in' })
Then generate the http request and send the request:
req = urllib2.Request( url = 'http://secure.verycd.com/signin/*/http://www.verycd.com/', data = postdata ) result = urllib2.urlopen(req).read()
Page parsing
Regular expressions are of course the most powerful way to parse pages, which are different for different users of different websites, so it is not necessary to explain too much, with two better websites:
Introduction to Regular Expressions: http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
Regular expression online testing: http://tool.oschina.net/regex/
Next is the parsing library. There are two commonly used websites, lxml and Beautiful Soup.
lxml: http://my.oschina.net/jhao104/blog/639448
BeautifulSoup: http://cuiqingcai.com/1319.html
For these two libraries, my evaluation is that they are all HTML/XML processing libraries. Beautiful soup is implemented by python, which is inefficient, but has practical functions, such as obtaining the source code of an HTML node through result search; lxml is implemented in C language, which is efficient and supports Xpath.
6. Processing of Verification Code
For some simple verification codes, simple identification can be carried out. I have only done some simple verification code recognition. However, some anti-human authentication codes, such as 12306, can be manually coded through the code platform, of course, this is a fee.
7. gzip compression
Have you ever encountered some web pages, no matter how transcoding is a mess of code? Haha, that means you don't know that many web services have the ability to send compressed data, which can reduce the amount of data transmitted over the network line by more than 60%. This is especially true for XML web services, because the compression rate of XML data can be very high.
But the server will not send you compressed data unless you tell the server that you can process compressed data.
So you need to modify the code like this:
import urllib2, httplib request = urllib2.Request('http://xxxx.com') request.add_header('Accept-encoding', 'gzip') 1 opener = urllib2.build_opener() f = opener.open(request)
This is the key: create the Request object, add an Accept-encoding header to tell the server that you can accept gzip compressed data
Then it decompresses the data:
import StringIO import gzip compresseddata = f.read() compressedstream = StringIO.StringIO(compresseddata) gzipper = gzip.GzipFile(fileobj=compressedstream) print gzipper.read()
Multithread concurrent crawling
If a single thread is too slow, it needs multi-threading. Here we give a simple thread pool template. This program simply prints 1-10, but it can be seen that it is concurrent.
Although python's multi-threading is a chicken's rib, it can improve the efficiency to some extent for the crawler, which is a frequent type of network.
from threading import Thread from Queue import Queue from time import sleep #q is the task queue #NUM is the total number of concurrent threads #How many tasks does JOBS have? q = Queue() NUM = 2 JOBS = 10 #Specific processing functions that handle individual tasks def do_somthing_using(arguments): print arguments #This is the work process, which is responsible for continuously retrieving data from the queue and processing it. def working(): while True: arguments = q.get() do_somthing_using(arguments) sleep(1) q.task_done() #fork NUM threads waiting queue for i in range(NUM): t = Thread(target=working) t.setDaemon(True) t.start() #Queue JOBS for i in range(JOBS): q.put(i) #Waiting for all JOBS to complete q.join()
Learning about multithreading modules:
Anti-theft Chain
Some websites have so-called anti-theft chain settings. In fact, it's very simple to check whether the referer site in the header you sent the request is his own. So we just need to change the referer of the headers to the website. Take cnbeta as an example:
headers = { 'Referer':'http://www.cnbeta.com/articles' }
headers are a dict data structure, and you can put any header you want to make some camouflage. For example, some smart websites like to peep at people's privacy. Others visit them through proxy. They just want to read X-Forwarded-For in header to see people's real IP. Without saying anything, they can change X-Forwarded-For directly. They can change it to anything else.
The ultimate trick
Sometimes the access will still be accounted for, so there is no way, honestly write all the headers you see in httpfox, that's generally enough. No, that's the ultimate trick. selenium directly controls the browser to access it. As long as the browser can do it, it can do it. Similarly, there are pamie, watir, and so on.
Design a simple multithreaded grab class
Still feel more comfortable in the "native" python like urllib. Imagine if you had a Fetcher class, you could call it that way.
f = Fetcher(threads=10) #Set the number of download threads to 10 for url in urls: f.push(url) #Push all URLs into the download queue while f.taskleft(): #If there are still unfinished Downloads content = f.pop() #Remove the results from the download completion queue do_with(content) # Processing content
This multithreaded call is simple and straightforward, so let's design it like this. First of all, there are two queues. Queue is used to solve the problem. The basic architecture of multithreading is similar to "Skills Summary". push method and pop method are better handled. Both of them use Queue method directly, while taskleft is if there are "running tasks". Or "Tasks in the Queue" would be fine, so the code is as follows:
import urllib2 from threading import Thread,Lock from Queue import Queue import time class Fetcher: def __init__(self,threads): self.opener = urllib2.build_opener(urllib2.HTTPHandler) self.lock = Lock() #thread lock self.q_req = Queue() #Task queue self.q_ans = Queue() #Completion queue self.threads = threads for i in range(threads): t = Thread(target=self.threadget) t.setDaemon(True) t.start() self.running = 0 def __del__(self): #Deconstruction needs to wait for two queues to complete time.sleep(0.5) self.q_req.join() self.q_ans.join() def taskleft(self): return self.q_req.qsize()+self.q_ans.qsize()+self.running def push(self,req): self.q_req.put(req) def pop(self): return self.q_ans.get() def threadget(self): while True: req = self.q_req.get() with self.lock: #To ensure the atomicity of the operation, enter critical area self.running += 1 try: ans = self.opener.open(req).read() except Exception, what: ans = '' print what self.q_ans.put((req,ans)) with self.lock: self.running -= 1 self.q_req.task_done() time.sleep(0.1) # don't spam if __name__ == "__main__": links = [ 'http://www.verycd.com/topics/%d/'%i for i in range(5420,5430) ] f = Fetcher(threads=10) for url in links: f.push(url) while f.taskleft(): url,content = f.pop() print url,len(content)
Some trivial experiences
1. Connection pool:
Like urllib2.urlopen, opener.open creates a new http request. Usually this is not a problem, because in a linear environment, a second may generate a request; however, in a multithreaded environment, it can be tens of hundreds of requests per second, so in a few minutes, the normal and rational server will block you.
However, in normal html requests, it is normal to maintain dozens of connections with the server at the same time, so it is possible to maintain a pool of HttpConnection manually, and then select the connection from the pool to connect each time you grab it.
Here is a clever way to use squid as a proxy server for grabbing, squid will automatically maintain the connection pool for you, but also with data caching function, and squid is my server must be installed on the east, why bother to write the connection pool?
2. Setting the stack size of threads
The setting of stack size will significantly affect the memory usage of python. If Python multithreads do not set this value, the program will occupy a large amount of memory, which is very fatal for vps of openvz. stack_size must be greater than 32768, and in fact it should always be more than 32768*2
from threading import stack_size stack_size(32768*16)
3. Automatic Retry after Setting Failure
def get(self,req,retries=3): try: response = self.opener.open(req) data = response.read() except Exception , what: print what,req if retries>0: return self.get(req,retries-1) else: print 'GET Failed',req return '' return data
4. Setting timeout
import socket socket.setdefaulttimeout(10) #Connection timeout after setting 10 seconds
5. Landing
The login is simpler, first add cookie support to build_opener, refer to the "summary" article; if you want to login to VeryCD, add an empty method login to Fetcher and call it in init(), then inherit the Fetcher class and override the login method:
def login(self,username,password): import urllib data=urllib.urlencode({'username':username, 'password':password, 'continue':'http://www.verycd.com/', 'login_submit':u'Sign in'.encode('utf-8'), 'save_cookie':1,}) url = 'http://www.verycd.com/signin' self.opener.open(url,data).read()
So when Fetcher initializes, it automatically logs on to VeryCD.
Reference material:
http://www.pythonclub.org/python-network-application/observer-spider